|
Use this dialog to choose how memoQ imports JSON files.
JSON stands for Java Script Object Notation, is a text-based open standard and a light weight data-interchange format. JSON is easy to parse and generate for machines. It is based on a subset of the Java Script Programming Language. JSON is used for serializing and transmitting structured data over a network connection (mainly to transmit data between a server and a web application). It is used as an alternative to XML. JSON is a text format which is completely language independent and which uses conventions of the C-family programming languages like C, C++ or C#. The default character encoding for JSON is UTF-8, but JSON also supports UTF-16 and UTF-32. Further information on JSON can be found here (link available at the time of writing).
The structure of JSON contains: • a collection of name/value pairs which is realized as an object, record, structure, dictionary, hash table, keyed list, or associative array •and an ordered list of values which is realized as an array, vector, list, or sequence. Note: The JSON filter in memoQ uses the name/value pairs. memoQ imports the object name as context and the value as source text. How to beginIn the Translations pane of Project home, choose Import > Import with options button on the Documents ribbon tab, and in the Open dialog, locate and select a JSON (.json) file.
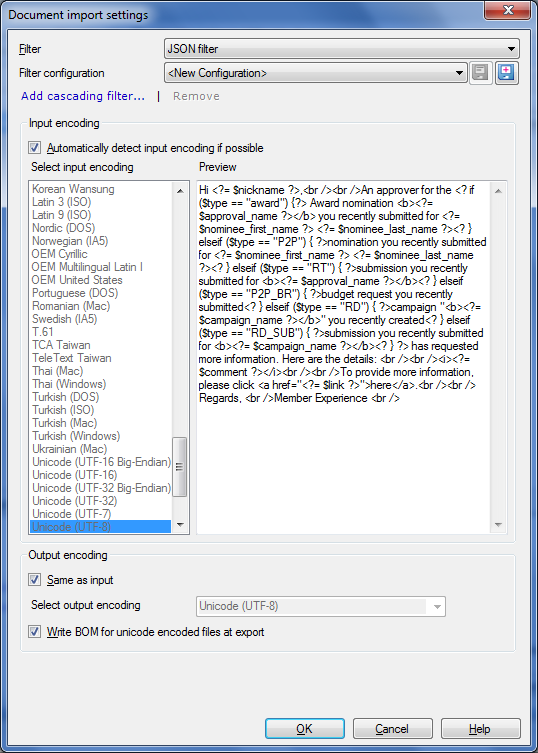
OptionsThe JSON filter allows you to configure the input and output encoding: Input encoding section: Check the automatically detect input encoding if possible check box to detect the input encoding automatically. If the input encoding is not automatically detected, you can define it in the Input encoding if not detected list. Choose an encoding from this list. The Preview box gives you a preview of the chosen input encoding. Output encoding section: Check the Same as input check box to choose the same encoding as the input encoding for export. If the output encoding is not automatically detected, you can define it in from the Select output encoding drop-down list. Choose an encoding from this list. Check the Write BOM for unicode encoded files at export check box. memoQ then changes the output encoding to BOM instead of Unicode. |