XML インポートルール
多言語XMLファイルをインポートするには、インポートルールが必要です。
多言語XMLファイルのエントリには、複数の言語で同じテキストが含まれています。インポートルールは、これらの言語のいずれかのテキストの場所をmemoQに指示します。
インポートルールでは、コンテキスト、コメント、およびその言語のテキストの長さ制限があるかどうかもmemoQに通知されます。実際には、言語ごとに1つのインポートルールが必要です。
インポートルールでは、XPath式を使用して、XMLファイル内のテキストまたはその他の情報の場所を指定します。ある意味で、XPathはXMLファイル内のエレメントの「座標」を記述します。
XML インポートルールウィンドウでは、XPath式を実際に認識したり作成したりせずに、インポートルールを設定できます。
操作手順
- 多言語XMLファイルのインポートを開始します。
- 文書のインポートオプションウィンドウでXMLファイルを選択し、フィルタと構成を変更をクリックします。
- 文書のインポート設定ウィンドウが表示されます。フィルタドロップダウンリストからマルチリンガル XML フィルタを選択します。
- インポートルールタブをクリックします。XMLインポートルールのリストが表示されます。下部で、インポートルールを編集(E)をクリックします。XML インポートルールウィンドウが表示されます。
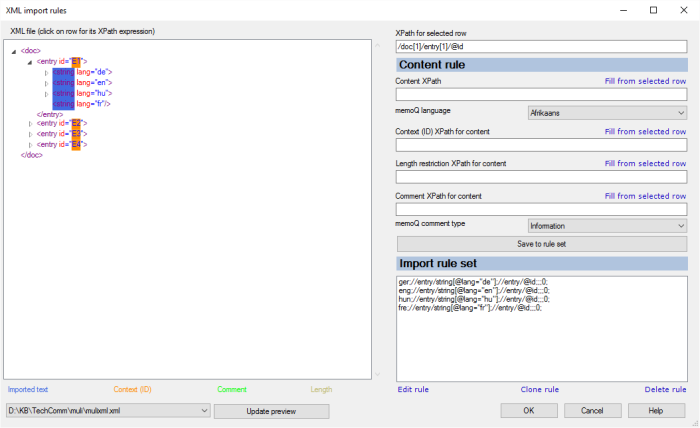
その他のオプション
プロジェクトの言語ごとに、またはドキュメントの言語ごとに1つのルールを設定します。
左側にインポートするXMLファイルのコンテンツが表示されます。通常は、これが最初の選択です。
XMLファイルがXMLツリーに表示されます。最初は最上位のエレメントのみが表示されます。左側の小さな矢印をクリックすると、エレメントを展開したり折りたたむことができます。
別のファイルをプレビューに使用するには:左下のドロップダウンボックスから別のファイルを選択します。プレビューを更新をクリックします。インポート用に最初に選択したファイルから選択できます。
まず、ソース言語のルールを設定します。左側のXMLツリーで、ソーステキストを含むタグをクリックします。タグをクリックしていることを確認します。テキスト自体やその属性をクリックしないでください。
選択行の XPathボックスで、その1つのタグを指すXPath式が表示されます。ドキュメント内で他にも同様の場所がある場合、このXPath式はそれらを無視します。
コンテンツの XPathボックスで選択行のものを使用をクリックします。XPath式がコンテンツの XPathボックスにも表示されます。
まだ終わっていません:このXPath式を編集して、同じようなエレメントをすべてのドキュメントから取り出す必要があります。次に、memoQ言語ドロップダウンボックスで、このエレメントの言語を選択します。
例:
ソース言語はドイツ語です。次の例では、'lang'属性が"de"である'文字列'タグをクリックします。
memoQは次のXPath式を挿入します:
これは「すべてのドイツ語の文字列」を意味するわけではありません。これは、最初のドキュメントの最初のエントリの最初の文字列エレメントを意味します。ルールをそのままにしておくと、インポートするドキュメントに類似したセグメントが何千もある場合でも、1つのセグメントだけがインポートされます。
これの代わりに、以下のようなXPathエレメントが必要になります:インポートするいずれかのドキュメントの、すべての特定の'entry'で、'lang'属性が"de"である文字列。どのドキュメントであってもかまいませんが、1つのセグメントにインポートされたテキスト部分が実際には同じ「エントリ」からのものであることを確認したいと思います。
コンテンツの XPathボックスで、XPath式を次のように編集します。
//entry/string[@lang="de"]
memoQ 言語ドロップダウンボックスからドイツ語を選択します。
コンテンツに加えて、コンテキスト、オプションの長さ制限、およびオプションのコメントをXML文書から選択できます。
少なくともコンテキストを選択することをお勧めします。
例:
サンプルファイルでは、エントリのコンテキストはエントリIDです。最初の'entry'タグの'id'属性をクリックします。コンテンツのコンテキスト (ID) XPathボックスで選択行のものを使用をクリックします。
memoQは次のXPath式を挿入します:
/doc[1]/entry[1]/@id
これは、最初のドキュメントの最初のエントリの'id'属性を意味します。代わりに、以下のようなXPathエレメントが必要になります:インポートするいずれかのドキュメントの、すべての'entry'で、'id'属性。どの文書であってもかまいませんが、1つのセグメントにインポートされるすべての日付が実際には同じ「エントリ」からのものであることを確認したいと思います。
コンテンツのコンテキスト (ID) XPathボックスで、XPath式を次のように編集します。
//entry/@id
必要に応じて (そしてそれらのデータが存在する場合は)、長さの制限とテキストのコメントに対して同様のルールを設定します。コメントのXPath式を挿入したら、memoQコメントタイプドロップダウンボックスを使用してコメントのタイプを選択します。
自動的に作成されたXPath式は、XML内の1つのエレメントまたは属性のみを指していることに注意してください。式を編集してより一般的なものにする必要があります。つまり、関連するすべてのエレメントまたは属性を選択する必要があります。例では、これがまさに私たちが行ったことです。
セグメントに含める各エレメントのXPath式を設定したら、ルールセットを保存をクリックします。
この時点で、他の言語のルールも追加する必要があります。上記の手順を繰り返します。
この例では、英語の文字列を取得するXPath式は次です://entry/string[@lang="en"]
ドイツ語テキストのすべてを設定してルールセットを保存をクリックすると、XPath式とその他の設定がXML インポートルールウィンドウに残ります。
この例では、英語テキスト用のルールを追加するために、コンテンツの XPathボックスを編集して、//entry/string[@lang="en"]を含めます。もう一度ルールセットを保存をクリックします。
新しいルールを追加せずに既存のルールを変更するには:下部 (ルールセットをインポートリスト内) のルールをクリックします。ルールの詳細が上部のテキストボックスに表示されます。そのルールを変更するには、下のルールを編集をクリックします。次に、XPath式を編集し、必要に応じて設定を変更します。ルールセットを保存をクリックすると、既存のルールが更新されます。
XPath式と設定を変更しただけで、ルールを編集クリックしなかった場合、ルールセットを保存ボタンによって新しいルールが追加されます。
memoQでは、現在のルールで選択されているすべてのエレメントがハイライトされます:インポートルールをクリックすると、そのルールによって選択されたXMLツリー内のすべてのエレメントがハイライト表示されます。これらは色分けされています:XML インポートルールウィンドウ下部の凡例を参照してください。ルールをクリックしたときに、関連するすべてのエレメントがハイライト表示されているかどうかを確認します。必要に応じて、ドキュメント内の複数のエントリを展開します。
完了したら
ルールを保存して文書のインポート設定ウィンドウに戻るには:OK(O)をクリックします。
ルールを破棄し、新規ルールなしで文書のインポート設定ウィンドウに戻るには:キャンセル(C)をクリックします。