|
A typical example for importing multilingual XML files:
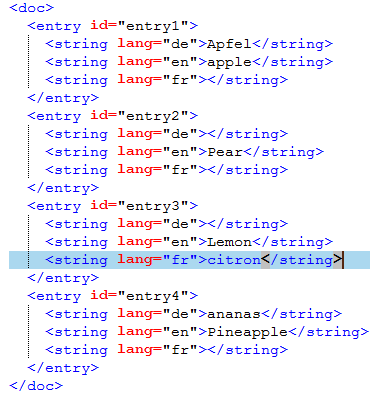
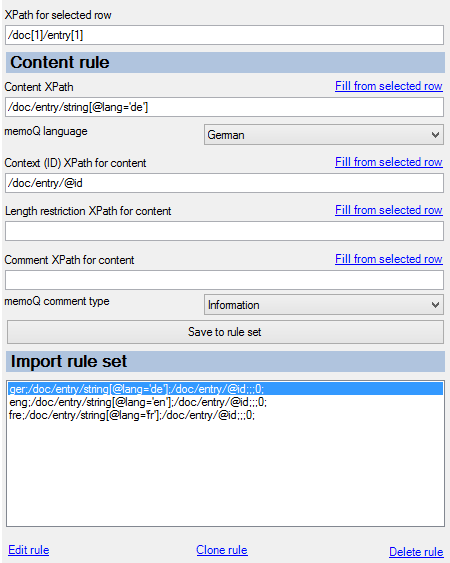
You have entries that have strings or pieces of text for several languages, and hopefully there is an identifier on the entry level that can be used as context ID. In our example, we translate from English into German and French; English is the only language that is always filled. 1. Create an English to German (optional French) project. 2. On the Documents ribbon tab, choose Import > Import with options > Multilingual XML filter > Edit import rules. 3. Expand some of the nodes. Click the first string element node (click the word string, not the text content). memoQ copies the Xpath to that node into the XPath for selected row field: /doc[1]/entry[1]/string[1] This means that in the first doc element, go to the first entry element, and in that, the first string element. You first delete all the “serial numbers” to look like this: /doc/entry/string This now means that in every doc element (even though there is only one in this example), go to every entry and in those entry, go to every string. The result of this XPath is a “node set”, meaning many nodes from the XML. But in the example, only the English strings are wanted. You need to filter the results to get a filter for the value of the lang attribute: /doc/entry/string[@lang=’en’] [@lang=’en’] at the end means “only if the value of the lang attribute is “en”. This XPath expression will return every English string. Place this in the Content XPath field. Select English in the list. In the Context (ID) XPath for content field, you need this: /doc/entry/@id This means: In every doc, go to every entry, and take the value of the ID attribute. This returns a “node set” as well, in the same order as the strings. For example, the first English text defined by the content XPath is “apple”, and the first context ID defined by the context XPath is entry1. memoQ will “link” these together. Click Save to rule set. Repeat the same for German and French. Make sure you change the lang attribute value “filter” to “de” and “fr”, and choose German and French as languages. The below screenshot shows German:
An untypical example for importing multilingual XML files:
This example is a bit more challenging. The name elements in the row elements contain the pieces of text to be translated. But they are not neatly organized into the same parent element, and their order is also "mixed up." Also, here an element value defines the language, and it is on the same level as the name with the text to translate, etc. The IDs that need to be used for context are stored with every row, not in some parent of them. Content rule for English: /data/row[id_lang = '2']/name This means to go to every data element, in that to every row element which has 2 as the content of the id_lang element, and then take the content of the name element as the text for English. In this example, there are two such nodes: the node set will contain two nodes. Context rule for English: /data/row[id_lang = '2']/id_attribute This rule is very similar to the content rule, but you have to take the content of the id_attribute element instead of the name element. You need to filter by language. If you do not include [id_lang = '2'], then your result will be 1, 2, 1, 2 (the contents from all the id_lang elements in the document), which is four nodes, while there are only two nodes containing English text. Add another two nodes containing German text. You need the two IDs that tie them together. Rules for German are all the same, but the language code is 1 instead of 2. Even though the order of the texts is "mixed up" (one German, then two English strings, then one German again), memoQ will use the context IDs to match them up. Note: You can shuffle a long document, as long as the context IDs correctly connect the strings.
What can go wrong: •Context ID: It can be complicated of what should be used as context ID. This should be an identifier that is unique and can be tied to the corresponding language versions of the strings to be imported. •"Asymmetrical" files. If you look at the typical example, it can be observed that for every entry, there is exactly one source for context ID, and exactly one source of text to be imported for every language. It absolutely must be that way all the time. It is not possible to import the file if the context ID is missing somewhere, or the node is missing for the text of one of the languages, or if there is more than one text node for a language. You need exactly one from everything. On file import, there is an error saying that the structure is different. This can happen when the node where you are importing the text from has some additional tags for one of the languages, for example: <string lang="de"></string> <string lang="en">Lemon</string> <string lang="fr">< tag>cit</ tag>< tag>ron</tag></string> This can be a problem because in some cases, memoQ may identify those tags as structural, and thus tries to create two segments for the French text. What you need to do is to define that tag as inline on the Other tags and attributes tab. That ensures that the tag will be imported as inline tag, and there is no such discrepancy between languages.
|