リソース > 翻訳メモリ > 作成
このページで新しい翻訳メモリを作成できます。
翻訳メモリはバイリンガルです:翻訳メモリには、ソース言語とターゲット言語があります。逆方向の読み込みが可能な翻訳メモリもあります。
操作手順
- 管理者またはプロジェクトマネージャとしてmemoQWebにログインします。
- 左サイドバーのリソース
 アイコンをクリックします。
アイコンをクリックします。 - リソースページで、翻訳メモリアイコンをクリックします。
-
右上の新規作成ボタンをクリックします。リソース > 翻訳メモリ >作成ページが開きます。
その他のオプション
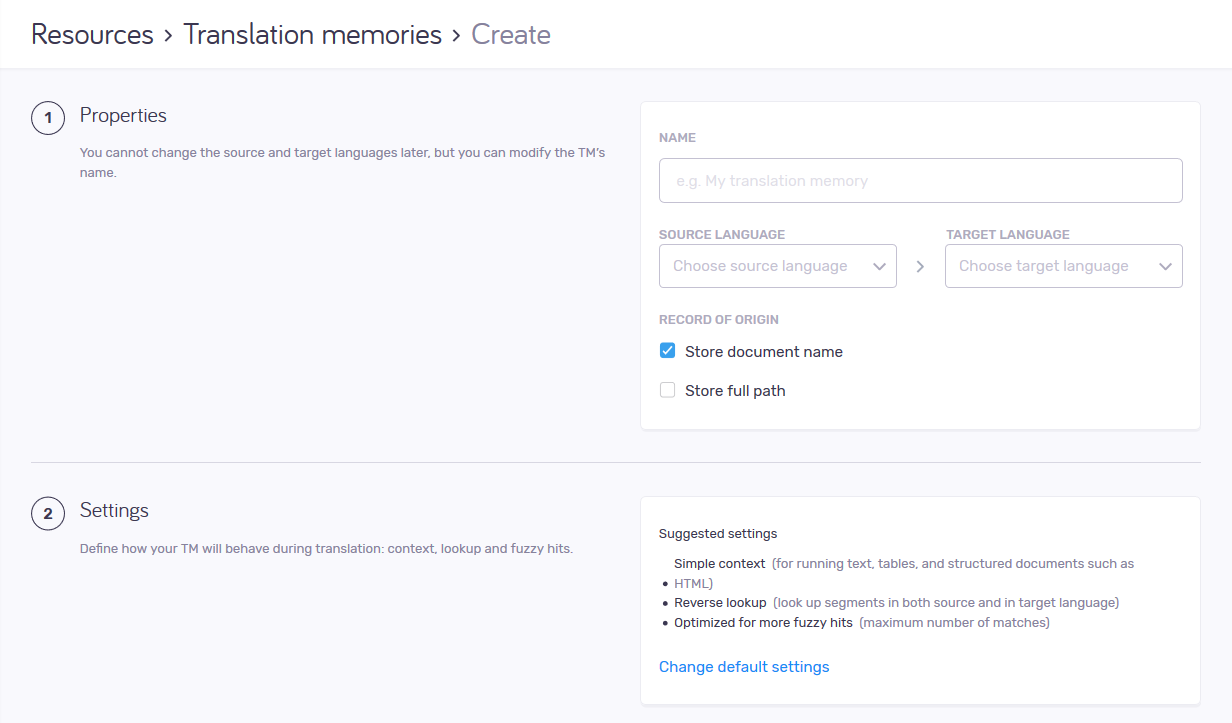
TMの名前、言語、セグメントオリジンの追跡方法を設定する
プロパティセクションでこれを実行します。
名前は、サーバー上で一意でなければなりません。
ソース言語とターゲット言語ドロップダウンで入力を開始し、必要な言語をクリックします。
これは、翻訳メモリを作成する際に決めます:この設定は、翻訳メモリの作成後は変更できません。
翻訳エディタでセグメントを確定すると、memoQはセグメントとその翻訳と共にドキュメントの名前を保存します。これは、翻訳をレビューしている場合、または翻訳をどの程度信頼するかを決定する必要がある場合に興味深いでしょう。
翻訳メモリにドキュメント名を含めない場合:文書名の保存チェックボックスをオフにします。
同じ名前の異なるドキュメントが2つ以上ある場合:これは、さまざまなフォルダからインポートされたドキュメントで作業する場合に可能です。保存されている名前が異なることを確認するには、フルパスの保存チェックボックスをオンにします。
TMがコンテキストを処理する方法、逆方向の言語ペアを許可するか、最適化する方法を選択
設定セクションでこれを実行します。
memoQWebは、ほとんどのTMに適したデフォルト設定を提案します。他の設定を使用する必要がある場合は、デフォルト設定の変更リンクをクリックします。そして、次から選択します:
翻訳中のセグメントがデータベース内でまったく同じ形式で見つかった場合、翻訳メモリは完全一致を返します。ただし、セグメントのコンテキストも同じであることがわかれば、一致をより確実にすることができます。翻訳メモリから文書の翻訳を再構築する必要がある場合は、コンテキストマッチが必要です。また、新しいバージョンのソースドキュメントの翻訳を更新する必要があり、2つのバージョン間にほとんど違いがない場合にも便利です。
翻訳メモリのセグメントとコンテキストの両方が同じである場合、翻訳メモリはコンテキストマッチを提供します。
memoQは2種類の文脈を知っています:
- テキストフローコンテキスト:これは、ソースドキュメントにランニングテキストが含まれている場合に機能します。テキストフローでは、コンテキストは前のセグメントと次のセグメントです。
- IDベースのコンテキスト:これは、ソースドキュメントがテーブルまたは構造化されたドキュメントで、各エントリが識別子を持つ (または持つことができる) 場合に機能します。この場合、コンテキストは識別子であり、セグメントと識別子の両方が翻訳メモリ内で同じである場合、memoQはコンテキストマッチを返します。
コンテキストマッチのマッチ率は101%です。
memoQ二重コンテキストも知っています。二重コンテキストは、ランニングテキストおよび識別子の両方があるドキュメントで可能です。この場合、memoQは翻訳メモリで両方をチェックできます。二重コンテキストマッチのマッチ率は102%です。
コンテキストマッチを返すには、翻訳メモリにコンテキストを格納する必要があります。
通常、翻訳メモリはシンプルコンテキストを格納します。テキストフローまたは識別子のいずれかに基づいています。これは推奨設定です。
ランニングテキストと識別子があるドキュメントを翻訳する場合は:二重コンテキストラジオボタンをクリックします。これにより、翻訳メモリは二重コンテキスト (102%) マッチを返すことができます。
コンテキストなしは選択しない:コンテキストを保存しない翻訳メモリを作成することもできます。これは行わないでください。ただし、翻訳メモリを参照のみに使用し、別の翻訳ツールから翻訳メモリファイルをインポートする場合を除きます。
コンテキストなし翻訳メモリに翻訳を保存しない:翻訳メモリにコンテキストが保存されていない場合は、プロジェクト内で作業用またはマスターの翻訳メモリにしないでください。セグメントを確定すると、memoQは常にコンテキストの保存を試みます。実際には、コンテキストなし翻訳メモリにセグメントを確定すると、情報が失われます。
これは、翻訳メモリを作成する際に決めます:この設定は、翻訳メモリの作成後は変更できません。
複数の訳文を使用しない:memoQでは、同じソース言語セグメントの複数の翻訳を保存できます。別の翻訳ツールから翻訳メモリをインポートする場合や、インポートするファイルに複数の翻訳がある場合を除き、このオプションは使用しないでください。2つの翻訳が異なる場合、それには理由があります。ほとんどの場合、コンテキストも異なります。翻訳メモリ内でコンテキストを使用する場合は (推奨)、複数の訳文は必要はありません。[複数の訳文を許可] チェックボックスがオフになっていることを確認します。
これは、翻訳メモリを作成する際に決めます:この設定は、翻訳メモリの作成後は変更できません。
通常、翻訳メモリはリバーシブルです。つまり、memoQはソース言語とターゲット言語の両方でセグメントを検索できます。つまり、ターゲット言語を別のプロジェクトのソース言語として使用できます。
しかし、memoQはソース言語が重要であることを知っています。プロジェクトの言語方向が逆の場合、翻訳メモリの名前はイタリック体で表示されますが、そこに表示されます。
逆方向の言語を持つプロジェクトでは、翻訳メモリを作業用またはマスタの翻訳メモリにすることはできません。
新しい翻訳メモリーをリバーシブルにしたくない場合:逆方向のルックアップを許可(V)チェックボックスをオフにします。
これは、翻訳メモリを作成する際に決めます:この設定は、翻訳メモリの作成後は変更できません。
通常、memoQはできるだけ多くのマッチを返します。ただし、返されるファジーマッチの数が少なくなるように調整することもできます。しかし、返されるファジーマッチの方がはるかに高速です。
完全一致またはコンテキストマッチのために翻訳メモリを使用する場合は、安全に翻訳メモリを使用できます。
必要に応じて、バランス型または速いルックアップオプションを選択します。
TMのメタデータの設定
必要に応じてプロジェクト、クライアント、ドメイン、サブジェクト(S)および説明を入力します。
完了したら
上記の設定でTMを作成し、翻訳メモリページに戻るには:翻訳メモリの作成ボタンをクリックします。
TMを作成せずに、翻訳メモリページに戻るには:キャンセルリンクをクリックします。