TM重複のフィルタ
重複エントリを翻訳メモリから消去できます。
次のいずれかを実行すると、大量の重複が発生する可能性があります:
- 異なるコンテキストを使用して、多数の同一の翻訳を確定している
- 同じソースセグメントと同じコンテキストで複数の翻訳が可能な翻訳メモリを使用している
- コンテキスト情報なしで翻訳メモリを使用している
- TMXファイルを多数の同一ソースセグメントを持つ翻訳メモリにインポートしている
- 多くのテキスト以外のセグメント (数字だけのセグメント、またはダッシュなどで構成されたセグメント) を確定している
重複のフィルタウィンドウで、翻訳メモリの重複の検索を開始できます。これは、一度に1つの翻訳メモリで実行できます。
最終的に、エントリのグループになります。同じグループ内のエントリは、重複のフィルタウィンドウで設定した条件で、重複しているものです。
操作手順
- 翻訳メモリの編集を開始します。
-
翻訳メモリエディタリボンの重複を削除をクリックします。重複のフィルタウィンドウが表示されます。
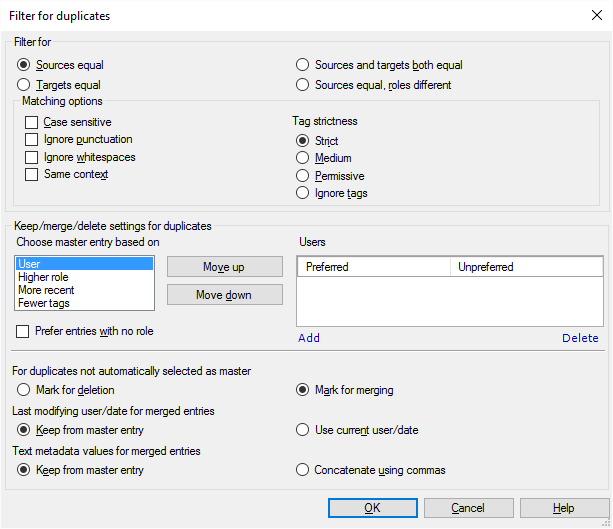
その他のオプション
ソーステキストが2つのエントリの両方で同じ場合、通常、2つのエントリは互いに重複しています。
- 次でフィルタリングでこれを微調整できます。選択できるラジオボタンがあります。
未編集の未承認の翻訳から翻訳メモリを整理するには:ソースが同じ、役割が異なる(R)をクリックします。これにより、同じセグメントが翻訳者およびレビュー担当者によって確定されたエントリが表示されます。その場合は、レビュー担当者によって確定されたものを保持したいでしょう。
- ソースが同じ(S):ソーステキストが両方で同じ場合、エントリは重複です。
- ターゲットが同じ(T):ターゲットテキストが両方で同じ場合、エントリは重複です。
- ソースとターゲット言語が両方同じ(B):ソースとターゲットテキストの両方が同じ場合、エントリは重複です。
- ソースが同じ、役割が異なる(R):ソーステキストが両方で同じですが、確定された役割が異なる場合、エントリは重複です。たとえば、1つは翻訳者によって確定され、もう1つはレビュー担当者 2によって確定されます。これを使用して、翻訳メモリ内の編集されていない翻訳を削除します。
- 次に、セグメントの比較方法を選択します。「同じ」と見なされるものを選択します。これに関してどの程度厳格にするか決めます。これを設定するには、一致オプションのチェックボックスとラジオボタンを使用します。通常、これらのチェックボックスはすべてオフになっています。つまり、単語、タグ、スペース、および句読点がまったく同じ場合、2つのセグメントは同じとなります。ソースセグメントのコンテキストと、小文字と大文字は異なる場合があります。
- 大文字と小文字を区別して、大文字と小文字も同じにするには:大文字と小文字を区別チェックボックスをオンにします。
- 句読点が異なっていても、2つのセグメントを同じものとして受け入れるには:句読点を無視チェックボックスをオンにします。
- スペースが異なっていても2つのセグメントを同一として受け入れるには:空白を無視(W)チェックボックスをオンにします。
- コンテキストが同じ場合にのみ、2つのソースセグメントを同一として受け入れるには:同じコンテキスト(X)チェックボックスをオンにします。
- 甘いは、タグの数だけが同じである必要があります。
- 標準は、タグは同じタイプ (開始/終了/空) でなければなりませんが、タグ名属性は異なる場合があります。
- 厳しいは、タグはまったく同じでなければなりません。最初はmemoQがこの設定を使います。
これは、重複の設定を保持/結合/削除で微調整できます。
重複エントリのグループでは、1つのエントリは常に「マスター」になります。グループ内の他のエントリをどうするかを決定できます:
- 削除する
- 追加の詳細をマスターエントリにマージする
- 重複が残るように保存する
翻訳メモリエディタに戻ったら、それぞれのグループを選択できます。
まず、memoQはどのエントリーがグループのマスターであるかを決定する必要があります。次に基づくマスターエントリを選択リストから、ユーザー、高度な役割、直近、より少ないタグのいずれかを選択します。たとえば、マスターエントリは、特定のユーザによって追加されたエントリです。通常、memoQは次のロジックに従います:
- マスターエントリは、優先ユーザからのエントリである。
- 優先ユーザーからのエントリがない場合:上位の役割で確定されたものを選択する。たとえば、レビュー担当者 2は翻訳者より高く、翻訳者は役割のないエントリより高くなります。実際には、役割のないエントリを最上位のエントリにすることができます:そのためには、役割のないエントリを優先(W)チェックボックスをオンにします。
- 最上位の役割を持つエントリが1つもない場合:最新のものを選択します。
- 同時に複数のエントリがある場合:ソースセグメントとターゲットセグメントのタグ数が少ない方を選択します。
これらの順序は変更できます。条件をクリックし、上へ移動または下へ移動ボタンをクリックします。
ユーザーリストには、優先ユーザーを表示できます。定期的にレビュー担当者 1またはレビュー担当者 2の役割でセグメントを確定する上級ユーザー (レビュー担当者) が該当します。優先ユーザーを追加するには、追加をクリックします。リストからユーザーを削除するには:ユーザーの名前をクリックします。削除(_R)をクリックします。
非優先ユーザーを追加することもできます。非優先ユーザのリストがある場合は、他のユーザが優先されます。たとえば、重複グループに非優先ユーザーからのエントリが4つあり、リストにないユーザーからのエントリが1つある場合、memoQはこの5番目のエントリをマスターエントリとして選択します。
次に、マスターエントリにマージされたエントリの処理を選択します。
ユーザー名が同じ文字で始まる場合は、これらのリストに複数のユーザーを追加できます。たとえば、すべての翻訳者がtr-jp1、tr-fr3、tr-de1などのユーザ名を持っている場合、それらすべてを非優先リストに追加できます。追加リンクをクリックします。優先/非優先ユーザーを追加 ウィンドウで これはユーザー名の接頭辞です チェックボックスを確認します。ユーザー名ボックスにtr-と入力し、OK(O)をクリックします。非優先列に「tr-*」という行が追加されました。つまり、ユーザー名が「tr-」で始まるすべてのユーザーが、非優先ユーザーとして扱われます。
- 自動的にマスターとして選択されていない重複:削除対象としてマークまたは結合対象としてマークをクリックします。通常、memoQはマスターエントリにマージするために非マスターエントリにマークを付けます。
重複するエントリが、同じセグメント、同じタグ、同じコンテキスト、同じフィールドで完全に同一であることが確実でない限り、削除対象としてマーク選択しないでください。それ以外の場合は、すべて結合対象としてマークを選択すべきです。そうしないと、翻訳メモリから情報が失われます。
- マージ済みエントリの最終更新ユーザー/最終更新日:変更日と最後に変更したユーザーをマスターエントリから取得するか、現在の編集セッションから取得するかを選択します。マスターエントリから保持または現在のユーザー/日付を使用をクリックします。非マスタ (マージ) エントリの日付とユーザを保持することはできません。
- マージ済みエントリのテキストメタデータ値:メタデータフィールドの内容がマスターエントリと非マスター (マージされたエントリ) で競合している場合は、何を行うかを選択します。マスターエントリの値を使用することも、すべての値をカンマで区切って使用することもできます。前者の場合は、マスターエントリから保持をクリックします。後者の場合は、カンマを使用して連結をクリックします。
完了したら
すべての重複を検索し、翻訳メモリエディタに戻るには:OK(O)をクリックします。
翻訳メモリエディタに戻り、重複を検索しないようにするには:キャンセル(C)をクリックします。
memoQは重複を検出すると、個々のエントリではなく重複のグループを含む特別なリストを表示します。
詳細については:翻訳メモリエディタについてのドキュメントを参照してください。