マルチリンガル XML ファイル
ドキュメントファイルではなくデータベースに作成されて格納されているテキストを翻訳またはローカライズする必要がある場合、多言語XML (eXtensible Markup Language) ファイルを受け取ることがよくあります。
memoQでは、多言語XMLファイルを多言語プロジェクトに1ステップでインポートできます。これにより、多言語プロジェクトをすばやくセットアップできます。
多言語プロジェクトのみ:このフィルタは、memoQ project managerで多言語プロジェクトを設定する場合にのみ使用してください。
ライブ文書にインポートできません:多言語XMLファイルをライブ文書資料にインポートすることはできません。
XML全般についてさらに学ぶには:XMLファイルのインポートに関するトピックを参照してください。
操作手順
- 多言語XMLファイルのインポートを開始します。
- 文書のインポートオプションウィンドウでXMLファイルを選択し、フィルタと構成を変更をクリックします。
- 文書のインポート設定ウィンドウが表示されます。フィルタドロップダウンリストからマルチリンガル XML フィルタを選択します。
その他のオプション
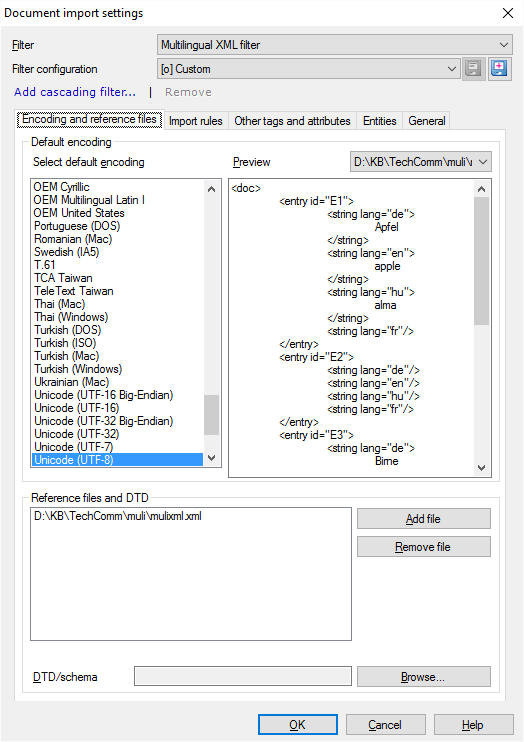
エンコードと参照ファイルタブから開始します。
- エンコーディングをチェックしてください。通常、XML文書にはエンコーディングを設定するヘッダーが含まれています。これがない場合、または間違っている場合は、既定のエンコード方法(E)リストから別のものを選択する必要があります。プレビュー(P)ボックス内の実際のテキストを確認できます。
- 参照ファイルを設定します。通常、memoQはインポートするファイルを使用します。ルールまたはタグを設定する必要がある場合は、同じファイルの内容がmemoQによって表示されます。
プロジェクトのサイズが大きく、現在作業する必要のないファイルが多数ある場合でも、それらのファイルがプロジェクトの一部であった場合、またはプロジェクトの一部になる場合は、それらのファイルを追加できます。参照ファイルとDTDで、[ファイルの追加] をクリックします。
また、すべてのタグと属性を指定する文書型定義 (DTD) またはXMLスキーマがある場合は、それらも使用できます。「DTD/スキーマ」テキストボックスの横にある「参照」をクリックし、DTDまたはスキーマファイルを選択します。
次に、多言語XMLファイル内の異なる言語を処理するインポートルールを設定します。
非常に単純な例を次に示します:

多言語XMLファイルのエントリには、複数の言語で同じテキストが含まれています。インポートルールは、これらの言語のいずれかのテキストの場所をmemoQに指示します。
インポートルールでは、コンテキスト、コメント、およびその言語のテキストの長さ制限があるかどうかもmemoQに通知されます。実際には、言語ごとに1つのインポートルールが必要です。
- インポートルールを設定するには:インポートルールタブをクリックします。下部で、インポートルールを編集(E)をクリックします。XML インポートルールウィンドウが表示されます。
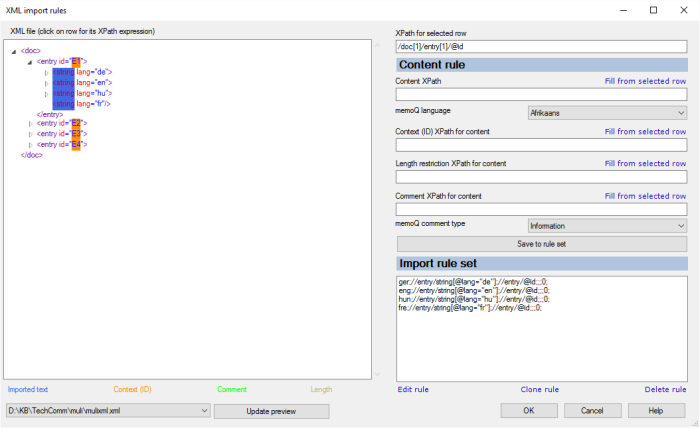
- 左側で、最初のエントリのすべての要素を展開します。
1つの言語のルールを追加するには:
- テキストを含むタグをクリックします。テキスト自体をクリックしたり、属性をクリックしたりしないでください。上の例では、<string lang="de">で'文字列'をクリックします。memoQが選択行の XPathボックスに入力します。
ルールはXPath式で記述されます。XPath式は、XMLファイル内の場所を指します。ある意味では、XMLファイル内の要素の「座標」を記述します。
- コンテンツの XPathボックスで選択行のものを使用をクリックします。クリックした要素を指すXPath式が挿入されます。そのXPath式は他の要素を取りません。この時点で、編集してより一般的にし、適切な条件を設定する必要があります (たとえば、'lang'属性が'de'の場合はドイツ語用の'文字列'を取ります)。
XPath式に必要な編集を行う方法を学ぶには:XMLインポートルールウィンドウのトピックを参照してください。
- memoQ 言語ドロップダウンボックスで、テキストの言語を選択します。この例では、ドイツ語を選択します。
memoQがサポートしている言語を選択できます。ただし、プロジェクトにその言語がない場合、その要素はインポートされません。
XMLファイルには、コンテキスト、コメント、およびテキストの長さの制限 (オプション) として機能する他の要素を含めることができます。
- コンテキストとして使用するエレメントをクリックします。上の例では、entryタグのid (識別子) 属性をクリックします:最初の<entry id="E1">タグで、'id'をクリックします。この場合も、XPath式を編集して、最初のエントリーIDだけでなく、すべてのエントリーIDを選択できるようにする必要があります。
- コンテンツのコンテキスト (ID) XPathボックスで選択行のものを使用をクリックします。
- テキストの最大長を設定する別の要素または属性がエントリ内にある場合は、その要素または属性をクリックします。次に、コンテンツの長さ制限 XPathボックスで選択行のものを使用をクリックします。
- テキストのコメントを含む別の要素または属性がエントリ内にある場合は、その要素または属性をクリックします。次に、コンテンツのコメント Xpathボックスで選択行のものを使用をクリックします。memoQ コメントタイプドロップダウンボックスでmemoQのコメントタイプ (深刻度) を設定することもできます。
- これらがすべて入力されたら、ルールセットを保存をクリックします。
ルールのほとんどの部分はオプションです。もちろん、テキスト (コンテンツ) はそこになければなりません。コンテキストのないルールを設定しようとすると、memoQに警告が表示されます。
ルールを変更する必要がある場合は、一番下にあるルールを選択し、ルールを削除をクリックしてルールを再設定することをお勧めします。
詳細については:XMLインポートルールのトピックを参照してください。
通常、ルールは多言語XMLファイルを扱うのに十分なものでなければなりません。本質的に、「従来の」単一言語のXMLファイルよりも構造が複雑ではありません。
そうは言っても、インラインタグや通常とは異なるキャラクターエンティティーを扱う必要があるかもしれません。場合によっては、エレメントその他を翻訳するために条件を設定する必要がある場合があります。これらは「その他のタグと属性」、および「エンティティ」タブで設定できます。
XMLファイル内のタグ、属性、およびエンティティの処理について学ぶには:XMLファイルのインポートに関するトピックを参照してください。
多言語XMLファイルをインポートする場合は、一般タブで他のオプションを設定できます。
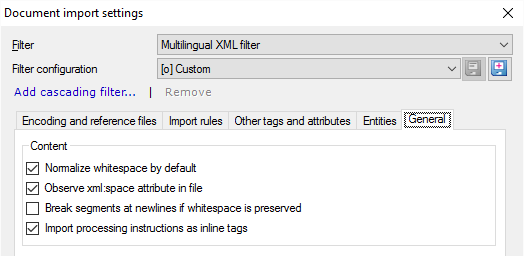
- 既定で空白を標準化(H):通常、memoQはタブ、スペース、および改行文字のシーケンスを1つのスペース文字に変換します。また、memoQでは、エレメントの最初と最後の空白が削除されます。通常、XML文書は読みやすくするために空白を使用します。ただし、スペースが構造またはコンテンツの一部である場合は、これをオフにすることができます:そのためには、このチェックボックスをオフにします。
- ファイル内の xml:space 属性に従う(S):XML文書には、特定の要素で空白を正規化するかどうかを決定する属性を含めることができます (上記のオプションを参照)。通常、memoQはそれらを見つけると、この指示に従います。これらを無視し、ホワイトスペースをすべての場所で同じように扱うには:このチェックボックスをオフにします。
- 空白を保持する場合に改行でセグメントを区切る(B):通常、改行文字がある場合、memoQは新しいセグメントを開始しません。(通常、memoQはスペースに正規化されるため、改行文字に気づきません。)ただし、既定で空白を標準化(H)チェックボックスがオフで、改行文字が新しいセグメントの開始を意味する場合は、このチェックボックスをオンにできます。既定で空白を標準化(H)チェックボックスがオフになっている場合は、空白を保持する場合に改行でセグメントを区切る(B)チェックボックスをオンにすることをお勧めします。
- 処理手順をインラインタグとしてインポート(M):通常、memoQは処理命令 (インラインタグ ('mq:pi' タイプ) の形式で '<$' で始まる) をインポートします。このチェックボックスをオフにしないでください。
完了したら
設定を確定して文書のインポートオプションウィンドウに戻るには:OKをクリックします。
フィルタ構成を変更せず文書のインポートオプションにウィンドウに戻るには:キャンセルをクリックします。
重ねがけフィルタの場合は、チェーン内の別のフィルタの設定を変更できます。ウィンドウの上部にあるフィルタの名前をクリックします。
文書のインポートオプションウィンドウで:OKを再度クリックすると、ドキュメントのインポートが開始されます。
重ねがけ可能: