|
PO files are a localization format commonly used for writing multilingual programs on Unix computers. PO Gettext files are bilingual and can contain a single source and target. PO Gettext files can be imported into memoQ natively. The exported file is a bilingual one. A PO file entry has the following schematic structure: white-space # translator-comments #. extracted-comments #: reference... #, flag... #| msgid previous-untranslated-string msgid untranslated-string msgstr translated-string •The msgid untranslated-string is imported as source, and the msgstr translated-string is imported as target. The msgid and msgstr contain the source and target string of a translation unit. MSGID elements are unique within a PO domain. For example: msgid " " "Kilgray is " " " "%s. \n" "What is" " " "the company about?" is the same as: msgid "Kilgray is %s. \n What is the company about?" •The msgctxt element is imported as context ID. The #| msgid element is obsolete on import as source and target. •The #, flag element is retained. Flags are used to indicate the status of a translation unit (e.g. finished or fuzzy). A fuzzy flag can be mapped to a memoQ segment status (on the Status mapping tab). Multiple flags are separated by commas. •The # translator-comments can be synched with memoQ comments if you select this option on file import. These comments are added by translators and are not present in PO files. Comments are inserted before the extracted-comments and the reference comments. •The #. extracted-comments and #: reference comments are retained in structure and not modified on import into memoQ. The Extracted comments elements are extracted from the source code if they are in the same line as the source string or in the preceding line. The Reference comments elements are space separated lists of locations, specifying where the translation unit is found in a source file. A single translation unit can contain multiple references (one for each location). You can find a comprehensive specification of this file format here or here. How to beginIn the Translations pane of Project home, choose Import > Import with options button on the Documents ribbon tab, and in the Open dialog, locate and select a PO file. UseGeneric tab:
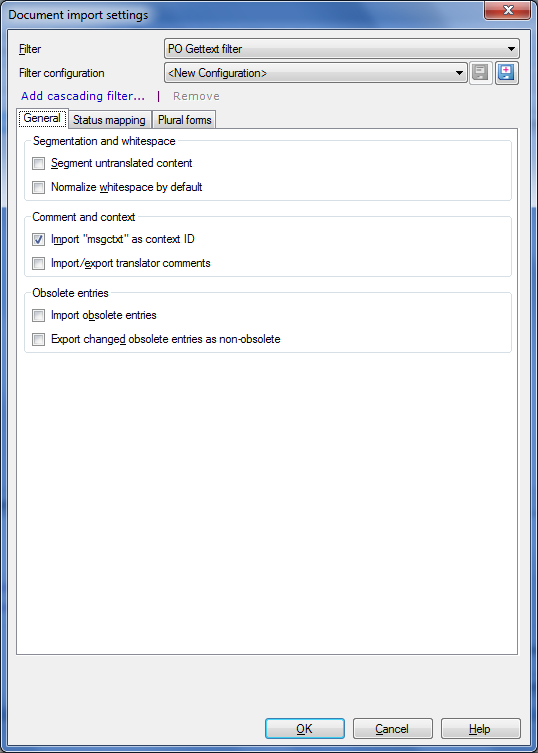
•Segmentation section: Check the Segment untranslated content check box to segment untranslated content. memoQ checks the content on import and can segment content based on the segmentation rules that you use in your memoQ project. •Whitespace section: Check the Normalize whitespace by default check box to normalize whitespaces by default. Whitespaces are normalized in removing preceding and succeeding whitespaces and series of whitespaces are replaced by a single whitespace. For example non-normalized text: This is a test, with a lot of spacings. For example normalized text: This is a test, with a lot of spacings. •Context section: Check the Import msgctxt as context ID check box to use the msgctxt context attribute as context ID on import. •Comments section: Check the Import/export translator comments check box to import or exports comments from the translator. •Obsolete entries section: Here you can decide to import obsolete entries and whether you want to export the changed obsolete entries as non-obsolete. Obsolete entries are entries that are commented out when a PO file is updated, for instance to comment out text that is not for translation. Usually the msgmerge element is used to comment out entries (make them obsolete). Obsolete entries are marked with #~.
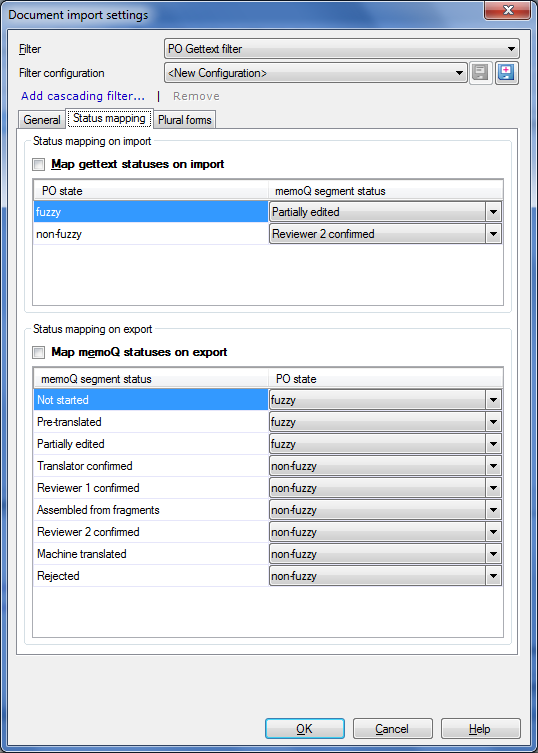
Status Mapping tab: •Status mapping on import section: Check the Map gettext statuses on import check box. By default: The PO state fuzzy is mapped to the memoQ segment status Partially edited. The PO state non-fuzzy is mapped to the memoQ segment status Proofread. •Status mapping on export section: Check the Map memoQ statuses on export check box. By default: The memoQ segment status Not Started is mapped to the PO state fuzzy. The memoQ segment status Pre-Translated is mapped to the PO state fuzzy. The memoQ segment status Partially Edited is mapped to the PO state fuzzy. The memoQ segment status Translator confirmed is mapped to the PO state non-fuzzy. The memoQ segment status Reviewer 1 confirmed is mapped to the PO state non-fuzzy. The memoQ segment status Assembled From Fragments is mapped to the PO state non-fuzzy. The memoQ segment status Reviewer 2 confirmed is mapped to the PO state non-fuzzy. The memoQ segment status Machine Translated is mapped to the PO state non-fuzzy. The memoQ segment status Rejected is mapped to the PO state non-fuzzy.
Plural forms tab: Depending on the target language, the plurals can have one or more variants (e.g. for Slavic languages). Such an entry in a PO file can look like this: #: src/msgcmp.c:338 src/po-lex.c:699 #, c-format msgid "found %d fatal error" msgid_plural "found %d fatal errors" msgstr[0] "s'ha trobat %d error fatal" msgstr[1] "s'han trobat %d errors fatals"
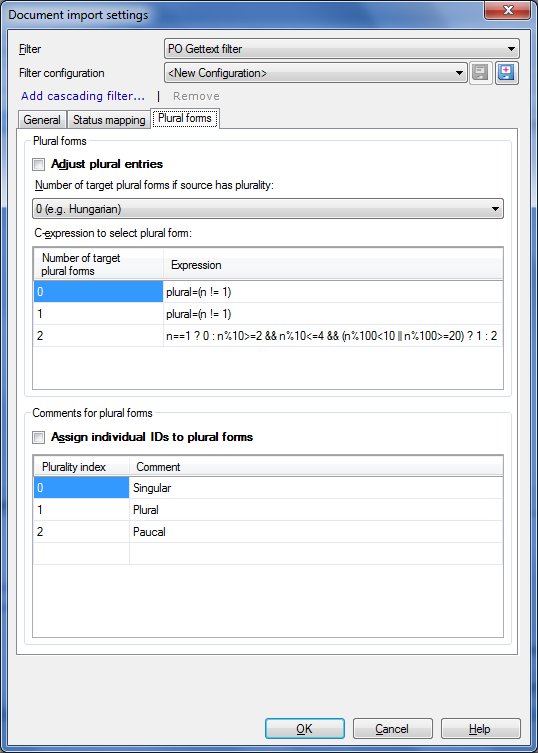
•Check the Adjust plural entries check box to adjust the plural entries. In the Number of target plural forms if plurality is present in source drop-down list, you can choose between 0 (E.g. Hungarian), 1 (E.g. Latin languages) or 2 (E.g. Slavic languages). •Check the Assign individual IDs to plural forms check box to specify the plurality comment assignment. O = Singular, 1 = Plural, 2 = Paucal (Paucal means a few, normally around 3 to 10). When this check box is checked, then individual context info is appended to the msgctxt context attribute. For instance, there are 2 target plural forms, the source and the context ID may be the same for both. In this case, the context would not provide enough information to store them as 2 different units. This can lead to problems with pre-translation.
|