TM match scoring and number substitution
memoQ can adjust numbers in near-exact and fuzzy matches from TMs and corpora; and it can fill in the actual numbers from the lookup segment instead of the ones stored in the TM. If two segments differ only in numbers, and the numbers in the translation can be fixed up automatically, the match rate is 99 %, and you do not need to do the fixing manually. This saves you costs (lot of high fuzzies) as well as effort.
See also: To get an overview of match rates in general, read the topic about Match rates from translation memories and LiveDocs corpora.
Scenarios for automatic adjustment
- Numbers differ in source and target, e.g. 1.000 vs. 1000
- Numbers with space and non-breaking space thousand separators
- Spaces inside a number, e.g. 2 345
- Numbers like .99 (the integer part is zero)
- Plus signs, e.g. U+002B or U+FF0B
- Tag adjustments to raise a 99% Fuzzy match to be a 100% match based on the Inline tag strictness for exact matches TM setting, see also Tag strictness and match rates
- Optionally, memoQ (version 7.8.100 and later) can return an exact (100%) match if numbers were corrected only. This works if the difference between the document and the match is just numbers, nothing else, and memoQ was able to adjust the match to the difference. This can be turned on in TM settings or in LiveDocs settings.
The number matching also works for Latin numbers in Chinese, Japanese and Korean texts. However, Chinese and Japanese native number formats are not yet supported.
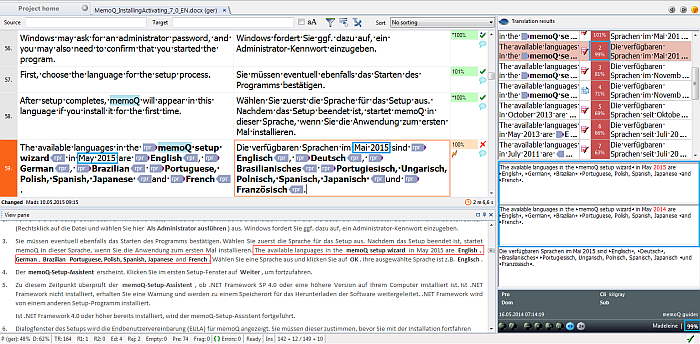
Example for year number correction

Example for number format correction
Note: You do not need to migrate your TMs when you start using memoQ 2015. However, if you want to benefit from the improved matching, you need to repair your TM (Resource Console > Translation memories), then select a TM and click the Repair resource link.
Note: The segment score depends on the word length. Identical words weigh less if short and more if long. The score is lower for 1 vs. 3 word segments. If both segments (lookup and TM) have 5 or less words and both segments are shorter than 128 characters, the Levenshtein algorithm is used (see Edit distance for Levenshtein).