XML (eXtensible Markup Language) ファイル
XMLは世界で最も用途の広いデータフォーマットであり、私たちが書きたいほとんどすべてをエンコードできるマークアップのようなものを定義しています。
XMLファイルには、テキスト、構造化データ、さらにはプログラムコードさえも保存することができ、人間や機械が完全に読み取ることができます。
次のようなものはすべてXMLです:
<thing>
<part-of-thing looks="good">
Here is the part of thing
</part-of-thing>
</thing>
<thing>...</thing>のように囲まれた部分をエレメントと呼びます。
エンコードを行う部分 (<thing>、</thing>、<part-of-thing>など) はタグと呼ばれます。上の<thing>は開始タグで、下の</thing>は終了タグです。内部に何もないエレメントもあります。これらは<emptiness></emptiness>と書くこともできますが、XMLは<emptiness/>と書くことでこれを単純化します。それは空タグといいます。
エレメントを開始するタグの内部には、エレメントがどのようなものであるかを記述する部分があります。これらは属性と呼ばれます。例では、looks="good"は属性です。属性には名前 (looks) と値 ("good") があります。
問題があります:XMLでは、テキストとマークアップが混在しています。マークアップでは、2つの文字が非常に特殊です:<と>です。エレメント内のテキストにこれらの文字を含めることはできません。代わりに、XMLは<に対して< (小なり)、>に対して> (大なり) と書き込みを行います。
&(シンボル);のように見えるXMLテキスト内のすべての文字は、1つの文字を表します。これらはキャラクタエンティティまたは単にエンティティと呼ばれます。そして、アンパサンド (&) 文字も特別です。したがって、テキストに実際のアンパサンドを記述する場合は、&というエンティティを記述する必要があります。
特定のタイプのドキュメントまたはデータをXMLで記述する場合、使用するエレメント、タグ、属性、およびエンティティを決定する必要があります。XMLに基づいた特定の文書形式に移行した場合、それは、明確に定義された構造内の明確に定義されたタグのセットを選択したことを意味します。HTMLはその一例です。HTMLですべてのタグを使用するだけではだめです - それぞれのタグは使用できる場所のルールがあります。HTMLルールには知られていない別のタグを使用すると、ドキュメントが無効になります。
XMLドキュメントのタイプで使用できるタグと属性を記述するルールは、文書型定義と呼ばれます。ドキュメントのタイプを記述する個別のファイルがあります。文書型定義ファイル (DTD) またはXMLスキーマのいずれかです。
HTML、Word文書 (少なくともDOCX)、XLIFF、TMXファイル (翻訳メモリのコンテンツ) など、多くのよく知られたドキュメントタイプはXMLです。
XMLタイプに応じて、memoQは各ファイルを異なる方法で処理し、そのファイルに特化したフィルタを提案します。たとえば、Word文書をインポートすると、memoQはXMLの代わりにMicrosoft Wordフィルタの1つを使用するように提案します。しかし、インポートされた文書の大部分を読み取るためにXMLフィルターを使用します。
多くのオーサリングおよびデータベースシステムでは、コンテンツをXMLファイルに保存またはエクスポートします。memoQで翻訳する場合は、このXMLフィルタを使用してインポートします。
マルチリンガル XML ファイル:複数の言語で同じテキストを含むXMLファイルがあります。これらのファイルをインポートするには、マルチリンガル XML フィルタを使用します。
操作手順
- XMLファイルのインポートを開始します。
- 文書のインポートオプションウィンドウでXMLファイルを選択し、フィルタと構成を変更をクリックします。
- 文書のインポート設定ウィンドウが表示されます。フィルタドロップダウンから、XML フィルタを選択します。
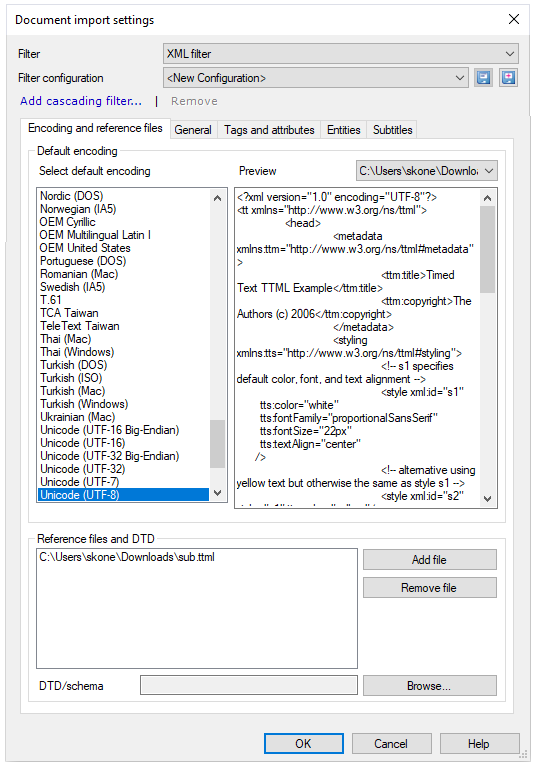
XML構成は複雑であり、それらを保存する価値があります:インポートを正しく準備するには数時間かかる場合があります。設定の準備ができたら、フィルタ構成ドロップダウンの横にある新規フィルタ構成として保存 ![]() ボタンをクリックします。次回、同じソースからXMLファイルをインポートする必要がある場合は、同じフィルタ構成ドロップダウンから保存済みの設定を選択できます。
ボタンをクリックします。次回、同じソースからXMLファイルをインポートする必要がある場合は、同じフィルタ構成ドロップダウンから保存済みの設定を選択できます。
その他のオプション
XMLファイルを正しくインポートするには、多くの設定が必要です。このトピックでは、次の例を使用して説明します:
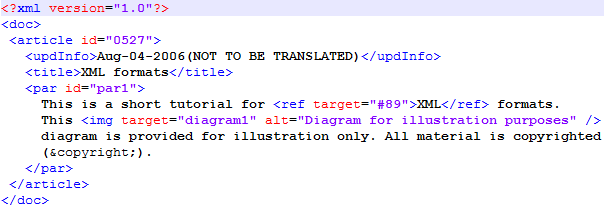
上記の例では、他のXML文書と同様に、説明や構造情報を保持する<doc>のようなタグの次に、翻訳が必要な「通常の」テキストが含まれています。タグは、値 (id="0527") を持つ属性を持つことができます。
これらがmemoQでどのように解釈されるかを下のセクションで説明します。
このエンコーディングはプレビューファイルとリファレンスファイルのみに適用されます:一般タブで実際のインポートおよびエクスポートエンコーディングを設定する必要があります。
通常、XMLファイルのヘッダーにはエンコーディングが記述されています。欠落している場合、memoQはUTF-8エンコーディングを使用します。プレビューボックスで、すべてが正しく表示されていることを確認します。そうでない場合は、既定のエンコード方法(E)リストから別のエンコーディングを選択します。
memoQは、文書型定義 (DTD) またはXMLスキーマ (XSD) を使用して、XML文書内に存在できるタグと属性を判断できます。DTDファイルまたはXMLスキーマがない場合、memoQは1つまたは複数の参照ファイルを読み取り、タグと属性を検出します。
通常、memoQは、インポートするすべてのドキュメントを参照ファイルとして自動的に追加します。さらにファイルを追加するには:参照ファイルとDTDフィールドの横にあるファイルの追加ボタンをクリックします。
スキーマまたはDTDがある場合は、常にスキーマまたはDTDを使用します:DTD/スキーマテキストボックスの横にある参照をクリックし、DTDまたはXSDファイルを探します。
DTDまたはXMLスキーマがある場合、memoQは自動的にフィルタ構成を選択できます:一般タブをクリックし、DTDまたは名前空間URL(U)フィールドにDTDファイルの名前を入力します。しかし、スキーマがある場合、XSDファイルには名前空間へのアドレスが含まれます。ファイルからDTDまたは名前空間URL(U)フィールドにコピーします。フィルタ構成が保存されていることを確認します。次に同じDTDまたはスキーマを使用するXMLファイルをインポートすると、同じ構成がDTDまたはスキーマに関連付けられているため、memoQは自動的にその設定を読み込みます。
通常、XMLファイルのヘッダーにはエンコーディングが記述されています。欠落している場合、memoQはUTF-8エンコーディングを使用します。
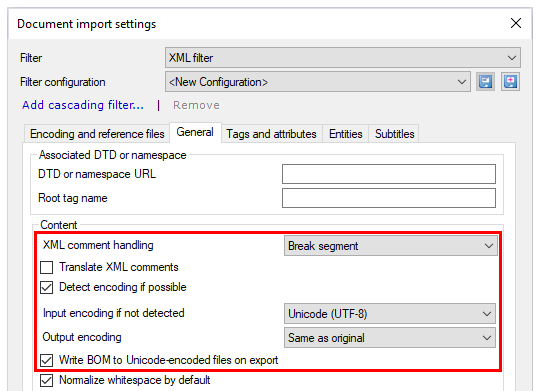
これを変更する必要がある場合は、一般タブをクリックし、コンテンツセクションの設定を使用します。
-
memoQがエンコーディングを正しく検出できなかった場合:可能であればエンコードを検出(D)チェックボックスをオフにします。検出されない場合の入力用エンコード(I)ドロップダウンから必要なエンコーディングを選択します。エンコードと参照ファイルタブのプレビューボックスでエンコーディングを確認することもできます。
-
入力エンコーディングがUnicodeではなく、ソースとターゲット言語の書き込みが異なる場合:出力用エンコード(O)ドロップダウンから、翻訳をエクスポートするときに使用するエンコーディングを選択します。通常、memoQはソースドキュメントと同じエンコーディングを使用しますが、入力エンコーディングがユニコードの形式 (UTF-8など) であれば完全に正常です。
-
通常、memoQは、ファイルの先頭にバイトオーダーマークが付いたXMLファイルをエクスポートします。一部のコンテンツ管理システムでは、これが必要です。エクスポート時に Unicode でエンコードされたファイルに BOM を書き込む(W)チェックボックスをオフにしないでください。
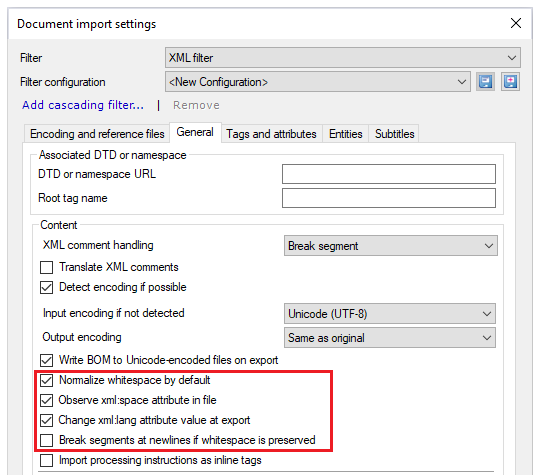
これらの設定は、memoQがテキスト内の空白文字を処理する方法を制御します:
-
既定で空白を標準化:通常、memoQはタブ、スペース、または改行文字のシーケンスを1つのスペース文字に変換し、エレメントの先頭と末尾の空白シーケンスをトリミングします。これは、XML文書が読みやすさを向上させるために空白文字のみを使用する場合に使用します。
フォーマットまたは構造に空白文字が必要な場合は、既定で空白を標準化チェックボックスをオフにします。
サンプル文書では、<par>エレメント内のテキストには重要な情報を保持しない改行とスペースが含まれています。これらは文書を人間が読みやすくするためだけのものです。しかし、これらの空白文字は、翻訳中に扱いにくい場合があります。したがって、この場合は空白の正規化をオンのままにしておきます。
memoQはタグ内のスペースは保持しません:既定で空白を標準化をオフにしても、タグ内の余分なスペースは削除されます。たとえば、ソースドキュメントに<br />が含まれている場合、memoQは常にスペースなしで<br/>をエクスポートします。
-
ファイル内の xml:space 属性に従う(S):XMLドキュメントには、特定のエレメントで空白を標準化すべきかどうかを指示する属性が含まれていることがあります。通常、memoQはドキュメントのこの指示に従います。ドキュメント全体で空白を同じように扱う必要がある場合は、このチェックボックスをオフにします。
-
エクスポート時にxml:lang属性値を変更(A):通常、memoQはxml:lang属性値を実際のターゲット言語のISOコードで上書きします。この属性の元の値を保持する必要がある場合は、このチェックボックスをオフにします。
-
空白を保持する場合に改行でセグメントを区切る:すべての改行文字で新しいセグメントを開始する場合は、このチェックボックスをオンにします。XMLファイルからインポートされたテキストに改行文字が含まれるのは、空白を保持することを選択した場合、つまり、既定で空白を標準化チェックボックスがオフになっている場合、またはxml:space属性でそのように指定されている場合だけです。空白文字が保存される場合、改行文字はテキスト内で意味を持つと考えられ、ほとんどの場合、各行は別々のセグメントとして翻訳される必要があります。
既定で空白を標準化チェックボックスをオフにする場合は、空白を保持する場合に改行でセグメントを区切るチェックボックスをオンにする必要があります。
一部のXMLファイルでは、コメントも翻訳する必要があります。通常、memoQではインポートしません。
これを変更する必要がある場合は、一般タブをクリックします。
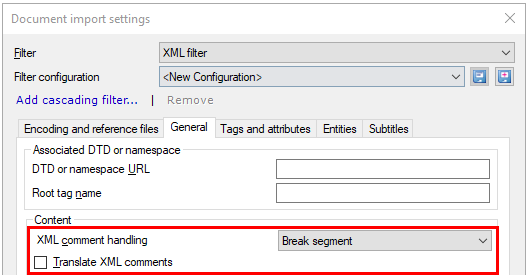
翻訳用にXMLコメントをインポートするには:XMLコメントを翻訳(T)チェックボックスをオンにします。
通常、memoQはコメントがあるたびにセグメントを分割します。コメントを翻訳する必要がある場合、memoQはプロジェクトのセグメンテーションルールを使用して、コメントをテキスト内の位置にある別のセグメントにインポートします。
XMLコメントをインラインタグとしてインポートするには:XMLコメントの処理(C)ドロップダウンボックスからImport as <mq:cmt> tagを選択します。memoQはコメントを特別なインラインタグ (mq:cmt) に変換します。コメントを翻訳する必要がある場合は、mq:cmtインラインタグの翻訳対象属性になります。タグと属性タブで、これらの属性を翻訳可能としてマークします。コメントのテキストはセグメント化されません。
従来のmemoQ {tag} は使用しません:XMLコメントの処理ドロップダウンで、memoQ {tag}としてインポートを選択しないでください。
64文字のプレビュー (コメントが翻訳されていない場合):翻訳用のコメントをインポートしない場合、翻訳エディタはフィルタされた長いタグビューで最初の64文字をプレビューとして表示します。コメントの全テキストはXMLファイルのスケルトンとともに保存されるため、コメントは翻訳後のファイルにエクスポートすることができます。
通常、memoQでは、XML文書の標準プレビューが表示され、すべてのタグとドキュメントの構造が示されます。
しかし、XMLドキュメントがフォーマットされたテキストを表す場合、より良いフォーマットのプレビューを得ることができます。
通常、XMLは実際のフォーマットについては何も述べません。この情報は、外部から追加する必要があります。そのためには、XMLスタイルシートまたはXMLスタイルシートテンプレート (XSLT) が必要です。
XSLTは、XMLファイルを表示できるものに変換します。たとえば、XMLをXSLTを使用してHTMLに変換すると、Webブラウザーで表示できます。memoQは、XMLファイルをHTMLに変換するXSLTファイルを受け付けますが、このファイルを用意しておく必要があります。memoQはそのようなファイルを作成しません。
XSLTファイルの作成方法については、w3schoolsページの「XSLT入門」を参照してください。

XSLTファイルを用意したら、XSLTファイル(F)フィールドの横にある 参照  ボタンをクリックします。
ボタンをクリックします。
XSLTはHTMLを生成する必要があります:XMLスタイルシートはHTMLアウトプットを作成する必要があります。スタイルシートが異なる形式 (プレーンテキスト、RTF、またはその他のXML) を出力する場合、ここでは使用できません。
XSLTファイルを参照し、ダブルクリックします。XSL 変換するファイルを選択ウィンドウが開き、XSLTファイルの場所にあるファイルとサブフォルダが表示されます。チェックボックスを使用して、プレビューの作成に必要な各ファイルを選択します。
XSLTプレビューを変更するには:XSLTの割り当てを削除(V)をクリックします。次に、必要に応じて別のXSLTファイルを指定します。
これには、一般タブの下部にある設定を使用します:
-
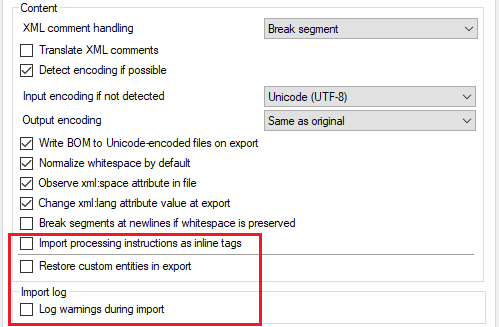
XMLファイルには処理命令が含まれている場合があります。タグのように見えますが、最初の文字は<?です。これらは、ファイルを格納するコンテンツ管理システム、またはファイルを表示するプログラムによって使用されます。通常、memoQでは未解釈の書式タグとして表示されます。これはお勧めできません。代わりに、これらの処理命令をインラインタグとしてインポートし、mq:piタグとして表示するには:処理手順をインラインタグとしてインポートチェックボックスをオンにします。
-
ドキュメントには、カスタムエンティティ (XML標準では定義されていませんが、ファイルを保存するコンテンツ管理システムやファイルを表示するプログラムで使用される文字) を含めることができます。
通常、memoQではエンティティコード (&(エンティティ名);) ではなく文字として表示およびエクスポートします。たとえば、元のファイルの©right;は、memoQでは©になります。
翻訳のエクスポート時にこれらの文字のエンティティコードを復元するには:エクスポートでカスタムエンティティを復元(R)チェックボックスをオンにします。この場合、ターゲットテキストの©は、エクスポートされたファイルで©right;になります。このチェックボックスをオンにしない場合、エクスポートされたドキュメントにも©が含まれます。
-
XMLファイルが技術的に正しくない場合 (つまり、本来あるべき正式なルールを満たしていない場合) は、memoQはそのファイルのインポートで問題を発生する可能性があります。インポート中に発生した問題のログを取得するには:インポート中の警告をログ(L)チェックボックスをオンにします。memoQは問題をテキストファイルにリストします。警告が表示された場合、memoQは元のドキュメントと同じフォルダにログファイルを保存するように要求します。
インポート問題のログの例:
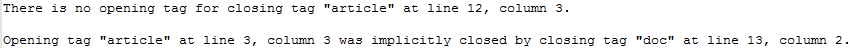
通常、memoQはすべてのテキストとその他のコンテンツをXMLファイルからインポートします。テキストとしてインポートするものを制御する必要がある場合、または翻訳から一部のコンテンツを除外する必要がある場合は、タグと属性タブのオプションを使用します。
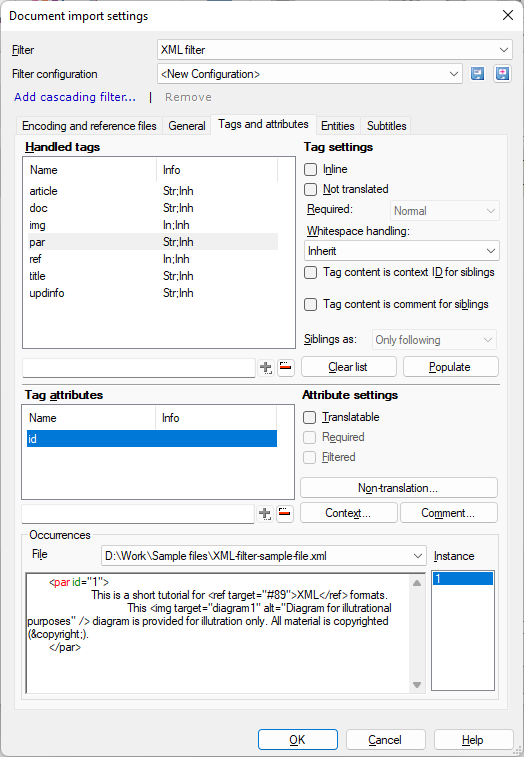
タグと属性タブ内の「タグ」はエレメントを意味し、特定のタグやコンテンツの間の部分を意味します。たとえば、Abstract「tag」を翻訳に設定すると、それは<Abstract>タグと</Abstract>タグの間のコンテンツに属します。
タグと属性ごとにオプションを設定できます。参照ファイルからタグと属性を取得するには:設定(P)ボタンをクリックします。
別のファイルセットを選択してプレビューするには:リストをクリア(C)ボタンをクリックします。エンコードと参照ファイルタブに戻ります。別の参照ファイルを選択します。タグと属性タブをもう一度クリックします。設定(P)ボタンをクリックします。
タグとその属性を設定しているときは、ウィンドウの下部の出現箇所セクションでプレビューできます。
出現箇所では、memoQは選択したタグが1つの参照ドキュメントのどこに出現するかを一覧表示します。タグは赤でハイライト表示され、属性は緑でハイライト表示されます。
参照ファイルを選択して表示するには:ファイルドロップダウンをクリックします。参照ファイル内で選択したタグの出現箇所の1つをチェックするには:インスタンス(I)リスト内の番号をクリックします。
特定のタグを翻訳するか、セグメントを分割するかを選択するには、タグ設定セクションの設定を使用します:
-
処理されたタグ(H):このリストには、追加したタグだけでなく、XMLファイルからのすべてのタグが含まれています。情報列には、各タグの省略された設定が表示されます。
 タグ設定の省略形
タグ設定の省略形
一部の設定では、memoQがタグをインポートするかどうかを指定します:
-
インライン - タグ (セグメントを分割せず、インラインタグとしてインポート)
-
構造 - タグ (セグメントを分割)
-
翻訳対象外 - 翻訳対象外
-
必須 - 必須
タグで空白文字の処理を設定することもできます:
-
継承 - 親 (それを含むエレメント) からのタグの空白設定を継承
-
保持 - 空白を保持
-
標準化 - 空白を標準化
コンテキストとコメントの処理オプション:
-
コンテキスト - タグのコンテンツはコンテキストIDとしてインポート
-
コメント - タグのコンテンツはコメントとしてインポート
-
タグにこれらのオプションを設定するには:処理されたタグ(H)リスト内でクリックし、必要に応じて右側の設定を選択します。
-
インライン(N):選択したタグをインラインタグにするには、このチェックボックスをオンにします。インラインタグは、セグメント内のマークアップです。インラインタグを内部タグと呼ぶツールもあります。インラインタグのコンテンツは翻訳できません。
このチェックボックスをオフにすると、memoQはタグを構造タグとして処理し、翻訳のためにそのコンテンツをインポートします。構造タグは、翻訳用テキスト内に表示されることはなく、常に新しいセグメントを開始します。他のツールでは、構造タグは外部タグとも呼ばれます。
例では:refタグとimgタグはセンテンスの中に表示されるため、インラインとして指定します。その他のタグはすべて構造タグのままにします。
-
翻訳対象外(N):選択したタグを翻訳から除外するには、このチェックボックスをオンにします。memoQは、これらのパーツを翻訳用にインポートしません。
エレメントが翻訳されない場合、その子も翻訳されません:エレメントを翻訳対象外にすると、そのエレメント内の他のエレメントもインポートされません。この例では、xmlまたはdocエレメントを翻訳対象外にしないでください。なにもインポートされなくなってしまいます。
-
必須:選択したタグを必須にするには、このチェックボックスをオンにします。必須タグは、翻訳にコピーする必要がある特別なインラインタグです。必要なタグが翻訳に含まれていない場合、memoQのセグメントにエラーが表示され、ドキュメントをエクスポートできません。
必須タグはインラインタグです:そのコンテンツを翻訳することはできません。
-
空白の処理:このドロップダウンを使用して、そのエレメントでの空白文字の処理方法を選択します。
-
継承 - エレメントは親エレメントと同じ方法で空白を処理します。ルートエレメントは、一般タブからデフォルト設定を受け取ります。
-
変更しない - memoQはすべての空白文字を保持し、翻訳ドキュメントにインポートします。
-
標準化 - memoQは空白文字のシーケンスを1つのスペース文字に置き換えます。
-
-
タグコンテンツを後続セグメントのコンテキストIDにする(D):このチェックボックスをオンにすると、選択したタグのコンテンツが、ドキュメント階層の同じレベルにあるエレメントからインポートされたセグメントのコンテキスト識別子として使用されます。
-
タグコンテンツを後続セグメントのコメントにする(B):このチェックボックスをオンにすると、選択したタグのコンテンツが、ドキュメント階層の同じレベルにあるエレメントからインポートされたセグメントのコメントとして使用されます。
-
次を兄弟タグとして設定(S):このドロップダウンから項目を選択して、上記の2つの設定でコンテキストIDまたはコメントを受け取るセグメントを決定します:
-
後ろのみ:選択したエレメントの後にある兄弟エレメントからのセグメントのみ。
-
前と後ろ:すべての兄弟エレメントからのセグメント。
-
-
 :選択したタグを処理されたタグ(H)リストから削除するには、このボタンをクリックします。
:選択したタグを処理されたタグ(H)リストから削除するには、このボタンをクリックします。 -
 :テキストボックスに入力したタグを処理されたタグ(H)リストに追加するには、このボタンをクリックします。
:テキストボックスに入力したタグを処理されたタグ(H)リストに追加するには、このボタンをクリックします。 タグがリストにない場合:memoQがXMLファイルをインポートすると、設定にリストされていないタグが検出されることがあります。これらのタグは、構造および翻訳対象としてインポートされます。親エレメントから空白設定を継承します。コンテンツはコメントまたはコンテキスト識別子としてインポートされません。
タグの属性は、コンテキスト識別子またはコメントとして使用できます。テキストを翻訳対象にすることもできます。
属性の処理方法を選択するには:
-
処理されたタグ(H)リストからタグを選択します。タグの属性(A)で、memoQは選択したタグに属する属性を一覧表示します。
属性設定は略語で表示されます:タグの属性(A)リストの情報列に、次の属性が表示されます:
属性設定の略語
-
翻訳済み - 翻訳対象
-
必須 - 必須
-
フィルタ - フィルタ
-
NXおよびNY - その属性を持つタグをインポートまたは省略するための条件
-
CxCおよびCxS - コンテキスト識別子オプション
-
CmCおよびCmS - コメントオプション
xml:lang属性は異なります:memoQがxml:lang属性を処理する方法は制御できません - エクスポート時にxml:lang属性値を変更(A)設定に基づいて自動的に実行されます。memoQは、誰かが手動で追加しない限り、インラインタグのxml:lang属性をインポートしません。xml:lang属性をインラインタグに追加することはできますが、そこでオプションを指定することはできません。
-
-
選択した属性の設定を変更するには、属性設定のチェックボックスとボタンを使用します:
-
翻訳対象 - 選択した属性を翻訳可能にします。memoQは属性の値を通常のテキストとしてインポートします。
-
必須 - 選択された属性は、翻訳に挿入されるすべてのタグに存在する必要があります。必須属性は必ずしも翻訳対象とは限りません:memoQは、翻訳の品質チェックと整形式の確保のためだけに使用する場合もあります。
-
フィルタ済み - 翻訳エディタでフィルタしたインラインタグを表示表示に切り替えたときに、選択した属性を非表示にします。
-
コンテキスト - 選択した属性の値は、選択したタグの子または兄弟のコンテキスト情報になります。このボタンをクリックすると、属性に対するコンテキスト設定ウィンドウが表示され、オプションとその説明があります。
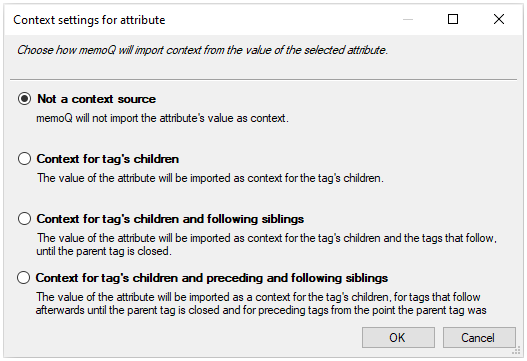
例では:parエレメントのid属性は、コンテキスト識別子として使用できます。
-
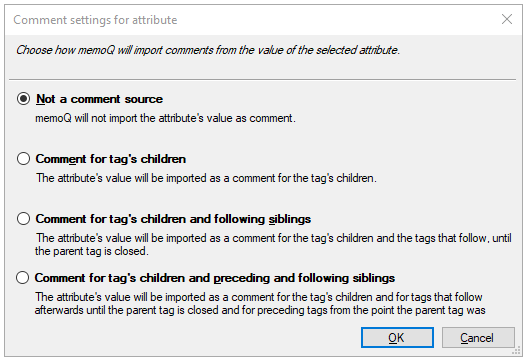
コメント - 選択した属性の値を、選択したタグの子または兄弟のコメントにします。このボタンをクリックすると、属性に対するコメント設定ウィンドウが表示され、オプションとその説明があります。
-
:タグの属性(A)リストから選択した属性を削除するには、このボタンをクリックします。
-
:タグの属性(A)リストの左側のテキストボックスに入力した属性を追加するには、このボタンをクリックします。
属性が不足している場合:属性が構成にリストされていない場合、memoQはその属性を翻訳対象外、必須でない、およびフィルタされなものとして扱います。これらの属性は、翻訳対象外の条件には使用されませんし、コンテキストやコメントの処理でも使用されません。
属性の値に応じて、タグをインポートまたは無視できます。
たとえば、あるタグにtranslateという属性があるとします。値は、translate="no"またはtranslate="yes"のいずれかです。タグでtranslate="no"が表示されている場所はインポートしたくありません。
タグのコンテンツ (およびそのすべての子) をインポートするための条件を設定するには:
- タグと属性タブをクリックし、参考ドキュメントのタグのリストを表示します。必要な場合:設定(P)ボタンをクリックします。
- 条件付きでインポートするタグを選択します。
- タグの属性(A)リストから条件として使用するタグを選択します。
- 右側の翻訳対象外をクリックして条件を設定します。
属性に対する翻訳対象外の設定ウィンドウが表示されます:
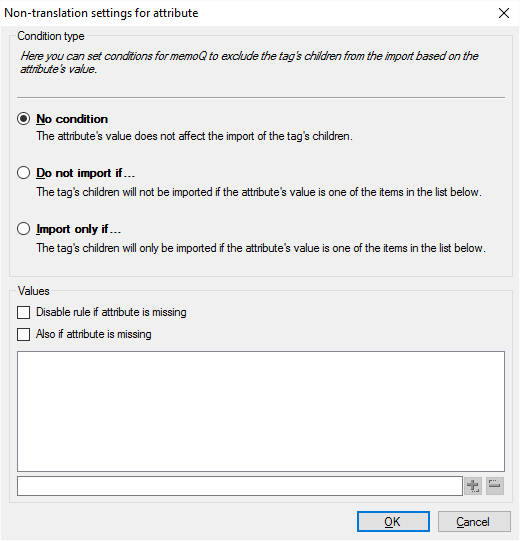
値で、チェックする値を追加します。タグにリストされている値のいずれかが含まれている場合、memoQは、上部で設定した条件に応じて、タグのコンテンツをインポートするか無視します。
-
値をリストするには:下部のテキストボックスに値を入力します。
ボタンをクリックします。複数の値をテストする必要がある場合は、これを繰り返します。translate属性がnoに設定されているかどうかを確認するには、下部に「no」と入力し、
をクリックします。 -
属性にリストのいずれかの値がある場合にタグを無視するには:次の場合にインポートしない(D)ラジオボタンをクリックします。この例では、これをクリックすると、translate="no"が設定されているタグがmemoQで省略されます。
-
属性にリストのいずれかの値がある場合にタグをインポートには:次の場合にのみインポート(I)ラジオボタンをクリックします。この例では、"yes" をリストに追加 ("no" ではなく) し、このラジオボタンをクリックします。これにより、memoQはtranslate="yes"が設定されている場所にタグをインポートします。
属性が不足している場合:属性が不足している場合はルールを無効にする(M)チェックボックスをオンにすると、memoQは条件なし(N)を選択した場合と同様に動作します。属性が不足している場合も適用(S)チェックボックスをオンにすると、memoQは属性に空の値があるかのように動作します。
XMLドキュメントにはエンティティが含まれています - これらの文字は、テキストにそのまま含めることはできません:XML構文の特殊文字であるか、ドキュメントのエンコーディングに適合しないためです。
XMLテキストでは、エンティティは &(エンティティコード); のように見えます。
XML標準で認識される標準エンティティグループがいくつかあります。1つまたは複数を選択できます。インポートするドキュメントに固有のカスタムエンティティを設定することもできます。
エンティティタブでは、どのエンティティを通常の文字としてインポートするかをmemoQに指定できます。翻訳エディタではそれらが表示されます。しかし、翻訳をエクスポートすると、memoQはこれらの文字をエンティティコードとして再度エクスポートします。
これを行うには、エンティティタブの設定を使用します:
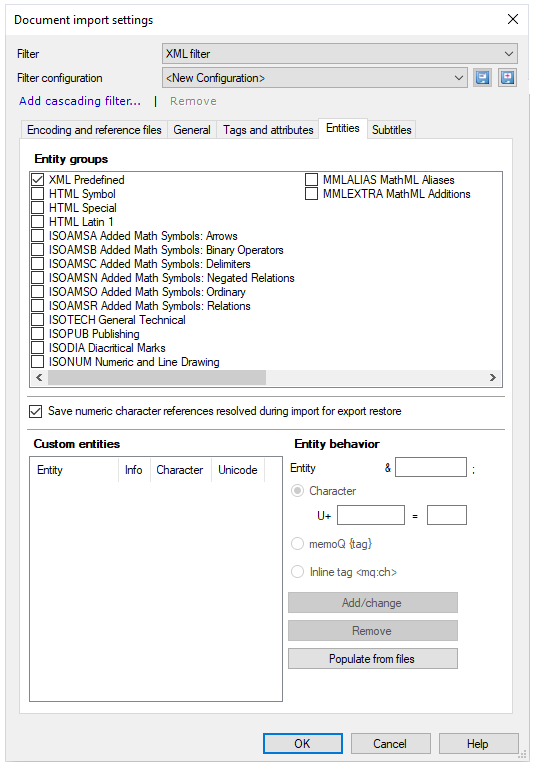
使用できる設定は次のとおりです:
-
エンティティグループ:このリストでは、インポート時に変換するエンティティの標準グループを選択できます。XML Predefinedエンティティ (&、<、>、"、および') は常に処理されます。
-
カスタムエンティティ(C):このリストでは、ドキュメントタイプに特化した非標準のエンティティを指定できます。カスタムエンティティは、インラインタグ、memoQ書式情報タグ、または「通常の」ユニコード文字として翻訳エディタで処理できます。エンティティの動作の3つのラジオボタンのどれを使用するかを選択します。
-
リストに新しいエンティティを追加するには、エンティティフィールドにエンティティを入力します。
-
既存のエンティティの設定を変更するには、カスタムエンティティ(C)リストからエンティティを選択します。サンプルドキュメントには、翻訳用に©に変換されるカスタムエンティティ©right;が1つあります。
-
-
追加/変更(A):カスタムエンティティをカスタムエンティティ(C)リストに追加するには、このボタンをクリックします。既存のカスタムエンティティを変更する場合は、変更が保存されます。
注意:カスタムエンティティ(C)リストの最初のフィールドに、&と;の間でドキュメントに表示されるエンティティを入力できます。ラジオボタンを使用して、このエンティティを文字とタグのどちらとして処理すべきかを選択できます。エンティティを文字として翻訳グリッドに表示すべき場合には、2つめのフィールドにUnicodeコードを入力するか、3つめのフィールドに文字を入力します。
- 削除:カスタムエンティティ(C)リストから選択したカスタムエンティティを削除するには、このボタンをクリックします。
- ファイルから作成(P):参照ファイルにあるすべてのカスタムエンティティを抽出するには、このボタンをクリックします。すべてのカスタムエンティティがカスタムエンティティ(C)リストに再表示されます。
TTMLファイルをインポートする場合、memoQは.ttmlファイル内の「begin」属性と「end」属性に関する情報を検索し、読み取って、その情報に従って字幕を表示します。

長さ制限を設定するには:文書のインポート設定ウィンドウで字幕タブをクリックします。
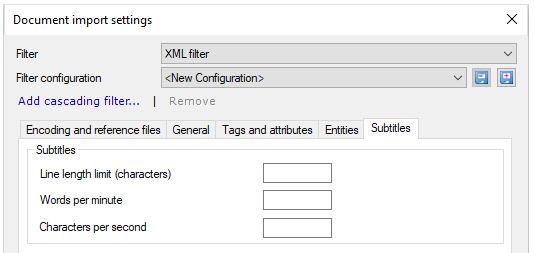
映像翻訳を行う場合、一度に画面に表示できるテキストの量を知ることは重要です。必要に応じて長さ制限 (文字数)(L)フィールドの値を変更します。
密度とは、時間の経過に伴って画面に表示されるテキストの量を意味します。分あたりの単語数(W)および秒あたりの文字数(S) (最も一般的な2つの測定値) に制限を設定できます。
翻訳中、memoQより警告は出ません:セグメントを確定してこれらの制限を超えている場合もmemoQは警告しません。ファイルをエクスポートする場合にのみ、制限より長い行が表示されます。
ただし、memoQビデオプレビューツールでは、ビデオの再生時に3つの値がすべてリアルタイムで表示されます:
翻訳ペインが開いたら、作業するファイルをダブルクリックします。memoQビデオプレビューツールと一緒に開きます。
ビデオプレビューツールにビデオの場所を指示するには:Set video for...フィールドにURLを入力します。
完了したら
-
設定を確定して文書のインポートオプションウィンドウに戻るには:OKをクリックします。
文書のインポートオプションウィンドウで:OKを再度クリックすると、ドキュメントのインポートが開始されます。
-
文書のインポートオプションウィンドウに戻り、フィルタ設定を変更しない場合:キャンセルをクリックします。
-
重ねがけフィルタの場合は、チェーン内の別のフィルタの設定を変更できます。ウィンドウの上部にあるフィルタの名前をクリックします。
一部を翻訳すると、翻訳文書は次のようになります。
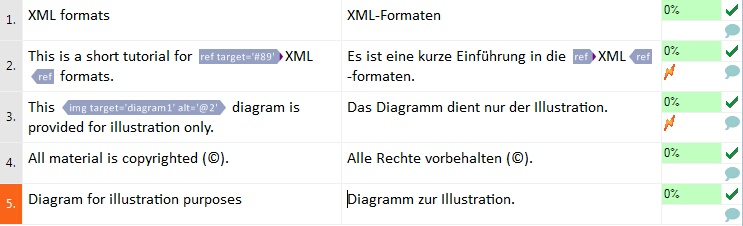
このスクリーンショットのポイントは以下の通りです:
- updInfo属性が翻訳対象外として設定されているため、テキストAug-04-2006(NOT TO BE TRANSLATED)がドキュメント内にありません。
-
テキストDiagram for illustration purposesは、個別のセグメントとして表示され、セグメント3のimgタグ内のalt="@2"は、翻訳対象の属性値が翻訳ドキュメントの2つ下のセグメントにあることを表しています。
翻訳対象の属性は、文書のインポート中に収集および保存され、現在のコンテンツのブロックが終了する位置、つまり次の構造タグで翻訳ドキュメントに挿入されます。
- セグメント2で開始タグrefは、必須の属性「target」がない状態で、ターゲットセルに挿入されました。このため、memoQは警告を表示します。
- セグメント3のターゲットセルにプレースホルダタグimgがないため、memoQは警告を表示します。
- セグメント4でエンティティ'©right;'は'©'に変換されています。