|
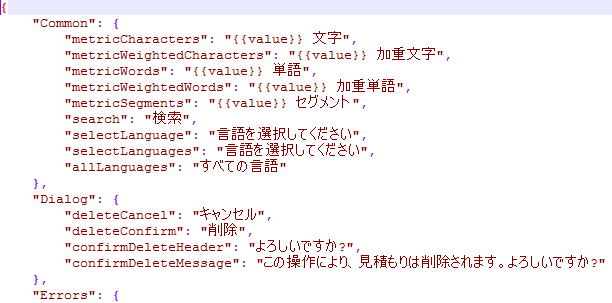
In this window, you can choose how memoQ imports JSON files. This format is used in the localization of interactive websites as well as software products. JSON stands for Java Script Object Notation. It's a text-based open standard and also a data-interchange format. JSON is easy to read and write for machines. It's based on a subset of the Java Script Programming Language. JSON is used for serializing and transmitting structured data over a network connection (mainly to transmit data between a server and a web application). It is used as an alternative to XML. JSON is a text format that is completely language-independent. It uses the syntax of the C-family programming languages such as C, C++ or C#. The default character encoding for JSON is UTF-8, but JSON also supports UTF-16 and UTF-32. To learn more about JSON: Click here (the link is available at the time of writing). There are two types of JSON files. It's either a collection of name-value pairs of objects, or an ordered list of values. memoQ uses the name-value pairs: memoQ imports the object name as context and the value as source text. How to get here1.Start importing a JSON document. 2.In the Document import options window, select the JSON documents, and click Change filter and configuration. 3.The Document import settings window appears. From the Filter drop-down list, choose JSON filter.
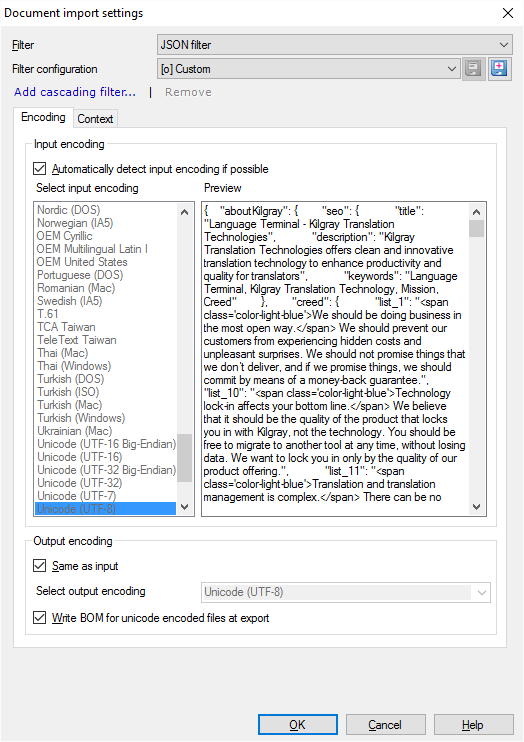
What can you do?Choose the input encoding if necessary
Choose the output encoding if necessary
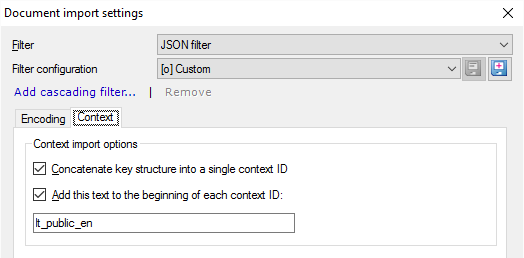
Get the context right - if there are nested blocks
When you finishTo confirm the settings, and return to the Document import options window: Click OK. To return the Document import options window, and not change the filter settings: Click Cancel. If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window. In the Document import options window: Click OK again to start importing the documents. |