XML-Importregeln
Zum Importieren einer mehrsprachigen XML-Datei sind Importregeln erforderlich.
Ein Eintrag in einer mehrsprachigen XML-Datei enthält den gleichen Text in mehreren Sprachen. Eine Importregel gibt in memoQ an, wo der Text für eine dieser Sprachen zu finden ist.
Die Importregel gibt zudem an, ob ein Kontext, ein Kommentar und möglicherweise eine Längenbegrenzung für den Text in dieser Sprache vorhanden ist. Praktisch ist eine Importregel für jede Sprache erforderlich.
In einer Importregel wird mithilfe von XPath-Ausdrücken auf die Position des Texts oder auf andere Informationen in einer XML-Datei verwiesen. In gewisser Hinsicht beschreibt XPath die "Koordinaten" eines Elements in einer XML-Datei.
Im Fenster XML-Importregeln können Sie Importregeln einrichten, ohne XPath-Ausdrücke zu kennen oder anzugeben.
Navigation
- Importieren Sie eine mehrsprachige XML-Datei.
- Wählen Sie im Fenster Dokument-Importoptionen die XML-Dateien aus, und klicken Sie auf Filter und Konfiguration ändern.
- Das Fenster Einstellungen für Dokumentenimport wird angezeigt. Wählen Sie in der Dropdown-Liste Filter die Option Filter für mehrsprachige XML-Dateien aus.
- Klicken Sie auf die Registerkarte Importregeln. Die Liste der XML-Importregeln wird angezeigt. Klicken Sie unten auf Importregeln bearbeiten. Das Fenster XML-Importregeln wird angezeigt.
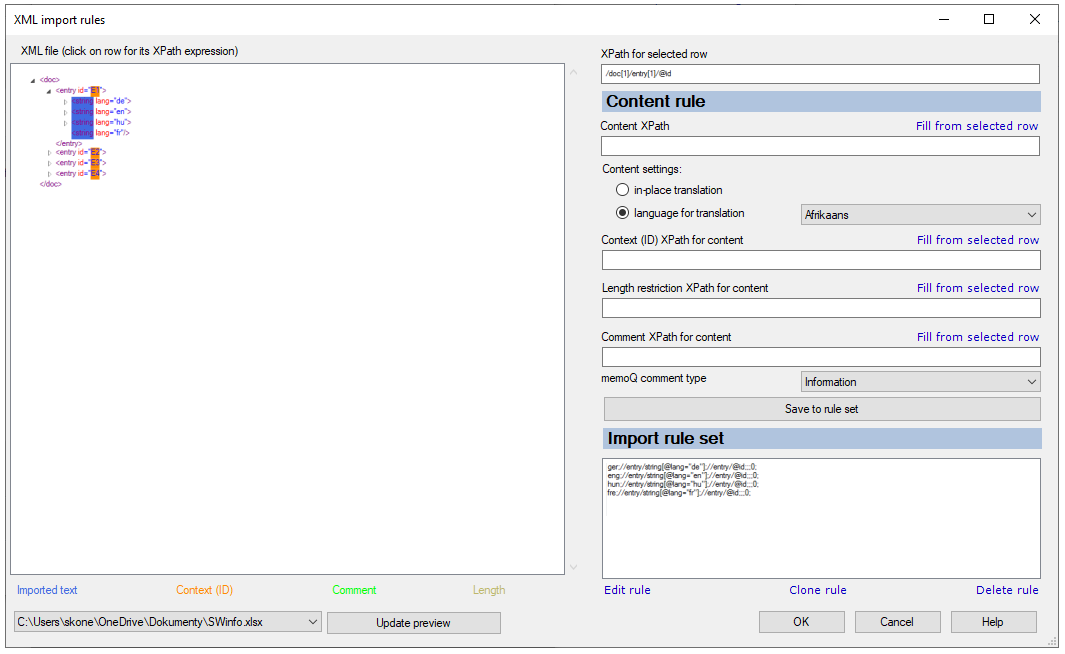
Möglichkeiten
Sie können eine Regel für jede Sprache im Projekt einrichten – oder für jede Sprache im Dokument.
Links wird in memoQ der Inhalt einer der importierten XML-Dateien angezeigt. Normalerweise ist dies die erste Datei in der Auswahl.
Die XML-Datei wird mit einer XML-Struktur angezeigt. Zunächst wird nur das oberste Element angezeigt. Sie können Elemente ein- und ausblenden, indem Sie links auf die kleinen Pfeilsymbole klicken.
Verwenden einer anderen Datei für die Vorschau: Wählen Sie in der Dropdown-Liste unten links eine andere Datei aus. Klicken Sie dann auf "Vorschau aktualisieren". Sie können eine der Dateien auswählen, die Sie ursprünglich für den Import markiert haben.
Richten Sie als Erstes die Regel für die Ausgangssprache ein. Klicken Sie in der XML-Struktur links auf das Tag, das den Ausgangstext enthält. Stellen Sie sicher, dass Sie auf das Tag klicken. Klicken Sie nicht auf den Text oder auf eines der zugehörigen Attribute.
Im Feld XPath für ausgewählte Zeile wird der XPath-Ausdruck angezeigt, der auf dieses eine Tag verweist. Auch wenn es weitere ähnliche Stellen im Dokument gibt, werden sie von diesem XPath-Ausdruck dennoch ignoriert.
Klicken Sie bei dem Feld XPath-Inhalt auf Von ausgewählter Zeile auffüllen. Der XPath-Ausdruck wird auch im Feld XPath-Inhalt angezeigt.
Sie sind noch nicht fertig: Sie müssen diesen XPath-Ausdruck so bearbeiten, dass alle ähnlichen Elemente aus dem Dokument aufgenommen werden. Wählen Sie dann in der Dropdown-Liste "memoQ-Sprache" die Sprache für das Element aus.
Beispiel:
Die Ausgangssprache ist Deutsch. Klicken Sie im Beispiel unten auf das 'string'-Tag, bei dem das 'lang'-Attribut auf "de" festgelegt ist.
Der folgende XPath-Ausdruck wird eingefügt:
Er bedeutet nicht "alle deutschen Zeichenfolgen". Er gibt das erste "string"-Element aus dem ersten Eintrag des ersten Dokuments an. Wenn Sie die Regel so belassen, wird genau ein Segment importiert, auch wenn Tausende ähnlicher Segmente in den importierten Dokumenten vorhanden sind.
Stattdessen benötigen Sie einen XPath-Ausdruck, der alle Zeichenfolgen, bei denen das 'lang'-Attribut auf "de" festgelegt ist, aus jedem spezifischen 'entry'-Element aus jedem Dokument des Imports angibt. Das jeweilige Dokument spielt keine Rolle, es soll aber sichergestellt werden, dass die in einem Segment importierten Textteile aus demselben "entry"-Element stammen.
Bearbeiten Sie den XPath-Ausdruck im Feld XPath-Inhalt wie folgt:
//entry/string[@lang="de"]
Wählen Sie in der Dropdown-Liste memoQ-Sprache die Option Deutsch aus.
Neben dem Inhalt kann der Kontext, eine optionale Längenbeschränkung und ein optionaler Kommentar aus dem XML-Dokument aufgenommen werden.
Es wird empfohlen, dass mindestens der Kontext aufgenommen wird.
Beispiel:
In der Beispieldatei ist die Eintrags-ID der Kontext für einen Eintrag. Klicken Sie auf das 'ID'-Attribut des ersten 'entry'-Tags. Klicken Sie bei dem Feld XPath-Kontext (ID) für Inhalt auf Von ausgewählter Zeile auffüllen.
Der folgende XPath-Ausdruck wird eingefügt:
/doc[1]/entry[1]/@id
Er gibt das 'ID'-Attribut des ersten Eintrags aus dem ersten Dokument an. Stattdessen benötigen Sie einen XPath-Ausdruck, der das 'ID'-Attribut aus jedem 'entry'-Element aus jedem Dokument des Imports angibt. Das jeweilige Dokument spielt keine Rolle, es soll aber sichergestellt werden, dass alle in einem Segment importierten Daten aus demselben "entry"-Element stammen.
Bearbeiten Sie den XPath-Ausdruck im Feld XPath-Kontext (ID) für Inhalt wie folgt:
//entry/@id
Bei Bedarf – und sofern die entsprechenden Daten vorhanden sind – können Sie ähnliche Regeln für die Längenbeschränkung und den Kommentar für den Text einrichten. Wählen Sie nach dem Einfügen des XPath-Ausdrucks für den Kommentar in der Dropdown-Liste "memoQ-Kommentartyp" den gewünschten Kommentartyp aus.
Denken Sie daran, dass ein automatisch erstellter XPath-Ausdruck auf nur ein Element oder Attribut in der XML-Datei verweist. Sie müssen den Ausdruck so bearbeiten, dass er allgemeiner definiert ist und alle relevanten Elemente oder Attribute aufgenommen werden. Im Beispiel wurde genau dies durchgeführt.
Nachdem Sie einen XPath-Ausdruck für jedes Element eingerichtet haben, das im Segment enthalten sein soll, klicken Sie auf Im Regelsatz speichern.
Nun müssen Sie auch Regeln für die anderen Sprachen hinzufügen. Wiederholen Sie dazu die oben beschriebenen Schritte.
Im Beispiel ist //entry/string[@lang="en"] der XPath-Ausdruck zum Aufnehmen der englischen Zeichenfolgen.
Nachdem Sie alles für den deutschen Text eingerichtet und auf Im Regelsatz speichern geklickt haben, verbleiben die XPath-Ausdrücke und die anderen Einstellungen im Fenster XML-Importregeln.
Um im Beispiel die Regel für den englischen Text hinzuzufügen, bearbeiten Sie das Feld XPath-Inhalt einfach so, dass es //entry/string[@lang="en"] enthält. Klicken Sie dann erneut auf Im Regelsatz speichern.
So ändern Sie eine vorhandene Regel, anstatt eine neue hinzuzufügen: Klicken Sie auf die Regel unten (in der Liste Regelsatz für Import). Die Details der Regel werden oben in den Textfeldern angezeigt. Um Änderungen an dieser Regel vorzunehmen, klicken Sie unten auf Regel bearbeiten. Bearbeiten Sie dann die XPath-Ausdrücke, und ändern Sie die Einstellungen nach Bedarf. Wenn Sie auf Im Regelsatz speichern klicken, wird die vorhandene Regel aktualisiert.
Wenn Sie nur die XPath-Ausdrücke und die Einstellungen verändern, ohne auf Regel bearbeiten zu klicken, wird mit Klick auf die Schaltfläche Im Regelsatz speichern eine neue Regel hinzugefügt.
In memoQ werden alle Elemente hervorgehoben, die mit der aktuellen Regel aufgenommen werden: Wenn Sie auf eine Importregel klicken, werden alle Elemente in der XML-Struktur hervorgehoben, die mit der Regel aufgenommen werden. Die Hervorhebung ist farbcodiert: siehe die Legende unten im Fenster XML-Importregeln. Klicken Sie auf eine Regel, und überprüfen Sie, ob alle relevanten Elemente hervorgehoben sind. Blenden Sie gegebenenfalls mehrere Einträge im Dokument ein.
Abschließende Schritte
So speichern Sie die Regeln und kehren zum Fenster Einstellungen für Dokumentenimport zurück: Klicken Sie auf OK.
So verwerfen Sie die Regeln und kehren zum Fenster Einstellungen für Dokumentenimport zurück, ohne dass neue Regeln hinzugefügt werden: Klicken Sie auf Abbrechen.