|
Wenn für ein langes Ausgangssegment kein Treffer aus den Translation Memories vorhanden ist, kann memoQ in den dem Projekt zugewiesenen Translation Memories und Termdatenbanken nach kleineren Teilen dieses Segments suchen. Wenn in den Translation Memories oder Termdatenbanken kürzere Segmente gespeichert sind (zusammen mit ihren Übersetzungen), kann memoQ nach kleineren Teilen (Fragmenten) des langen Ausgangssegments suchen und deren Übersetzungen im Zielsegment einfügen. Dies geschieht automatisch: Wenn Sie zu einem Segment gehen und die Translation Memories und Termdatenbanken durchsucht werden, werden die "Patchwork"-Treffer – oder Fragmenttreffer –, sofern welche vorhanden sind, automatisch in der Trefferliste angezeigt. Die Fragmenttreffer werden in der Trefferliste standardmäßig lilafarben angezeigt, immer nach den Translation-Memory- und Termdatenbank-Treffern. Sie können zu diesen Treffern navigieren wie zu jedem anderen TM- oder TD-Treffer und sie dann mithilfe von Strg+Leer einfügen. Alternativ können Sie auf den lilafarbenen Block des Treffers in der Liste doppelklicken oder die Strg-Taste gedrückt halten und die Zahl drücken (wenn eine vorhanden ist – die ersten 9 Treffer sind nummeriert). Hinweis: Mithilfe der Taste F4 können Sie Fragmente in ein Segment einfügen. BeispielAngenommen, Sie haben zuvor die folgenden Segmente übersetzt:
Außerdem sei in der Termdatenbank der folgende Eintrag vorhanden:
Dann müssen Sie das folgende Segment in einem anderen Dokument übersetzen:
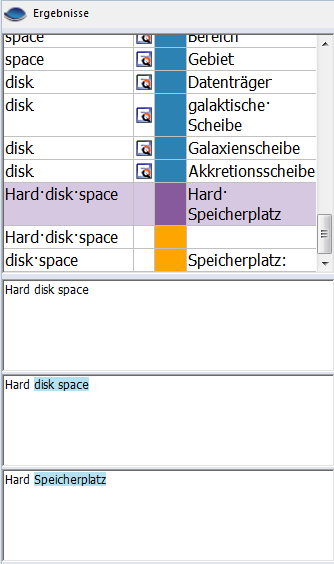
Zum Eintragen der Übersetzung für das obige Segment setzen Sie einfach die Einfügemarke in das Zielsegment. memoQ findet automatisch die zwei kleineren Segmente im Translation Memory und den Termdatenbank-Eintrag für die Benennung am Ende des Segments. Die zusammengefügte Übersetzung wird automatisch in der Trefferliste angezeigt:
Wenn Sie die vorgeschlagene Übersetzung einfügen möchten, drücken Sie Strg+5 – oder verwenden Sie die Strg-Taste und die Pfeiltasten, um zu dem Vorschlag zu navigieren, und drücken Sie dann Strg+Leer. Wenn Sie in den Translation Memories nach einem bestimmten Teil eines Segments suchen möchten, markieren Sie den Text (oder einen Teil davon). Verwenden Sie dann die Konkordanz, oder drücken Sie Strg+K. Wenn Sie in den Termdatenbanken nach einem Textteil suchen möchten, markieren Sie den Text. Verwenden Sie dann Benennung nachschlagen, oder drücken Sie Strg+P. Vorübersetzung mit dem Zusammenfügen von FragmentenSie können das Zusammenfügen von Fragmenten auch während der Vorübersetzung verwenden. (Wählen Sie auf der Registerkarte Vorbereitung des Menübands die Option Vorübersetzen aus.) Wenn ein Projekt, ein Dokument oder die ausgewählten Segmente in memoQ vorübersetzt werden sollen, wird versucht, Übersetzungen aus Fragmenten zusammenzufügen, wenn für ein bestimmtes Segment kein Translation-Memory-Treffer vorhanden ist:
In memoQ erfolgt die Fragmentsuche bei der Vorübersetzung standardmäßig automatisch. Zum Deaktivieren der automatischen Fragmentsuche deaktivieren Sie im Dialogfeld Vorübersetzen und Statistiken das Kontrollkästchen Von Fragmenten einfügen. Wenn Sie auf den Link Einstellungen... klicken, werden die Einstellungen für Fragmenteinfügungen angezeigt. Hier können Sie die Treffer konfigurieren, die in das Zusammenfügen von Fragmenten einbezogen werden sollen: Benennungen, Non-Translatables, Zahlen, Auto-Translatables, Fragmente aus TMs und Korpora. Aktivieren Sie die Kontrollkästchen für die Treffer, die Sie einbeziehen möchten. Im Abschnitt Nur vorschlagen dieses Dialogfelds können Sie eine von drei Optionen für die Abdeckung auswählen: •Vollständige Treffer aus einem Treffer: Wählen Sie diese Option aus, um in der Vorübersetzung mit dem Zusammenfügen von Fragmenten ausschließlich vollständige Treffer mit einem einzigen Treffer zu erhalten. •Vollständige Treffer aus mehreren Treffern: Wählen Sie diese Option aus, um in der Vorübersetzung mit dem Zusammenfügen von Fragmenten vollständige Treffer mit mehreren Treffern zu erhalten. •Treffer mit einer Abdeckung von: Wählen Sie in der Dropdown-Liste die Prozentangabe für die Trefferabdeckung aus. Standardmäßig ist sie auf 50 % festgelegt, d. h., der Treffer muss mindestens eine Abdeckung von 50 % aufweisen. Aktivieren Sie das Kontrollkästchen Ausgangstext ohne Treffer löschen, wenn der Ausgangstext während der Vorübersetzung nicht eingefügt werden soll. Aktivieren Sie das Kontrollkästchen Schreibweise der Benennungen nicht ändern, damit die Groß-/Kleinschreibung von Benennungen nicht automatisch geändert wird. Beispiel: Das Wort "Cancel" ist im Ausgangstext vorhanden, "cancel" als Ausgangstext in der Termdatenbank und "abbrechen" als Zieltext in der Termdatenbank. Dann wird die Benennung nicht in "Abbrechen" geändert. Die Benennungen bleiben grundsätzlich in der Form erhalten, in der sie aus der Termdatenbank kommen, wenn Sie dieses Kontrollkästchen aktivieren – auch am Segmentanfang. Mechanismus beim Zusammenfügen von FragmentenBeim Zusammensetzen einer Übersetzung aus Übersetzungen von Fragmenten wird in memoQ immer ab dem Anfang des Segments nach dem längsten Fragment gesucht. Wenn ein Fragment gefunden wird, wird ab der Stelle, wo das vorherige Fragment endete, wieder nach dem längsten Fragment gesucht. Wird ab dem Anfang des Segments (oder der Stelle, an der mit der Suche begonnen wird) kein Fragment gefunden, wird ab dem nächsten Wort nach einem Fragment gesucht. Wenn die nachfolgenden Suchen ebenfalls erfolglos sind, wird von einem Wort zum nächsten gegangen, bis ein Fragment gefunden wird oder das Ende des Segments erreicht ist. In memoQ werden bei der Fragmentsuche die Translation Memories und Termdatenbanken im Projekt durchsucht. Beim Durchsuchen von Translation Memories werden in memoQ nur exakte Translation-Memory-Treffer verwendet. Es wird nicht versucht, in den Translation Memories annähernd gleiche Treffer (Fuzzy-Treffer) für die Fragmente zu finden. In memoQ wird beim Durchsuchen von Termdatenbanken die Präfix-Übereinstimmung nicht verwendet. Beim Zusammensetzen einer Übersetzung aus Fragmenten wird immer das gesamte Ausgangssegment abgedeckt. Bei der Suche nach Fragmenten wird immer Wort für Wort vorgegangen. Wenn ein Wort nicht durch einen Fragmenttreffer abgedeckt ist – d. h., in memoQ musste ein Wort übersprungen und die Suche ab dem nächsten fortgesetzt werden –, wird die Lücke ausgefüllt, indem das Wort in der Ausgangssprache eingefügt wird. Siehe das Beispiel oben: Im Vorschlag ist noch englischer Text vorhanden. Dies liegt daran, dass keine TM- oder TD-Einträge gefunden wurden, die diese Wörter abdecken. Auswahl aus mehreren Termdatenbank-TreffernIm Allgemeinen werden durch Fragmenteinfügungen Benennungen aus dem Ausgangstext ersetzt. Wenn jedoch zwei oder mehr Termdatenbank-Treffer für ein und dieselbe ausgangssprachliche Benennung vorliegen, muss ein Treffer ausgewählt werden. Aus diesem Grund wird den Termdatenbank-Treffern ein Trefferwert zugewiesen, und der Treffer mit dem höchsten Wert wird übernommen. Natürlich ist der längere Treffer immer stärker, aber wenn die zwei oder mehr Treffer gleich lang sind, müssen sie genauer analysiert werden. Zum einen können Sie Prioritäten für Termdatenbanken festlegen: Wenn eine Benennung aus einer wichtigeren Termdatenbank zurückgegeben wird, hat sie Vorrang. Zum anderen muss dennoch eine Entscheidung getroffen werden, wenn alle Benennungen aus ein und derselben Termdatenbank stammen. Dieser Vorgang kann verwendet werden, wenn die Priorisierung aktiviert ist. Sie können die Priorisierung aktivieren, indem Sie das Dialogfeld Trefferlisten-Filtereinstellungen öffnen und das Kontrollkästchen Termdatenbank-Treffer primär nach Rang und Meta-Daten ordnen aktivieren. Dann wird überprüft, wie viel ein Termdatenbank-Treffer mit dem Projekt gemeinsam hat. Wenn ein Termdatenbank-Treffer zwei Angaben aufweist, die zum Projekt passen, und ein anderer Treffer drei passende Angaben aufweist, hat der Treffer mit drei Angaben Vorrang. Wenn beide Termdatenbank-Treffer gleich viele Angaben aufweisen, die zum Projekt passen, wird überprüft, wie wichtig diese Angaben sind. Für die Wichtigkeit gilt folgende Reihenfolge (angefangen bei den wichtigsten bis hin zu den am wenigsten wichtigen Angaben): •Projektname •Kundenname •Fachgebiet •Domäne Beispiel: Wenn für einen Termdatenbank-Treffer das Feld für den Kundennamen passt und für einen anderen das Fachgebiet identisch ist, hat der erste Treffer Vorrang, weil der Kundenname wichtiger als das Fachgebiet ist. |