HTML documents
Most web pages are HTML documents. HTML stands for Hypertext Markup Language. It was the first mainstream markup standard that coded elements like '<title>Document Import Settings</title>'.
memoQ can import any HTML documents, including those that contain scripts, and any of the HTML versions known at the time of writing. memoQ even supports the HTML 5 format.
memoQ works with PHP, too: Use this HTML filter to translate PHP scripts, or pages with PHP scripts.
How to get here
- Start importing a HTML document.
- In the Document import options window, select the HTML documents, and click Change filter and configuration.
- The Document import settings window appears. From the Filter drop-down list, choose HTML filter.
What can you do?
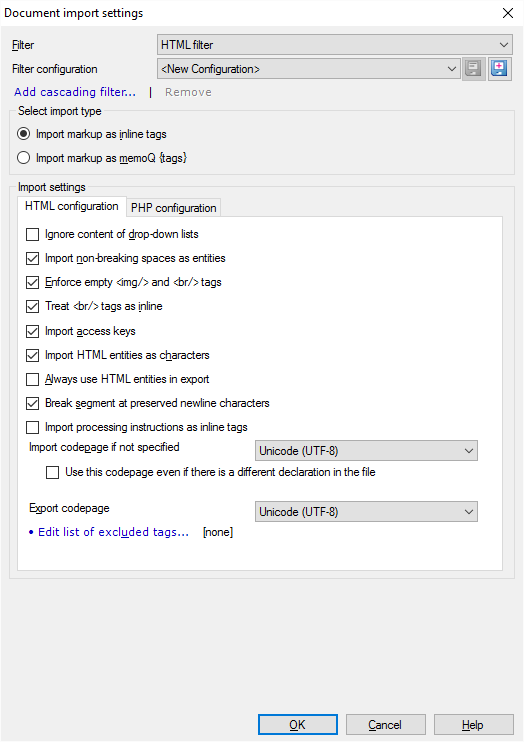
Under Select import type, click Import markup as inline tags.
There are various settings that control how certain parts of the HTML document are imported.
- Ignore content of drop-down lists: Check this to leave out the content of drop-down lists in the HTML code. Normally, memoQ imports these. You usually need to translate them. But sometimes there is program code that expects a drop-down list value - which is lost when it's translated.
- Import non-breaking spaces as entities: Normally, memoQ imports non-breaking space as inline tags. If you want to see them as normal characters, clear this check box. But if you import them as normal characters, they will also be exported as characters, not entities. (The non-breaking space is in HTML.)
- Enforce empty <img/> and <br/> tags: Normally, memoQ recognizes old-style <img> and <br> tags as empty tags. Modern HTML writes these as <img/> and <br/>. Don't clear this check box.
- Treat <br/> tags as inline: Normally, memoQ imports <br/> tags as inline tags. They don't start a new segment. If you want memoQ to start a new segment when there's a <br/>, clear this check box.
- Import access keys: Normally, memoQ imports access keys for translation. Access keys are keyboard shortcuts in forms that help the reader switch to a field or button in the form. If you don't want to translate these, clear this check box.
- Import HTML entities as characters: Normally, memoQ imports HTML character entities as normal characters. This makes the text easier to read. To import these entities as inline tags (for greater accuracy), clear this check box.
- Always use HTML entities in export: Normally, memoQ exports every character as a character. Except for characters that were imported from entities, or those that are missing from the target encoding: They are exported as entities, too. If you check this check box, memoQ exports every character that has an HTML entity - as an entity.
- Break segments at preserved newline characters: Sometimes, people use extra line breaks to make HTML files easier to read. To import these line breaks into separate segments, and keep them in the translated document, leave the check box checked. To leave out these line breaks (both from memoQ and from the translated document), clear this check box.
- Import processing instructions as inline tags: Normally, memoQ imports processing instructions that start with '<$' as uninterpreted {1} tags. To import them as inline tags: Clear this check box. Then memoQ imports them as inline tags of the mq:pi (processing-instruction) type.
Normally, a HTML document specifies the encoding it's in. This is also called a code page.
Most of the time, a HTML document is encoded in Unicode (one of the forms of Unicode), and you don't need to change the settings here.
However, if memoQ can't recognize the code page of a HTML document, the imported text will be unreadable.
In this case, you need to choose the encoding for the source document: Choose it from the Import codepage if not specified drop-down box.
If the encoding is in the file, but it's incorrect, and you don't get readable text: Choose the encoding from the Import codepage if not specified drop-down box, and check the Use this code page even if there is a different declaration in the source file check box.
If the source encoding isn't Unicode, and the target language uses a different script: Choose the encoding for the translated document from the Export codepage drop-down box.
If some parts in the document don't need translation, they can be left out from the input.
You can list the elements at the bottom of the Document import settings window.
To list the excluded elements, click Edit list of excluded tags. The Edit list of excluded tags window appears.
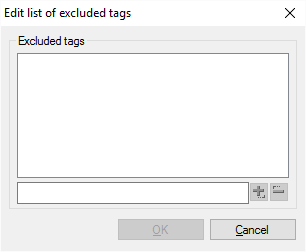
To add an element to the list: In the text box at the bottom, type the name of its opening tag. For example, if you want to skip <title>...</title> elements, type 'title' there. Click the plus sign.
The name of the element appears on the list.
After you finish the list, click OK. The Document import settings window returns.
To remove an element from the list: Click the name of the element. Click the minus sign at the bottom.
Don't import markup as memoQ {tags}: memoQ has an old HTML filter that was written before inline tags were introduced. This filter is only there for compatibility. Don't use it in new projects. Don't click Import markup as memoQ {tags}.
PHP stands for PHP HyperText Preprocessor. It's a powerful programming environment to create interactive web sites. PHP code usually appears in PHP files on the web server.
But PHP scripts can also occur in HTML documents. These scripts are processed by the server. When they are processed, the web server replaces them with HTML text before it sends it to the web browser of the reader.
The point is that the PHP scripts - that appear in HTML documents - can contain text that may need to be translated. They look like this inside HTML documents:

(Source: The PHP manual)
Normally, memoQ doesn't import text from these PHP scripts. If you want to translate these, use the settings on the PHP configuration tab:
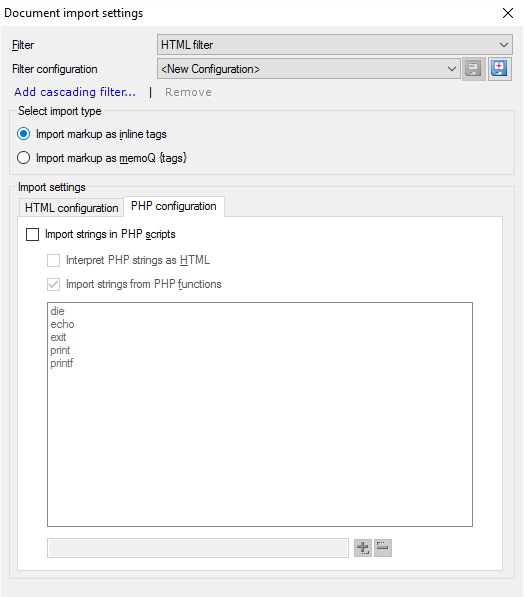
To import text from PHP scripts: Check the Import strings in PHP scripts check box.
If the text in the scripts contains HTML markup: Check the Interpret PHP strings as HTML check box. Normally, memoQ doesn't do it, but you have good reason to assume that HTML tags will be there.
memoQ imports text that is used as arguments in PHP commands (called functions). It means that memoQ will import this:
And memoQ will import this, too:

(Source: The PHP manual)
If you clear the Import strings from PHP functions check box, memoQ imports the second example only.
If the Import strings from PHP functions check box is checked: You can add further commands (functions) to the list. Type the name of the function in the text box at the bottom. Click the plus sign.
When you import a HTML 5 document, memoQ recognizes the translate attribute. This marks elements translatable or non-translatable.
- If the translate attribute is “yes”: memoQ imports the element as translatable. The element is imported even if it is marked non-translatable in the built-in filter configuration. This means it's defined non-translatable (excluded) by the filter configuration. Or, it's the child of a non-translatable element.
- If the translate attribute is “no”: memoQ doesn't import the element. The element is left out even if it is marked as translatable in the filter configuration.
HTML elements can have a language, too: A HTML element can have the 'lang' attribute. It specifies the language of the content. memoQ supports the lang attribute. When you export the document, memoQ changes the lang attribute to the target language. This works for elements that were actually imported for translation. memoQ doesn't change the language code if it didn't match the source language of the project. For example, if part of the document was marked as Japanese in an otherwise English document, memoQ assumes it was on purpose. When matching languages, memoQ ignores sublanguages: English and English-US will match each other.
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window.
In the Document import options window: Click OK again to start importing the documents.