Resources > Term bases > (TB) > Import
Most of the time, the file you import does not have all the columns that memoQweb would expect.
Sometimes the columns have names, and sometimes they do not. In the Resources > Term bases > (TB) > Import window, you can convert the columns to term base fields, no matter whether they have names or not.
If you import a text file, even character encoding can be a question. The Resources > Term bases > (TB) > Import window offers a preview where you can check if every character appears as it should.
How to get here
- Sign in to memoQweb.
- On the left sidebar, click the Resources
 icon.
icon. - On the Resources page, click the Term bases
 icon.
icon. - On the Resources > Term bases page, find the term base you need.
- In the TB's row, click the More options
 icon. In the menu, click Import terminology. The Import page opens.
icon. In the menu, click Import terminology. The Import page opens. - Drag a CSV, Excel, or MultiTerm XML file to the area marked with the
 icon. Or, browse to the file, select it, and click the Open button. The import settings appear.
icon. Or, browse to the file, select it, and click the Open button. The import settings appear.
What can you do?
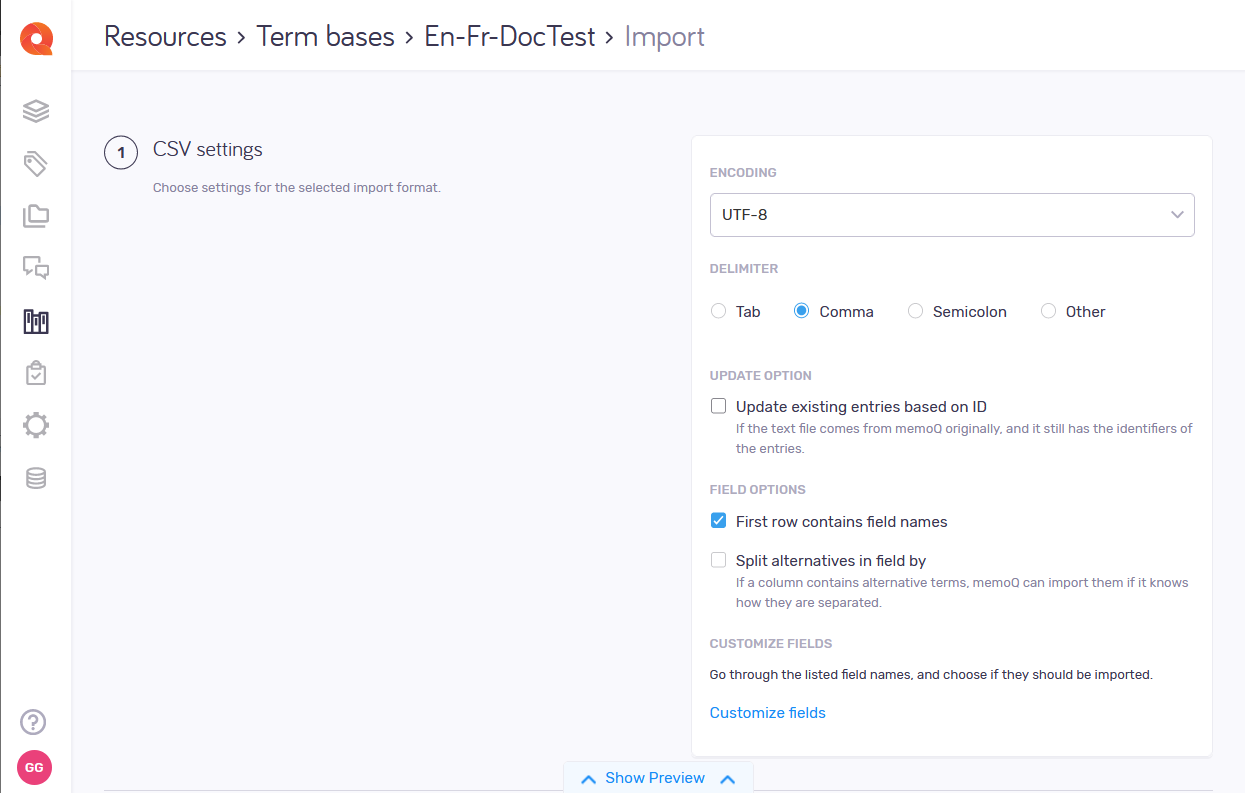
Check the character encoding (CSV files only)
Nowadays, characters are almost always encoded in Unicode - which can encode practically any character or symbol.
Plain-text files may use simpler, older encodings. If the file you import is not Unicode,
If this happens, choose the correct encoding from the Encoding dropdown. You may need to experiment until the characters appear correctly.
Check the delimiter character (CSV files only)
memoQ will choose a delimiter character from the file. In a tabular text file, the delimiter character separates the columns (cells) from each other.
If they do not, you may need to choose another delimiter.
Click Tab, or Comma, or Semicolon, or Other. If you click Other, type exactly one character in the box next to it: the delimiter character that you expect in the file.
After you choose the other delimiter character, check the preview again.
Choose what fields memoQweb imports and where (both CSV and XLSX files)
memoQweb imports each row from the table in a new entry in the term base.
Each column is imported in a field in the term base.
If the file has column headers, memoQweb will try to find the right field for every column.
To make this work, check the First row contains field names check box.
Two or more terms in one cell? If a column contains not one term but several alternatives, memoQweb can still import them if it knows how they are separated. This must be a different delimiter character (not the one that separates the columns). If you have alternatives like this: Check the Split alternatives in field by check box, and type this character in the box next to it.
To choose the fields memoQweb should import: At the bottom of the CSV settings section, click the Customize fields link. In the Fields section, check or clear the fields' check boxes as needed.
To match the columns and the fields to each other: In the preview area, memoQweb shows the field mapping:
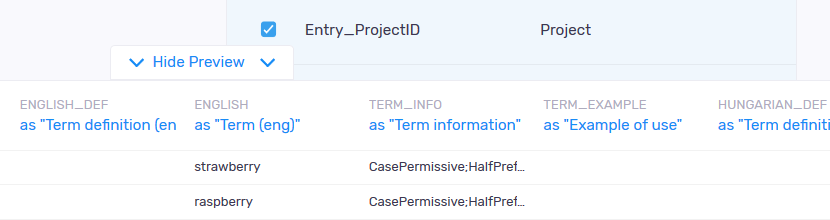
For each field, you can select how it should be imported. A field is a column in the table. Under Fields, you can match (or not match) fields in a CSV file to fields of a term base entry. (You can omit fields from the CSV file.)
Click a blue as "(field name)" link in the preview area. A small window appears:
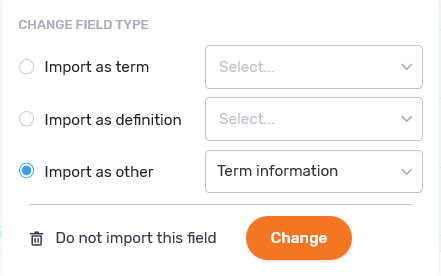
- Import as term: Choose this option to import the contents of the selected field as terms, then choose a language from the dropdown.
- Import as definition: Choose this option to import the contents of the selected field as definitions, then choose a language from the dropdown.
- Import as other field: Choose this option to import the contents of the selected field as Subject, Domain, Note, Creation Date, Creator, Last Modification Date, or Last Modified By.
- Do not import: Click this if you do not want to import the contents of the selected field.
To make the changes: click the Change button under the dropdowns.
In the columns and the fields, a term is not called 'Term': It is called by the language it is in. When memoQweb imports terms, it looks for the English name of the language at the column header, not for the word 'Term'.
memoQweb can automatically detect fields if the first row of the table contains these column headers:
- Entry_ID: Identifier of the entry, normally a number. If you are putting together the table manually, you do not need to use this.
- Entry_Subject: Subject field of the entry.
- Entry_Domain: Domain of the entry.
- Entry_ClientID: Name or identifier of the client involved with the entry.
- Entry_ProjectID: Name or identifier of a larger project that the entry belongs to. Do not mix this with a memoQ project.
- Entry_Created: Date and time when the entry was created. Example: 12/2/2015 11:12:36 AM. If you are putting together the table manually, you do not need to use this. memoQ can fill it in from the system.
- Entry_Creator: Name of the user who created the entry. If you are putting together the table manually, you do not need to use this. memoQ can fill it in from the system.
- Entry_LastModified: Date and time when the entry was last modified. If you are putting together the table manually, you do not need to use this.
- Entry_Modifier: Name of the user who modified the entry for the last time. If you are putting together the table manually, you do not need to use this.
- Entry_Note: A comment that belongs to the entire entry.
- Entry_Image: Folder and file name of the image that belongs to the entire entry. The file name must start with 1_.
- <language>: A term in the specified language. The name of the language must be in English, and it must be one of the languages that memoQ supports. See the list of supported languages. In the same row, there can be several terms - and related fields - for the same language.
- <language>_Def: Definition of the concept in the specified language. The name of the language must be in English, and it must be one of the languages that memoQ supports. See the list of supported languages.
-
Term_Info: This column should always follow a term in one of the languages. It contains the matching settings of the term - case sensitivity followed by prefix matching. Example: "CasePermissive;Custom"
The possible values are the following:
- Case sensitivity: CasePermissive; CaseSensitive; CaseInsense
- Prefix matching: HalfPrefix;Exact;Fuzzy;Custom
- Term_Example: This column should always follow a term in one of the languages. It contains a usage example for the term.
If some entries need to be updated, not added: You can do this if the
Specify user, subject, and domain where the file does not have them (both CSV and XLS files)
If these metadata are missing from the text file, you can still add them to the new entries.
Type the details in the User name where not specified, Subject where not specified, and Domain name where not specified boxes.
If these details are there in the text file: memoQweb will use those, not the ones you type here.
Import an SDL MultiTerm XML file
memoQweb imports SDL MultiTerm XML files with default settings: you cannot change anything.
When you finish
To start the import: Click the Import term base button.
If the CSV also has languages that are not in the term base, you can add them.

To add the languages and continue with the import,
To return to the Import page, click the Cancel link.
To return to the Term bases page: Click the Cancel link.