候補を抽出
memoQは、文書、翻訳メモリ、ライブ文書資料から用語を抽出できます。
これは、翻訳のためにプロジェクトを準備するときや、プロジェクトの一部として用語ベースを構築するときに必要になる場合があります。
このウィンドウでは、ソースドキュメント、ライブ文書資料、または翻訳メモリから用語を抽出する方法をmemoQに指示できます。
memoQはテキストを処理し、候補となる用語のリストを表示します。リストに大量のゴミが含まれている可能性があります:用語ベースに用語を追加する前に、用語をクリーンアップ、フィルタ、編集し、「本当の」用語を確定する必要があります。抽出が実行されると、memoQは候補リストエディタを開きます。ここでこれらすべてを実行できます。
候補リストを用語ベースとして参照できるようにすることもできます。
用語抽出を実行するには、ローカルプロジェクトが必要です。
操作手順
- プロジェクトを作成するか、開きます。
用語抽出を実行する前にテキストを追加します:プロジェクトには処理するテキストが必要です。テキストは、プロジェクトドキュメント、翻訳メモリ、またはライブ文書資料です。
- プロジェクトで、ドキュメントをインポートするか、必要な翻訳メモリとライブ文書資料を追加します。
memoQでは、既存の用語ベースを使用して用語抽出を支援できます:用語抽出を実行する前に、それらの用語ベースもプロジェクトに追加します。
- 準備リボンの用語を抽出アイコンをクリックします。候補を抽出ウィンドウが開きます。
このプロジェクトで初めて用語抽出を実行しない場合:最初に用語抽出ウィンドウが開きます。用語抽出の新しいラウンドを実行する必要がある場合は、[新規セッションの開始] をクリックします。詳細については、用語抽出ウィンドウのヘルプページを参照してください。
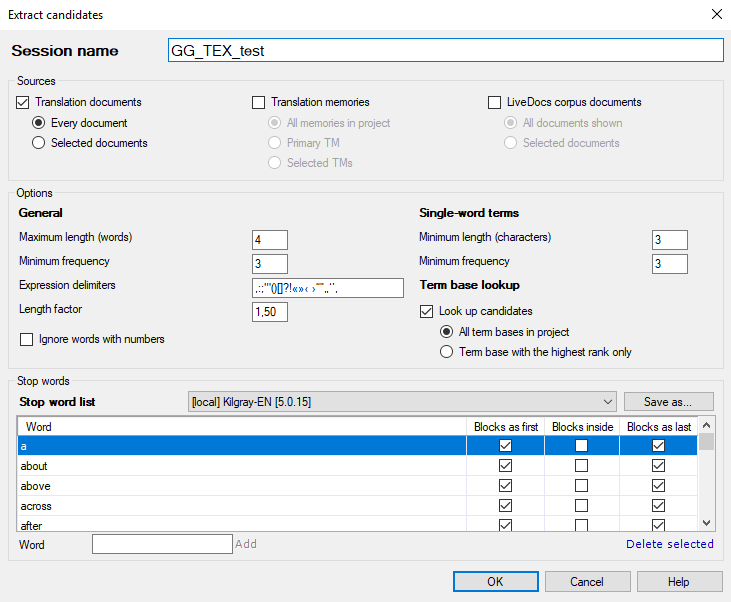
その他のオプション
用語抽出を実行すると、memoQはプロジェクトに用語抽出セッションを作成します。memoQでは候補リストを保存する必要があるため、セッションが必要です。これにより、候補リストを編集して必要に応じて戻すことができます。最初に、候補リストには多くのノイズ (無関係な表現や単語でないものも) が含まれています。ターゲット言語に相当するもののほとんども不足しているでしょう。確定済み用語を用語ベースに追加する前に、候補リストをクリーンアップして編集する必要があります。
memoQはプロジェクトの候補リストを保存します。それを残すことができますし、必要なときにいつでも戻ることができます。
上部のセッション名(N)ボックスに、セッションの名前を入力します。通常、memoQは現在の日付を使用します。ただし、他の名前を入力することもできます。
自動番号付け:セッション名に日付を使用し、同じ日に別のセッションを開始する場合、memoQは日付の後に番号を追加します。(1) は2回目のセッションの場合、(2) は3回目のセッションの場合などです。
memoQが候補を得るために処理する材料を選択します。次の選択肢があります:
- 翻訳文書:通常、memoQでは、プロジェクトにインポートしたドキュメントに対して用語抽出が実行されます。翻訳メモリまたはライブ文書資料だけを処理する場合は、このチェックボックスをオフにします。ただし、プロジェクトにドキュメントがない場合は、グレーアウトされます。
- 全文書(V)ラジオボタン:プロジェクト内のすべてのドキュメントを処理する場合にクリックします。通常、memoQはこれを行います。
- 選択した文書ラジオボタン:選択したドキュメントのみを処理する場合にクリックします。これを使用する前に、作業するドキュメントを選択します。プロジェクトホームの翻訳から実行できます。
- 翻訳メモリ:このチェックボックスをオンにすると、翻訳メモリ内のソース言語テキストが処理されます。そのためには、翻訳メモリがプロジェクトに含まれている必要があります。プロジェクトに翻訳メモリがない場合は、グレーアウトされます。
- プロジェクト内の全メモリラジオボタン:プロジェクト内のすべての翻訳メモリを処理する場合にクリックします。通常、memoQはこれを行います。
- 既定翻訳メモリラジオボタン:作業用翻訳メモリのみを処理する場合にクリックします。
- 選択中の翻訳メモリラジオボタン:選択した翻訳メモリを処理します。これを使用する前に、作業する翻訳メモリを選択します。プロジェクトホームの翻訳メモリから実行できます。
- ライブ文書資料(L)チェックボックス:現在のプロジェクトのライブ文書資料内のソース言語テキストを処理するには、これをチェックします。このチェックボックスは、最初はオフになっています。プロジェクトにライブ文書資料がない場合は、グレーアウトされます。
- 表示中のすべての文書ラジオボタン:プロジェクト内のすべてのライブ文書資料のすべてのドキュメントを処理する場合にクリックします。通常、memoQはこれを行います。
- 選択した文書ラジオボタン:選択したライブ文書資料内の選択したドキュメントを処理します。これを使用する前に、ライブ文書資料から1つまたは複数のドキュメントを選択します。プロジェクトホームのライブ文書から実行できます。
オプションで、用語抽出プロセスを微調整できます。
memoQにおける用語抽出は完全に統計的です:それは候補の長さと頻度に基づいています。候補を抽出するために、memoQはステミングや構文解析のような言語的インテリジェンスを使用しません。ここでのオプションは、統計手順を制御します。
一般:
- 最大長 (単語数)(X)テキストボックス:最長用語候補の単語数。これより長い表現は表示されません。通常は4です。
- 最小登場回数ボックス:ここで指定された回数以上ソーステキストに出現しない候補をリストしません。たとえば、最小登場回数が3の場合、ソーステキストに3回以上出現する候補がリストに含まれます。通常は3です。
- 表現の区切り記号ボックス:これは、用語候補の開始または終了を示す文字のリストです。memoQは、表現の中にこれらの文字が1つ以上含まれている場合、表現を抽出しません。
- 長さ係数(R)ボックス:0.5~3の数値です。memoQが長い表現を好む度合いを制御します。各用語候補 (すなわち、抽出された表現) は、抽出プロセス中にスコアを受け取ります。長さ係数が大きいほど、長い式と短い式のスコアの差が大きくなります。通常は1.5です。
- 番号を含む単語を無視(U)チェックボックス:このチェックボックスをオンにすると、1つまたは複数の数字を含む単語がある場合、memoQは表現を一覧表示しません。通常、これはオフです。
単一単語の用語:単一単語の候補を抽出するために異なるアプローチを使います。それぞれ設定が異なります。
- 最小長 (文字数)(E)ボックス:ここで指定した数より短い単語 (文字数) は表示されません。たとえば、最小文字数が3の場合、memoQは3文字以上の単語候補を抽出します。通常、これは3です。
複数単語の候補に最小長は使用されません。
- 最小登場回数ボックス:ここで指定された回数以上ソーステキストに出現しない候補をリストしません。たとえば、最小登場回数が3の場合、ソーステキストに3回以上出現する候補がリストに含まれます。通常、これは3です。
用語ベースの参照:memoQが候補を抽出する時に、ソース言語のテキストのみで表現が検索されます。しかし、memoQは用語ベースを使って、抽出された候補の翻訳候補を検索することができます。
- 候補をルックアップ(K)チェックボックス:通常、memoQはプロジェクトの用語ベースの各候補の翻訳を検索します。これを行わない場合は、チェックボックスをオフにします。
- プロジェクトにあるすべての用語ベースラジオボタン:プロジェクトボタンをクリックすると、プロジェクト内のすべての用語ベースの候補が検索されます。通常、memoQはこれを行います。
- 最高ランクの用語ベースのみラジオボタン:このボタンをクリックすると、最上位の用語ベースのみで候補が検索されます。
用語の最初、最後、または用語内にあってはならない単語がある場合があります。表現がこれらの単語のいずれかで始まる、いずれかで終わる、またはいずれかの単語を含む場合、その式は用語候補としてリストされません。
これをストップワードと呼びます。
- 候補を抽出ウィンドウの下部に、ストップワードを一覧表示できます。各ストップワードには3つのオプションがあります。最初、最後、または表現の任意の位置から単語を除外できます。
- memoQでは、ストップワードリストを作成、保存、および使用できます。既存のストップワードリストをロードするには:ストップワードリストドロップダウンボックスから1つ選択します。
- 現在のストップワードリストを保存するには:ストップワードリストボックスの横にある形式を選択して保存をクリックします。新規ストップワードリストを作成ウィンドウが開きます。名前と説明を入力します。OKをクリックします。
ストップワードリストはリソースです:リソースコンソールを使用して、保存、ロード、または管理できます。
スクリーンショットは一例です:memoQには、異なるストップワードリストが含まれている場合があります。一方、これはソース言語のデフォルトのストップワードリストではないかもしれません。
新しいストップワードをリストに追加するには:下の単語ボックスに単語を入力します (表現ではありません)。追加をクリックします。
通常、memoQはすべてのチェックボックス (単語中ならブロック、先頭ならブロック、および末尾ならブロック) をオンにして単語をリストに追加します。単語を追加した後、単語が用語内、用語の先頭、または用語の末尾にある場合は、チェックボックスの1つまたは複数をオフにします。
- 単語中ならブロック:単語が用語内に出現する可能性がある場合は、このチェックボックスをオフにします。
- 先頭ならブロック:単語が用語の先頭に出現する可能性がある場合は、このチェックボックスをオフにします。
- 末尾ならブロック:単語が用語の最後に出現する可能性がある場合は、このチェックボックスをオフにします。
リストからストップワードを削除するには:一覧で単語をクリックし、選択した対象を削除(D)をクリックします。
既にリストにあるストップワードは編集できません。ストップワードを変更するには、ストップワードを削除してから再度追加します。
ストップワードリストを編集ウィンドウでストップワードを用意することもできます:ストップワードリストを編集するために用語抽出を実行する必要はありません。リソースコンソールでこれを行い、ストップワードリストを編集ウィンドウを使用します。
読み取り専用のストップワードリストを使用している場合、このウィンドウのストップワード領域では何も変更できません。
完了したら
候補の抽出を開始するには:OKをクリックします。
memoQが候補の抽出を終了すると:候補リストエディタが新しいドキュメントタブで開きます。
プロジェクトホームまたは翻訳エディタにもどる、または用語抽出ウィンドウに戻り、候補を抽出しない場合:キャンセル(_C)をクリックします。