Reguläre Ausdrücke
Reguläre Ausdrücke stellen eine gute Möglichkeit dar, um Zeichenfolgen im Text zu suchen. In memoQ werden sie verwendet, um Segmentierungsregeln, Auto-Übersetzungsregeln oder Regeln für den Regex-Tagger zu definieren. Sie können reguläre Ausdrücke auch in Suchen und Ersetzen und in den Filter-Feldern im Übersetzungseditor verwenden.
Das Suchen von Zeichenfolgen ist jedem bekannt, der schon einmal ein Textverarbeitungsprogramm oder einen Texteditor verwendet hat. Das Dialogfeld Suchen oder Suchen dient diesem Zweck. Wenn Sie nach "ich" suchen, werden im Editor Wörter (oder Teile von Wörtern) wie "ich", "mich" oder sogar "allmählich" hervorgehoben.
Reguläre Ausdrücke bieten hingegen viel mehr Freiheit, auf dem Computer anzugeben, wonach Sie suchen. Sie können Folgen wie Buchstabe „a“ gefolgt von zwei- oder dreimal Buchstabe „c“, eine Reihe von Buchstaben gefolgt von einer oder mehreren Ziffern oder eines der Wörter „Katze“, „Hund“ oder „Maus“ oder sogar Vorkommen eines Wortes innerhalb von Anführungszeichen finden – und vieles mehr. Nachdem Sie diese Seite durchgelesen und mit den Beispielen experimentiert haben, werden Sie genau wissen, wie das geht. Wenn Sie sich für die Details noch nicht bereit fühlen, hilft Ihnen der Regex-Assistent.
Hinweis: Der Begriff regulärer Ausdruck stammt von der mathematischen Theorie, auf der diese Mustervergleichsmethode basiert. Er wird häufig als RegExp oder Regex abgekürzt – hier wird Regex bzw. Regexe (Plural) verwendet.
RegEx-Syntax hat viele Varianten (Ausprägungen): memoQ verwendet die .NET-RegEx-Engine und somit die .NET-Form. In diesem Artikel wird nur ein Teil der .NET-RegEx-Syntax beschrieben. Eine detaillierte Dokumentation finden Sie im jeweiligen Bereich auf der Microsoft Learn-Website.
Standardmäßige .NET-RegEx-Funktionen
In der herkömmlichen Suchfunktion eines Textverarbeitungsprogramms wird jedes Zeichen wörtlich (literal) interpretiert. Wenn Sie nach "Ja? Nein ..." suchen, wird "Ja? Nein ..." hervorgehoben – oder nichts, wenn diese Zeichen im Text nicht vorkommen. In einem Regex haben einige Zeichen eine besondere Bedeutung – sie werden als Meta-Zeichen bezeichnet. Die wichtigsten Meta-Zeichen sind folgende:
Verwirrend? Diese Tabelle ist nur als kurze Zusammenfassung und Referenz gedacht – die Bedeutung all dieser Ausdrücke wird in den Abschnitten unten geklärt.
Fürs Erste konzentrieren wir uns auf den Punkt. In einem Regex bedeutet er "jedes Zeichen kann hier stehen". Daher entspricht der Ausdruck No... in einem Regex Folgendem:
- Notizen
- Notte
- No...
- No&%X
Was müssen Sie also in einen Regex schreiben, um genau "No..." und keinen anderen Text zu finden? Um einem Zeichen zu entsprechen, das eine bestimmte Bedeutung hat, müssen Sie es "escapen", d. h., ihm einen umgekehrten Schrägstrich voranstellen. Daher entspricht No\.\.\. genau "No..." und nichts anderem.
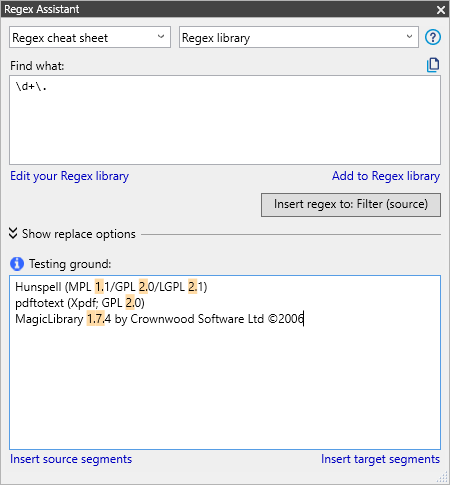
Der RegEx-Assistent verfügt über ein Testfeld für genau diese Ausdrücke. Kopieren Sie beliebigen Text und fügen ihn in das Textfeld Testfeld ein. Geben Sie dann im Feld Suchen einen regulären Ausdruck ein. memoQ hebt Teile, die mit dem regulären Ausdruck übereinstimmen, hervor.
Nachdem wir uns nun mit dem Punkt befasst haben und wissen, wie mit neuen Regexen experimentiert wird, kommen wir zu einigen komplizierteren Ausdrücken. Mithilfe von Klammern in Regexen können Sie einen Satz von Zeichen, eine Zeichenklasse, angeben. [ab][01] entspricht Folgen, die zwei Zeichen lang sind, wobei das erste Zeichen entweder ein "a" oder ein "b" und das zweite entweder eine "0" oder eine "1" ist. Dies ergibt 4 mögliche Treffer: "a0", "b0", "a1", "b1".
Zeichenklassen können verwendet werden, um beispielsweise "eine Ziffer gefolgt von einem Komma oder einem Ausrufezeichen" auszudrücken – was in Form von [0123456789][,!] ausgedrückt werden könnte. Dies wäre jedoch sehr umständlich zu schreiben. Regexe bieten eine bessere Lösung: Sie können einen Bereich von Zeichen angeben, indem Sie [0-9][,! schreiben, was genau dem vorherigen Regex entspricht.
Können Sie eine Zeichenklasse verwenden, das einem Buchstaben des Alphabets entspricht? Ja und nein: Der Ausdruck [a-z] entspricht einem beliebigen Buchstaben von a und z – den Buchstaben des englischen Alphabets. In memoQ wird jedoch mit vielen Sprachen gearbeitet, die häufig Sonderzeichen in ihrem Alphabet aufweisen. Der isländische Buchstabe "đ" beispielsweise ist nicht im Bereich "a-z" enthalten. Solche Zeichen können jedoch einfach gehandhabt werden – siehe den Abschnitt über Kürzel unten.
Berücksichtigen Sie auch, dass alle Buchstaben in memoQ-Regexen unter Beachtung der Groß-/Kleinschreibung interpretiert werden. [a-z] entspricht daher "f", aber nicht "F".
Sie können auch Zeichenklassen verwenden, um anzugeben, was nicht zutreffen soll. Der Regex [^0a]. entspricht einer beliebigen Folge aus zwei Zeichen, bei der das erste Zeichen nicht "0" oder "a" ist.
Wie vorhin beschrieben, müssen Sie die speziellen Meta-Zeichen "escapen" (einen umgekehrten Schrägstrich davor einfügen), um sie als normale Zeichen verwenden zu können: Für ein einfaches "+"-Zeichen müssen Sie die Zeichen \+ in ihrem Regex verwenden. Es sind auch andere geeignete Escape-Sequenzen verfügbar, zum Beispiel entspricht \t einem Tabulatorzeichen und \n einem Zeilenumbruch. Viele Escape-Sequenzen sind zudem Kürzel für Zeichenklassen:
|
Sequenz |
Beschreibung |
|---|---|
|
\s |
Leerraum: Leerzeichen, Tabstopp oder Zeilenumbruch |
|
\S |
Alles außer einem Leerraum |
|
\d |
Ziffer |
|
\D |
Alles außer einer Ziffer |
|
\w |
alphanumerisches Zeichen und Unterstrich |
|
\W |
Alles außer einem alphanumerischen Zeichen |
Diese Kürzel sind etwas anders als die grundlegenden Zeichenklassen im vorherigen Abschnitt: \d entspricht allen Unicode-Dezimalziffern (für viele Schreibsysteme), nicht nur [0-9], und \w entspricht allen Unicode-Buchstaben (Groß- und Kleinschreibung), Zahlen und dem Unterstrich (_), nicht nur [a-z].
Nun da Sie gelernt haben, Zeichen anzugeben, die an einer bestimmten Position zutreffen, ist es an der Zeit, in memoQ anzugeben, wie viele Zeichen zutreffen sollen. Die Sonderzeichen "*", "+" und "?" und der Ausdruck "{num}" werden für diesen Zweck verwendet.
|
Ausdruck |
Beschreibung |
|---|---|
|
* |
Das Zeichen links vom Sternchen im Ausdruck sollte keinmal oder öfter vorkommen. be* entspricht beispielsweise "b", "be" und "bee". |
|
+ |
Das Zeichen links vom Pluszeichen im Ausdruck sollte einmal oder öfter vorkommen. be+ entspricht beispielsweise "be" und "bee", aber nicht "b". |
|
? |
Das Zeichen links vom Fragenzeichen im Ausdruck sollte keinmal oder einmal vorkommen. be? entspricht beispielsweise "b" und "be", aber nicht "bee". |
|
{num} |
Das Zeichen links von der eingeschlossenen Zahl sollte num-mal vorkommen. be{2} entspricht beispielsweise "bee", aber nicht "be". |
-
Der Regex x+ entspricht einer Folge aus einem oder mehreren "x" – also "x", "xx", "xxx" usw.
-
Der Regex x{3} entspricht einer Folge aus genau dreimal "x" – also "xxx", aber nicht "x" oder "xx". Wenn der Text "xxxx" lautet, entspricht der Regex den ersten 3 "x", und das vierte wird ignoriert: "xxx". Dies funktioniert wie das traditionelle Dialogfeld Suchen, das das Wort "ich" in "mich" findet.
-
Sie können auch den Quantifizierer "{num}" verwenden, um einen Minimalwert (und bei Bedarf einen Maximalwert) anzugeben. x{3,5} entspricht also 3 und 5 "x", x{3,} entspricht mindestens 3 "x".
x{,5} funktioniert nicht auf diese Weise: Um maximal 5 "x" zu entsprechen, verwenden Sie x{0,5}.
-
Der Regex x*y entspricht einem "y" mit einer beliebigen Anzahl an vorangestellten "x"-Zeichen (auch keine), also "y", "xy", "xxy" usw., aber nicht "zy".
-
Der Regex zx?y entspricht einem "z", auf das kein oder ein "x" und ein "y" folgt, also "zy" und "zxy", aber nicht "zxxy".
Für eine noch effektivere Verwendung können Sie Zeichensätze oder Kürzel mit Quantifizierern kombinieren: [0-9]+% oder \d+% entspricht einer oder mehr Ziffernfolgen gefolgt von einem Prozentzeichen, z. B. "1%" oder "99%", aber nicht "10a%".
Mithilfe des senkrechten Strichs ("|") können Sie mehrere kleinere Regexe aneinanderfügen, um anzugeben "entweder dem, jenem oder dem anderen entsprechen". Der Regex EUR|USD|GBP entspricht jedem dieser Wörter – und nur diesen.
Wenn Sie Alternativen verwenden, müssen Sie sie oft mithilfe von Klammern gruppieren, um die gewünschten Ergebnisse zu erzielen. Angenommen, Sie möchten einen Regex, der allen folgenden Ausdrücken entspricht: "EUR 15 million", "USD 37 million" und "GBP 5 million". Beim ersten Versuch sind Sie möglicherweise geneigt, EUR|USD|GBP \d+ million zu schreiben. Dies wird den Zweck jedoch nicht erfüllen, da nur den folgenden Zeichenfolgen entsprochen wird: "EUR", "USD" und "GBP [eine Anzahl an Ziffern] million". Sie müssen die Alternativen im Regex gruppieren: (EUR|USD|GBP) \d+ million, wobei EUR|USD|GBP entweder "EUR" oder "USD" oder "GBP" und \d+ eine ganze Zahl ab 0 sein kann.
Bei Segmentierungsregeln verwendet memoQ Regexe, um Mustern im Text des Übersetzungsdokuments zu entsprechen. Für Auto-Übersetzungsregeln wird auch eine andere wichtige Regex-Funktion verwendet, die mit Gruppen zu tun hat: Ersetzen und Neuanordnen von Teilen des zutreffenden Texts.
|
Suchen |
Ersetzen durch |
Beschreibung |
|---|---|---|
|
no |
xx |
Findet die Zeichen "no" und ersetzt sie durch "xx". (In diesem Beispiel gibt es keine Regex-spezifischen Elemente.) |
|
no... |
xx |
Findet "no" und die darauffolgenden 3 Zeichen und ersetzt Sie durch "xx". Zum Beispiel wird "notes" durch "xx" bzw. "monotone" durch "moxxe" ersetzt. |
| (one) two | $1 three |
Findet "one two" und ersetzt es durch "one three". |
|
(one) (two) |
$2 $1 $1 |
Findet "one two" und ersetzt es durch "two one one". |
|
(EUR|USD|GBP) (\d+) million |
$2 Millionen $1 |
Findet "EUR", "USD" oder "GBP", gefolgt von einer Zahl und dem Word "million", und ersetzt sie mit der Zahl, dem Wort "Millionen" und dem Währungscode. So wandeln Sie Geldbeträge aus dem Englischen ins deutsche Format um. |
-
Ersetzen eines zutreffenden Texts durch eine einzelne Zeichenfolge:
In den Fenstern Suchen und Ersetzen können Sie einen Regex in das Feld Suchen und einen ersetzenden Ausdruck in das Feld Ersetzen durch eingeben. Die ersten beiden Zeilen der Tabelle oben zeigen einfache Beispiele dafür, wie eine Zeichenfolge durch eine andere ersetzt wird.
-
Neuanordnen und/oder Ersetzen von Teilen des zutreffenden Texts:
Hier müssen Sie alle Teile des Regex, auf die Sie verweisen möchten, in Klammerpaaren gruppieren. Der in jedem Klammerpaar eingeschlossene Treffer wird in memoQ gespeichert und bekommt eine Nummer zugewiesen, beginnend bei 1. Bei der Eingabe des ersetzenden Ausdrucks können Sie auf die gespeicherten Teilzeichenfolgen $1, $2 etc. verweisen: $1 verweist auf die erste Gruppe in Klammern, $2 auf die zweite usw.
Sehen Sie sich das vorherige Regex-Beispiel noch einmal an. Um Währungen und Werte neu anzuordnen, müssen Sie auch \d+ in Klammern setzen: (EUR|USD|GBP) (\d+) million. Im ersetzenden Ausdruck können Sie auf EUR|USD|GBP mit $1 und auf \d+ mit $2 verweisen. Um die Reihenfolge im Deutschen zu ändern, verwenden Sie den Ausdruck $2 Millionen $1.
memoQ-Erweiterungen
|
Sequenz |
Beschreibung |
|---|---|
|
\tag |
|
|
\itag |
Inline-Tag |
|
\mtag |
memoQ-Tag |
Um Tags mit regulären Ausdrücken zu suchen, können Sie drei spezielle Escape-Sequenzen verwenden:
- \tag entspricht einem beliebigen Tag.
- \itag entspricht einem Inline-Tag (das in einem Text so angezeigt wird:
 ).
). - \mtag entspricht einem memoQ-Tag (das im Text in {geschweiften Klammern} angezeigt wird).
Tags befinden sich normalerweise direkt vor oder nach dem Text (ohne Leerzeichen). Um Regexe besser lesbar zu machen, empfiehlt es sich, die Sequenzen oben in Klammern "()" zu setzen, wenn Sie nach einer Kombination aus Text und Tags suchen. Beispiel: "(\itag)int" entspricht Inline-Tags (öffnende, schließende oder leere Tags), auf die Wörter wie "integriert", "interessant" oder "international" folgen.
Beim Erstellen von Segmentierungs- und Auto-Übersetzungsregeln ist es oft hilfreich, mit Wortlisten zu arbeiten – z. B. Abkürzungen, Monatsnamen, Währungen usw. Theoretisch ist es möglich, diese Wörter gruppiert als Alternativen in den regulären Ausdrücken aufzulisten (siehe Abschnitt über Alternativen oben). Solche Regexe wären aber sehr kompliziert und schwer zu verwalten. Um dies zu vereinfachen, gibt es in memoQ eine spezielle Erweiterung für reguläre Ausdrücke: benutzerdefinierte Listen.
Listen mit Wörtern, die in regulären Ausdrücken verwendet werden, können auf der Registerkarte Benutzerdefinierte Listen des Dialogfelds für Segmentierungsregeln oder des Dialogfelds für Auto-Übersetzungsregeln oder auf der Registerkarte Übersetzungspaare des Dialogfelds für Auto-Translatables definiert werden.
- Verwenden Sie benutzerdefinierte Listen auf der Registerkarte Benutzerdefinierte Listen des Fensters Set an Segmentierungsregeln bearbeiten, um Zeichen und Abkürzungen zu sammeln, die für die Segmentierung wichtig sind (z. B. ".", "!", "e.g.").
- Verwenden Sie benutzerdefinierte Listen auf der Registerkarte Benutzerdefinierte Listen des Fensters Set an Auto-Übersetzungsregeln bearbeiten, um Wörter zu sammeln, die dieselbe ausgangs- und zielsprachliche Form haben (z. B. "€", "$").
- Verwenden Sie benutzerdefinierte Listen auf der Registerkarte Übersetzungspaare des Fensters Set an Auto-Übersetzungsregeln bearbeiten, um ausgangssprachliche Wörter mit ihren zielsprachlichen Entsprechungen zu sammeln (bei Englisch-Deutsch-Projekten sollte z. B. "January" mit "Januar" übersetzt werden, "February" mit "Februar", "March mit "März" usw.).
Der Name einer benutzerdefinierten Liste muss immer mit einem Nummernzeichen ("#") beginnen und enden. Die Wörter, die eine benutzerdefinierte Liste bilden, werden in memoQ immer als Nur-Text interpretiert, d. h., Zeichen werden nicht als Meta-Zeichen mit besonderer Bedeutung behandelt.
Segmentierungsregeln können ein weiteres besonderes Element enthalten: "#!#". Diese Erweiterung hat keine Auswirkung auf die Regex-Übereinstimmung. Stattdessen setzt memoQ dort einen Segmentumbruch, wo der Ausdruck dem Text im importierten Dokument entspricht.
Beispiel für die Verwendung von benutzerdefinierten Listen auf der Registerkarte Benutzerdefinierte Listen des Fensters Auto-Übersetzungsregeln:
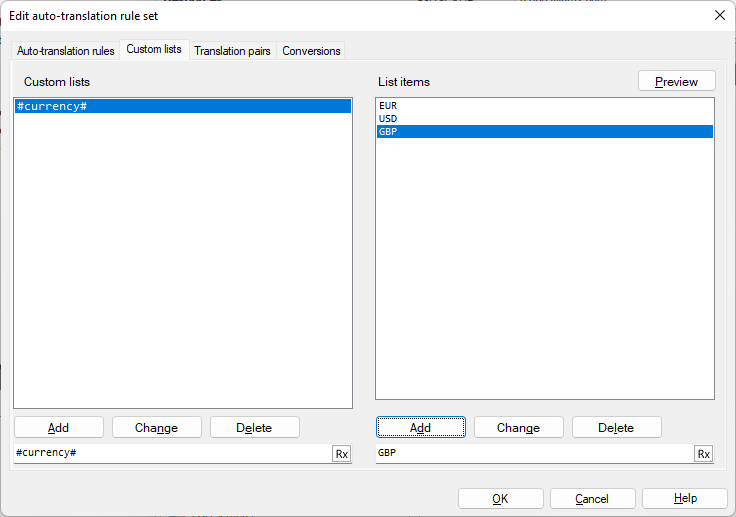
So befehlen Sie memoQ, im Bereich Ergebnisse "15 Millionen EUR" für jedes Auftreten von "EUR 15 million" und "37 Millionen USD" für "USD 37 million" zurückzugeben: Erstellen Sie auf der Registerkarte Benutzerdefinierte Listen die benutzerdefinierte Liste #currency# und fügen Sie die Werte EUR, USD und GBP hinzu.
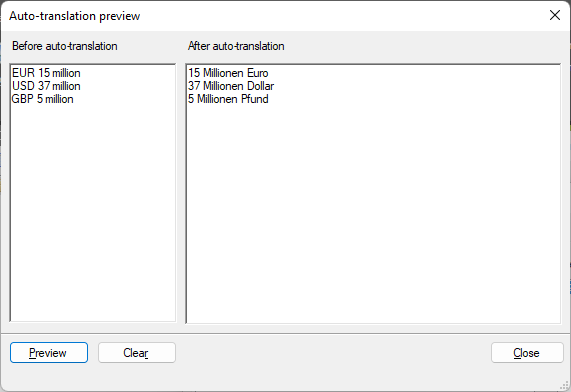
Erstellen Sie nun auf der Registerkarte Auto-Übersetzungsregeln den Regex (#currency#) (\d{1,}) million (derselbe wie (EUR|USD|GBP) (\d{1,}) million) und den ersetzenden Ausdruck $2 Millionen $1. Die Vorschau des obigen Regex und des ersetzenden Ausdrucks ergibt folgendes Ergebnis:
![]()
So befehlen Sie memoQ, im Bereich Ergebnisse "15 Millionen Euro" für jedes Auftreten von "EUR 15 million" und "37 Millionen Dollar" für "USD 37 million" zurückzugeben: Erstellen Sie auf der Registerkarte Übersetzungspaare eine benutzerdefinierte Liste mit dem Namen #currency2# und fügen Sie diese Übersetzungspaare hinzu: "EUR" – "Euro", "USD" – "Dollar" und "GBP" – "Pfund".
Verwenden Sie verschiedene Namen: Namen für Listen auf der Registerkarte Übersetzungspaare müssen sich von jenen auf der Registerkarte Benutzerdefinierte Listen unterscheiden.
![]()
Erstellen Sie nun auf der Registerkarte Auto-Übersetzungsregeln den Regex (#currency2#) (\d{1,}) million und den ersetzenden Ausdruck $2 Millionen $1. Die Vorschau des obigen Regex und des ersetzenden Ausdrucks ergibt folgendes Ergebnis: