|
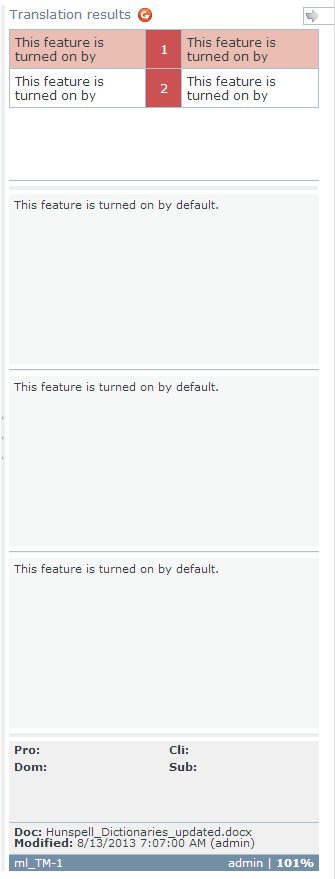
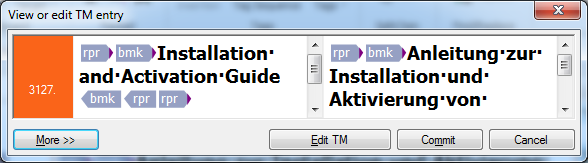
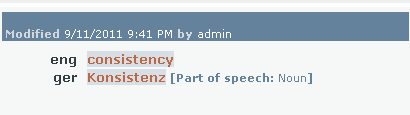
As you translate in the WebTrans interface, you can use multiple resources to help you with your translations. Translation memories are databases of translated segments (sentences). If you are translating a segment and the webTranslate interface finds a similar segment that has been translated before, it automatically offers you a red match in the Translation results list. The difference between the current segment to translate and the segment stored in the translation memory is highlighted in the three compare boxes under the list. The percentage at the lower right corner gives you an indication on the degree of similarity. LiveDocs corpora are similar to translation memories in their nature, but instead of storing standalone sentences, these resources keep translated documents together. For a translator, the experience is very similar, as these matches also appear as red matches in the Translation results list. LiveDocs corpora can also keep unaligned segments, which means that it can happen that the source of the translated segment does not correspond to the target of the translated segment. In the memoQ desktop interface you can correct these on the fly - in the WebTrans interface there is no way to correct these as of now. Both translation memories and LiveDocs corpora show segments that roughly equal to sentences. However, there are times when you are looking for the translation of a word or expression. If the translation has been recorded so far, a blue Term base entry appears, which you insert easily. If it has not been added to the term base, but is hidden in the translation memories or LiveDocs corpora, you can use the Concordance feature. The concordance allows you to find a word or expression in the translation memories or LiveDocs corpora: it gives you all segments with their translations where the word or expression is part of the segment. You may also get results displayed in the Translation results pane coming from light resources: •Fragment search hits: purple. memoQ attempts to put together the translation of the source segment from its smaller parts that are found either in the translation memories or the term bases in the project. In fragment searching, memoQWeb searches the translation memories and the term bases in the project. When searching translation memories, memoQWeb uses exact translation memory matches only. It does not attempt to find approximate (fuzzy) matches for the fragments in the translation memories. When searching term bases, memoQWeb does not use prefix matching. •Automated concordance / Longest Substring Concordance (LSC) hits: orange. memoQ attempts to retrieve the longest possible expressions that can be found by concordancing and tries to offer their equivalent too. •Non-translation rules: gray. Non-translation are terms that do not have a translation like product names or company names like Kilgray. •Auto-translation rules: green. Auto-translation rules are patterns that memoQ looks for in the source segment. Some linguistic elements have many combinations, and cannot be listed, but can be described using special rules. These elements include dates, measures, currency conversion, etc. The order of the hits displayed in the Translation results pane is: oTM and corpora oTB oNon-translatables oAuto-translatables oFragment search (fragment assembly) oAutomated concordance (LSC) Note: The assigned settings for these light resources from the online project are used to display results. Note: You cannot add a new non-translatable from within memoQWebTrans. You can change the order of the hits. Using translation results and manage translation memory entries
|