Regex text filter - Structured text files
With the Regex text filter, memoQ can import structured text files, and extract translatable content from them. memoQ can also extract context and comments for the imported content.
Here is a simple example of a structured text file:
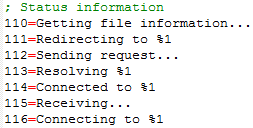
You can mainly control the regex text filter through regular expressions.
The Regex text filter processes structured text files in three steps:
- It breaks up the files into paragraphs.
- It identifies and extracts paragraphs that contain translatable text.
- From the extracted paragraphs, it extracts translatable text, and optionally context and comments.
The options of the filter follow these three steps.
- You need to specify how paragraphs are separated.
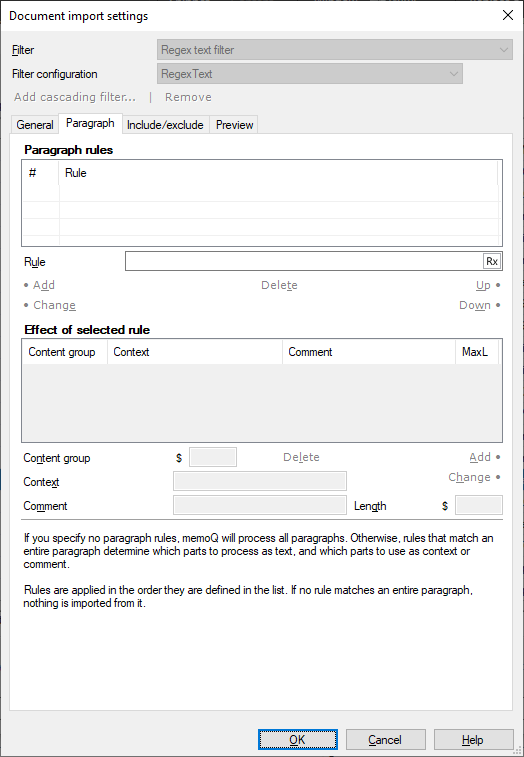
- You describe what an imported paragraph looks like.
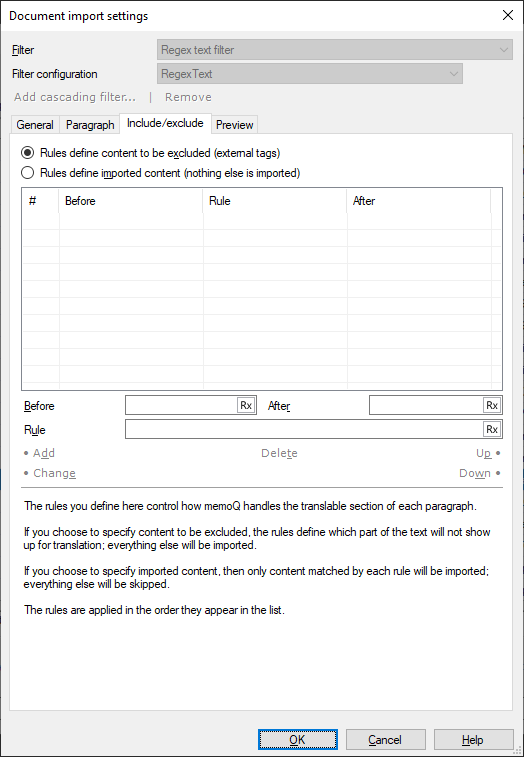
- You list those parts that really need to be translated.
This procedure requires writing up regular expressions, and this is something you can do through trial and error. While you are doing this, memoQ gives you a preview tab that shows what will be imported and how.
You need regular expressions: This is how you can describe patterns that paragraphs or their parts must match. memoQ uses regular expressions after the Microsoft .NET fashion. For a general description of .NET regular expressions, see the Microsoft documentation. For examples of using regular expressions in memoQ, see this help topic.
How to get here
- Start importing a structured text file.
- In the Document import options window, select the text files, and click Change filter and configuration.
- The Document import settings window appears. From the Filter drop-down list, choose Regex text filter.
You may receive settings: If you have received pre-defined regular expression settings from another user, or there is a filter configuration available on a memoQ server in your reach, you can select the filter configuration from the Filter configuration dropdown. In this case, it may be unnecessary to change the settings in the dialog.
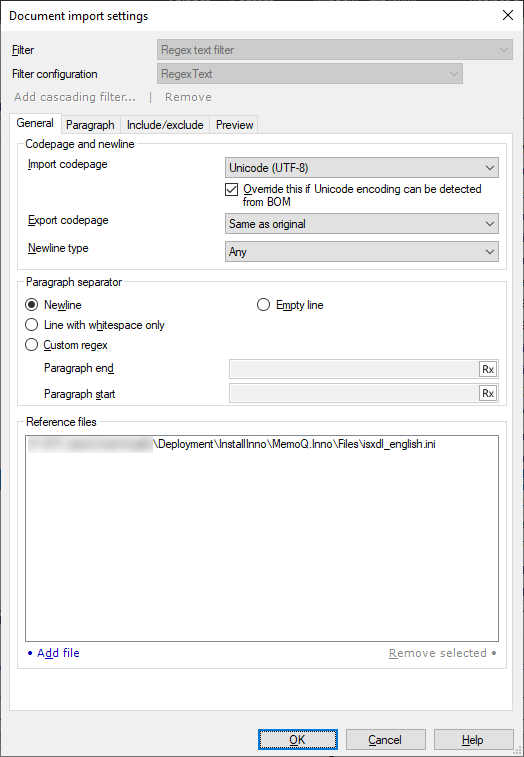
What can you do?
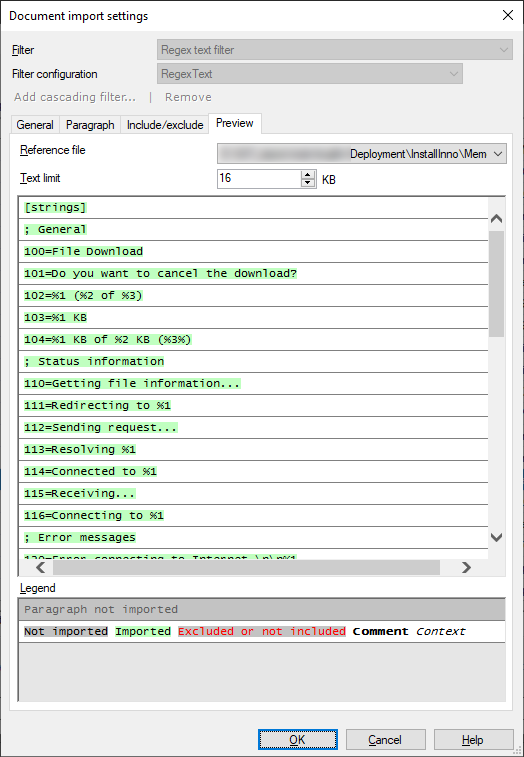
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window.
In the Document import options window: Click OK again to start importing the documents.