|
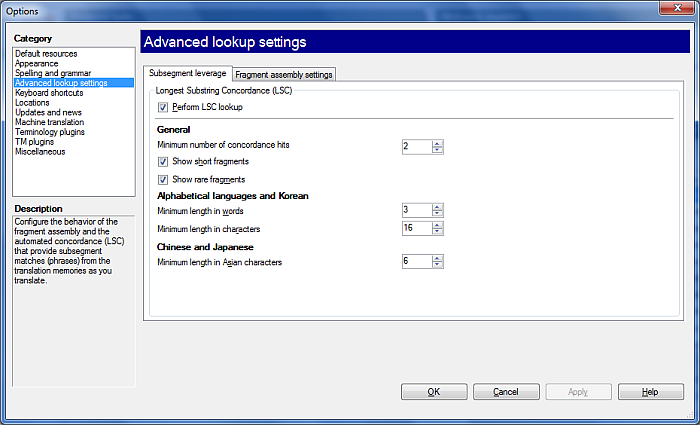
In the Advanced lookup settings pane of the Options dialog, you can change your preferences for automatic concordancing, that is, the Longest Substring Concordance (LSC) feature. You can also configure the fragment assembly settings.
How to beginIn the Application menu, choose Options > Options. Click the Advanced lookup settings category on the left. UseSubsegment leverage tab: This tab allows you to enable, disable, or configure subsegment leveraging. •Perform LSC lookup: Use this check box to enable or disable automatic concordancing during translation memory lookup. If you disable automatic concordancing, lookups might become faster, especially in server environments. General (language-independent) settings: •Minimum number of concordance hits: Use this field to specify the minimum number of concordance results that you require for an LSC hit to appear. Entering 3 will give you an LSC result if concordancing for the source expression returns at least 3 translation units. •Show short fragments: Use this check box to show fragment hits as an LSC result even if they are short. Fragment hits also give you the target expression. •Show rare fragments: Use this check box to show fragment hits as an LSC result even if they do not appear frequently. Fragment hits also give you the target expression. Alphabetical languages and Korean: Use this section to adjust settings for alphabetical languages and Korean. •Minimum length in words: Use this field to specify the minimum length in words that you require for an LSC hit to appear. Entering 3 will give you expressions that consist of at least 3 words. •Minimum length in characters: Use this field to specify the minimum length in characters that you require for an LSC hit to appear. Entering 15 will give you expressions that consist of at least 15 characters. Note: A hit appears only if one of the conditions is met. Chinese and Japanese: Use this section to adjust settings for the Chinese and Japanese language. •Minimum length in Asian characters: Use this field to specify what is the minimum length in Asian characters that you require for an LSC hit to appear. Entering 7 will give you expressions that consist of at least 7 Asian characters.
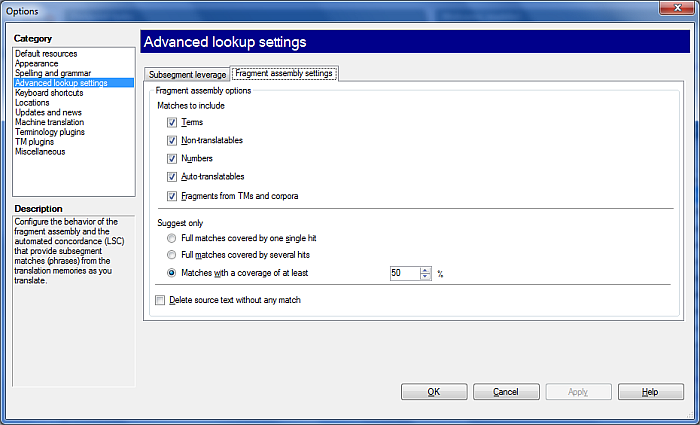
Fragment assembly settings tab: This tab allows you to define the matches to insert for fragment assembly and which suggestions are to be converted into a hit.
Matches to include options: •Terms: Use this option to include terms as matches. •Non-translatables: Use this option to include non-translatables as matches. •Numbers: Use this option to include numbers as matches. •Auto-translatables: Use this option to include auto-translatables as matches. •Fragments from TMs and corpora: Use this option to include fragments coming from TMs and LiveDocs corpora.
Suggest only options: •Full matches covered by one single hit: Suggests one single hit. •Full matches covered by several hits: Suggests matches that have several hits. You should verify which hit is the correct one. •Matches with a coverage of at least: Here you can define the percentage in the drop-down list. It is set to 50% by default. You will get match suggestions according to the percentage you defined here. Check the Delete source text without any match check box to delete the source text that has no match. Note: If there are several matches in a source segment, e.g. one for terms, one for non-translatables, then the text position of the match has the higher priority for insertion. Note: Term base hits, number hits, non-translatable hits and TM/corpus hits are always considered as whole words. If the ending of a source text match has an inflection, that ending will not be added to the target side. A word ends before a white space, ending punctuation, a tag or at the end of a segment. Auto-translatables are recognized within words, they will be inserted. Note: When you translate from a "spacing " language like English to a "non-spacing" language like Japanese, Chinese, Thai, Khmer or Amharic, spaces are omitted between target language matches, also after and before target languages matches. Note: When you translate from a "non-spacing" language to a "spacing" language, spaces will be added between the target language matches, also after and before source language parts. Note: You can also configure the Fragment assembly settings from the Pre-translate dialog to use the fragment assembly in your pre-translation for the document: Check the Perform fragment assembling check box, then click the Settings... link next to it. The Fragment assembly settings dialog appears. NavigationClick OK to close the Options dialog, saving all changes made, or click Apply to save changes while keeping the dialog open. Clicking Cancel will close the dialog without saving changes.
See also: Knowledge Base article: http://kb.kilgray.com/article/AA-00503/24/How-to-use-the-fragment-assembly-in-memoQ-2013.html
|