XML (eXtensible Markup Language) files
XML is the world's most versatile data format that defines a sort of markup that can encode almost everything we want to write down.
XML files can hold text, structured data, or even program code, and are perfectly readable for humans and machines.
Anything that looks like this can be XML:
<thing>
<part-of-thing looks="good">
Here is the part of thing
</part-of-thing>
</thing>
A portion enclosed like <thing>...</thing> is called an element.
The part that does the encoding (<thing>, </thing>, <part-of-thing> etc.) is called a tag. The <thing> at the top is an opening tag, and the </thing> at the bottom is a closing tag. There can be elements that have nothing inside. Those could be written as <emptiness></emptiness>, but XML simplifies this by writing <emptiness/>. That is called an empty tag.
Inside a tag that starts an element, there can be parts that describe what the element is like. They are called attributes. In the example, looks="good" is an attribute. An attribute has a name (looks) and a value ("good").
There is a problem: In XML, text is mixed with markup. In the markup, two characters are very special: < and >. The text in the elements can't contain these characters. Instead, XML writes < (less than) for <, and > (greater than) for >.
Anything in the XML text that looks like &(symbol); represents a single character. These are called character entities or just entities. But then another character, the ampersand (&) became special. So, if you want to write a real ampersand in the text, you must write an entity called &.
Now, when you want to describe a particular type of document or data in XML, you must decide what elements, tags, attributes, and entities to use. When you're down to a particular document format that is based on XML, it means that you have chosen a well-defined set of tags in a well-defined structure. HTML is one of those examples. You can't just use any tag in HTML - there are rules of what tags can go where. If you use a different tag, unknown to HTML rules, that will make your document invalid.
The rules that describe what tags and attributes you can use in a type of XML document is called a document type definition. There are separate files that describe a type of document. It's either a document-type-definition file (DTD) or an XML schema.
Many well-known document types are XML – for example, HTML, Word documents (at least DOCX), XLIFF, TMX files (translation memory contents), and many more.
Depending on the XML type, memoQ processes each file differently and suggests a specialized filter for it. For example, when you import a Word document, memoQ offers to use one of the Microsoft Word filters instead of XML. But it will use the XML filter to read the majority of the imported document.
Many authoring and database systems store - or export - contents in XML files. When you translate them in memoQ, use this XML filter to import them.
Multilingual XML files: There are XML files that contain the same text in several languages. To import those files, use the Multilingual XML filter.
How to get here
- Start importing an XML file.
- In the Document import options window, select the XML files, and click Change filter & configuration.
- The Document import settings window appears. From the Filter dropdown, choose XML filter.
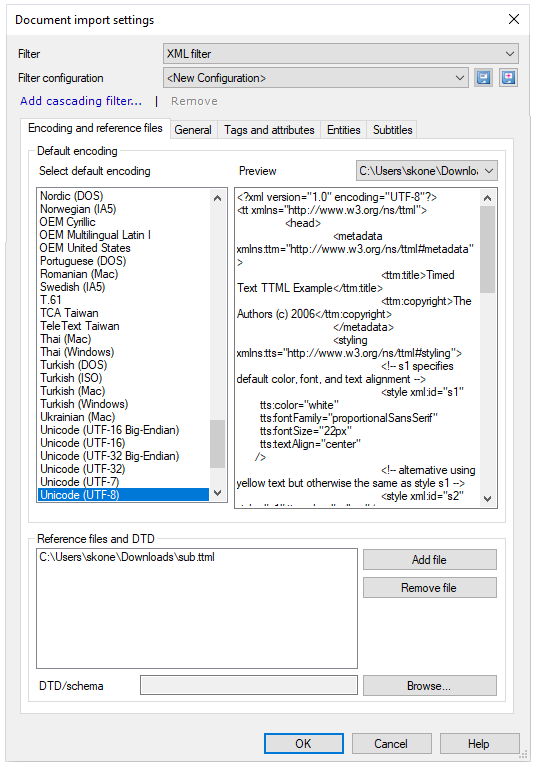
XML configurations are complex, and it's worth saving them: It may take several hours to prepare your import properly. When the configuration is ready, click the Save as a new filter configuration ![]() button next to the Filter configuration drop-down. The next time you need to import an XML file from the same source, you can choose the saved configuration from the same Filter configuration drop-down.
button next to the Filter configuration drop-down. The next time you need to import an XML file from the same source, you can choose the saved configuration from the same Filter configuration drop-down.
What can you do?
To import an XML file properly, you need to set up a lot of things. To make it easier, this topic uses the following example:
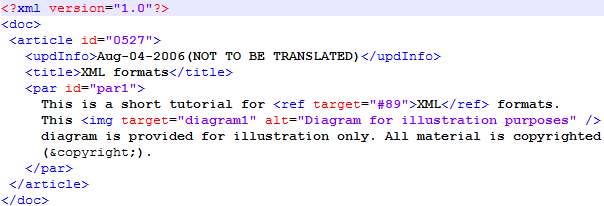
The above example, like any XML document, contains “normal” text that needs to be translated, next to tags like <doc> that hold descriptive or structural information. Tags can have attributes, which have values (id="0527").
The sections below explain how these can be interpreted in memoQ.
This encoding is for the preview and the reference files only: You still need to set up the actual import and export encoding on the General tab.
Usually, the header of the XML file states the encoding. If it's missing, memoQ uses the UTF-8 encoding. In the Preview box, check if everything appears correctly. If not, select a different encoding in the Select default encoding list.
memoQ can use the document type definition (DTD) or the XML schema (XSD) to determine what tags and attributes can be present in the XML document. Without a DTD file or an XML scheme, memoQ reads one or more reference files to discover the tags and attributes.
Normally, memoQ automatically adds all documents that you're importing as reference files. To add more files: Next to Reference files and DTD field, click the Add file button.
Always use the schema or the DTD if you have them: Next to the DTD/schema text box, click Browse, and find the DTD or XSD file.
memoQ can automatically pick a filter configuration if there is a DTD or an XML schema: Click the General tab, and type the name of the DTD file in the DTD or namespace URL field. But if you have a schema, the XSD file will contain an address to the namespace. Copy that from the file to the DTD or namespace URL field. Make sure you save the filter configuration. Next time you import an XML file that uses the same DTD or schema, and memoQ will automatically load the same configuration because it was associated with the DTD or the schema.
Usually, the XML file's header states the encoding. If it's missing, memoQ uses the UTF-8 encoding.
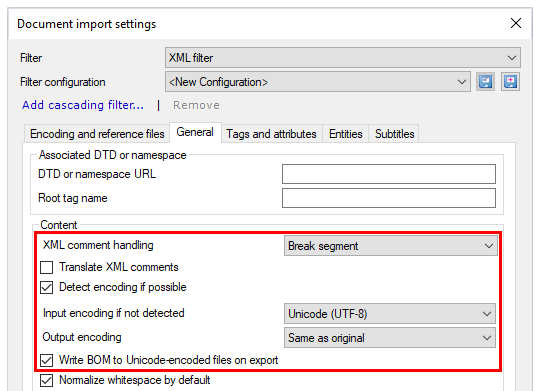
If you need to change this, click the General tab, and use the settings in the Content section.
-
If memoQ couldn't detect the encoding correctly: Clear the Detect encoding if possible check box. From the Input encoding if not detected dropdown, choose the encoding you need. You can also check the encoding on the Encoding and reference files tab, in the Preview box.
-
If the input encoding is not Unicode, and the writing for the source and target languages is different: From the Output encoding dropdown, choose the encoding to use when exporting the translation. Usually, memoQ uses the same encoding as the source document, and it's perfectly normal if the input encoding is a form of Unicode (like UTF-8).
-
Normally, memoQ exports XML files with a byte order mark at the beginning of the file. Some content management systems require this. So, don't clear the Write BOM to Unicode-encoded files on export check box.
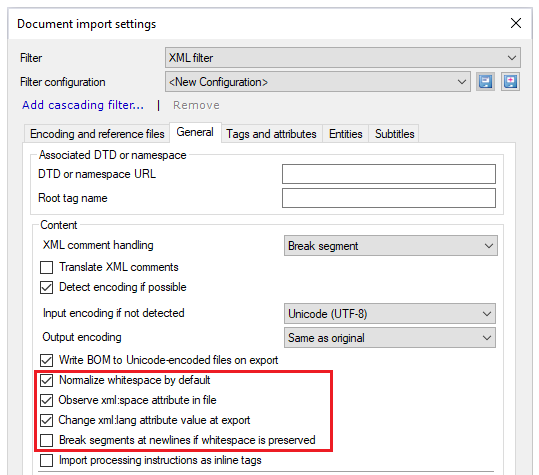
These settings control how memoQ handles whitespace in the text:
-
Normalize whitespace by default: Normally, memoQ converts sequences of tab, space or newline characters into a single space character, and trims whitespace sequences at the beginning and end of elements. Use this when the XML document only uses whitespace characters to improve readability.
If the whitespace characters are required for formatting or structure, clear the Normalize whitespace by default check box.
In the sample document, the text inside the <par> element contains newlines and spaces which do not hold important information, only to make the document easier to read by a human. But these whitespace characters might be difficult to handle during translation. So, in this case, leave whitespace normalization turned on.
memoQ does not preserve spaces inside tags: Even if you clear Normalize whitespace by default, any extra spaces inside tags will be removed. For example, if the source document contains <br />, memoQ will always export <br/>, without the space.
-
Observe xml:space attribute in file: XML documents can contain attributes that tell whether or not whitespace should be normalized in a specific element. Normally, memoQ follows these instructions in the document. If you need to treat whitespace the same way across the whole document, clear this check box.
-
Change xml:lang attribute value at export: Normally, memoQ overwrites xml:lang attribute values with the actual target language's ISO code. If you need to keep the original values for this attribute, clear this check box.
-
Break segments at newlines if whitespace is preserved: Check this option to start a new segment at every newline character. Text imported from XML files may contain newline characters only if you choose to preserve whitespace - in other words, if the Normalize whitespace by default check box is cleared, or when the xml:space attribute says so. When whitespace characters are preserved, newline characters are supposed to have a meaning in the text, and most of the time each line should be translated as a separate segment.
If you clear the Normalize whitespace by default check box, you should check the Break segments at newlines if whitespace is preserved check box.
In some XML files, you need to translate the comments, too. Normally, memoQ doesn't import them.
If you need to change this, click the General tab.
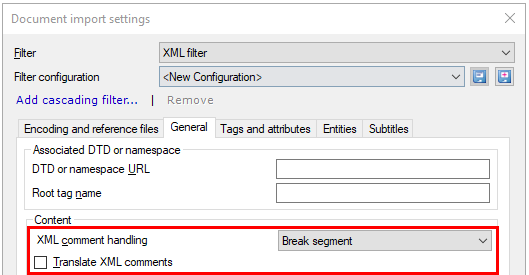
To import the XML comments for translation: Check the Translate XML comments check box.
Normally, memoQ breaks segments whenever it encounters comments. If you need to translate the comments, memoQ imports them in a separate segment at the position where they are in the text, using the project's segmentation rules.
To import the XML comments as inline tags: In the XML comment handling drop-down, choose Import as <mq:cmt> tag. memoQ will transform comments into special inline tags (mq:cmt). If you need to translate the comments, they will be translatable attributes of the mq:cmt inline tag. On the Tags and attributes tab, mark these attributes as translatable, and the text of the comments will not be segmented.
Don't use legacy memoQ {tags}: In the XML comment handling dropdown, don't choose Import as memoQ {tag}.
64-character preview if comments aren't translated: If you don't import comments for translation, the translation editor displays the first 64 characters as preview in the filtered and long tag views. The full text of the comments is saved with the XML file's skeleton, so that they can be exported back in the translated file.
Normally, memoQ gives you a standard preview of XML documents that shows all the tags and the structure of the document.
But if the XML document represents formatted text, it's possible to get a better formatted preview.
Usually, XML doesn't say anything about the actual formatting. This information needs to be added to it from the outside. For that, you need an XML stylesheet or an XML stylesheet template (XSLT).
XSLT transforms the XML files into something that can be displayed. For example, if an XML is converted into HTML through XSLT, the result can be viewed in a web browser. memoQ accepts XSLT files that transform XML files into HTML, but you need to have this file ready; memoQ doesn't create such files.
To learn how to create XSLT files: visit w3school page about XSLT Introduction.

Once you have the XSLT file, click the Browse  button next to the XSLT file field.
button next to the XSLT file field.
XSLT must produce HTML: The XML style sheet must create HTML output. If the style sheet emits a different format (plain text, RTF, or another XML), you can't use it here.
To change the XSLT preview: Click Remove XSLT assignment. Then, if necessary, specify another XSLT file.
For this, use the settings at the bottom of the General tab:
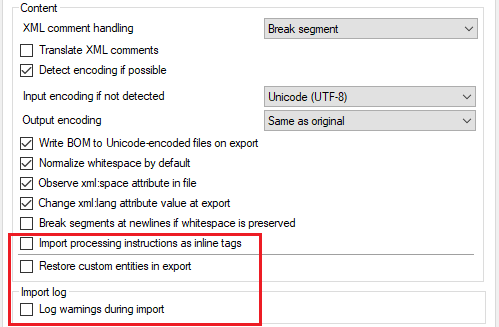
-
XML files may contain processing instructions. They look like tags, but they start with the <? characters. They are used by the content management system that stores the file, or a program that displays the file. Normally, memoQ displays them as uninterpreted formatting tags. This is not recommended. Instead, to import these processing instructions as inline tags and display them as mq:pi tags: Check the Import processing instructions as inline tags check box.
-
Your document can contain custom entities - characters that are not defined in the XML standard, but are used by the content management system that stores the file, or a program that displays the file.
Normally, memoQ displays and exports these as characters, not as entity codes (&(entityname);). For example, ©right; in the original file becomes © in memoQ.
To restore the entity codes for these characters when exporting the translation: Check the Restore custom entities in export check box. In this case, © in the target text becomes ©right; in the exported file. If you do not check this check box, the exported document will also contain ©.
-
If an XML file is technically not correct (that is, it does not meet the formal rules it should), memoQ might have problems importing it. To get a log of the problems that happened during the import: Check the Log warnings during import check box. memoQ will list the problems in a text file. If there are warnings, memoQ will ask you to save the log file in the same folder as the original document.
An example of a log of import problems:
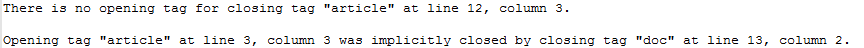
Normally, memoQ imports all text and other contents from XML files. If you need to control what is imported as text, or exclude some of the contents from the translation, use the options in the Tags and attributes tab.
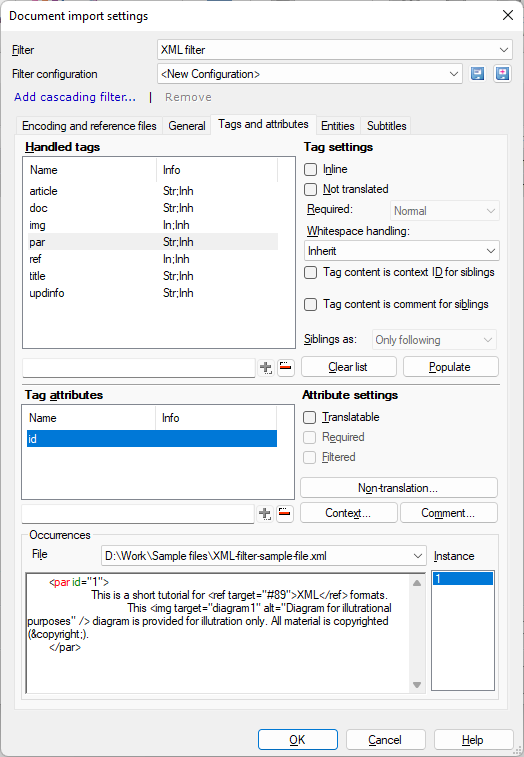
In the Tags and attributes tab, 'tags' mean elements - specific tags and the content between them. For example, when you set up translation for the Abstract 'tag', that will belong to all the content from the <Abstract> tag to the </Abstract> tag.
You can set options for each tag and attribute. To get the tags and attributes from the reference files: Click the Populate button.
To start over and choose a different set of files for previewing: Click the Clear list button. Go back to the Encoding and reference files tab. Choose different reference files. Click the Tags and attributes tab again. Click the Populate button.
While you are setting up the tags and their attributes, you can preview them at the bottom of the window in the Occurrences section.
Under Occurrences, memoQ lists the places where the selected tag occurs in one of the reference documents. Tags are highlighted in red, attributes are highlighted in green.
To choose a reference file to view: Click the File drop-down. To check one of the selected tag's occurrences in the reference file: Click the number in the Instance list.
To choose if certain tags are translated, or if they break segment, use the settings in the Tag settings section:
-
Handled tags: This list has all the tags from the XML files, as well as the ones you added. The Info column shows abbreviated settings for each tag.
 Tag setting abbreviations
Tag setting abbreviations
Some settings tell memoQ to import a tag or not:
-
In - an inline tag (doesn't break segment, imported as an inline tag)
-
Str - a structural tag (breaks segment)
-
NT - non-translated
-
Req - required
You can set whitespace handling by tag, too:
-
Inh - the tag inherits whitespace settings from its parent (the element that contains it)
-
Pres - to preserve whitespaces
-
Norm - to normalize whitespaces
Context and comment handling options:
-
Ctxt - the content of the tag is imported as a context ID
-
Com - the content of the tag is imported as a comment
-
To set these options for a tag: Click it in the Handled tags list, and choose the settings on the right as needed.
-
Inline: Check this check box to make the selected tag an inline tag. Inline tags are markup that are inside segments. Other tools may call inline tags internal tags. You can't translate the content of inline tags.
If you don't check this check box, memoQ handles the tag as a structural tag, and imports its content for translation. Structural tags never appear inside translatable text, they always start a new segment. In other tools, structural tags are called external tags.
In the example: Specify the ref and img tags as inline because they appear inside sentences. All other tags should remain structural tags.
-
Not translated: Check this check box to exclude the selected tag from translation. memoQ does not import these parts for translation.
If an element isn't translated, neither are its children: If you make an element non-translated, other elements inside it will not be imported either. In the example, do not make the xml or the doc elements non-translated because then nothing will be imported.
-
Required: Check this check box to make the selected tag required. Required tags are special inline tags that must be copied to the translation. If a required tag is missing from the translation, memoQ will display an error in the segment, and you won't be able to export the document.
Required tags are inline tags: You can't translate their content.
-
Whitespace handling: Use this drop-down to choose how whitespace is handled in that element.
-
Inherit - the element will handle whitespace the same way as the parent element. The root element receives the default setting from the General tab.
-
Preserve - memoQ retains all whitespace characters and imports them into the translation document.
-
Normalize - memoQ replaces sequences of whitespace characters with a single space character.
-
-
Tag content is context ID for siblings: Check this check box to use the selected tag's contents as the context identifier for the segment(s) imported from the elements that are on the same level in the document hierarchy.
-
Tag content is comment for siblings: Check this check box to use the selected tag's contents as a comment for the segment(s) that are imported from the elements on the same level in the document hierarchy.
-
Siblings as: Choose an item from this dropdown to decide which segments receive the context ID or the comment in the two settings above:
-
Only following: Only segments from sibling elements after the element you chose.
-
Preceding and following: Segments from all sibling elements.
-
-
 : Click this button to remove the selected tag from the Handled tags list.
: Click this button to remove the selected tag from the Handled tags list. -
 : Click this button to add the tag you entered into the text box to the Handled tags list.
: Click this button to add the tag you entered into the text box to the Handled tags list. If a tag is missing from the list: When memoQ imports an XML file, it may find tags that are not listed in the configuration. These tags will be imported as structural and translatable. They will inherit the whitespace settings from the parent element. Their content will not be imported as a comment or a context identifier.
Attributes of tags can be used as context identifiers or comments. They can also contain text to be translated.
To choose what happens to attributes:
-
Select a tag in the Handled tags list. Under Tag attributes, memoQ lists the attributes that belong to the selected tag.
Attribute settings appear as abbreviations. In the Info column of the Tag attributes list, you see the following attributes:
The xml:lang attribute is different: You cannot control how memoQ processes the xml:lang attribute – it happens automatically, based on the Change xml:lang attribute value at export setting. memoQ does not import the xml:lang attribute of inline tags, unless someone manually adds it. You can add the xml:lang attribute to inline tags, but you cannot specify any options there.
-
To change the settings of the selected attribute, use the check boxes and buttons under Attribute settings:
-
Translatable - make the selected attribute translatable. memoQ imports the attribute's value as normal text.
-
Required - the selected attribute will need to be present in any tag inserted to the translation. A required attribute is not necessarily translatable: memoQ might only use it for quality-checking and ensuring the well-formedness of the translation.
-
Filtered - hide the selected attribute when you switch to the Show filtered inline tags view in the translation editor.
-
Context - the selected attribute's value will be context information for selected tag's children or siblings. After clicking this button, the Context settings for attribute window appears with a list of options and their explanation:
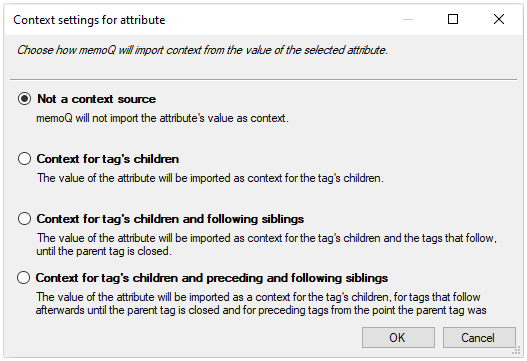
In the example: The id attribute of the par element may be used as a context identifier.
-
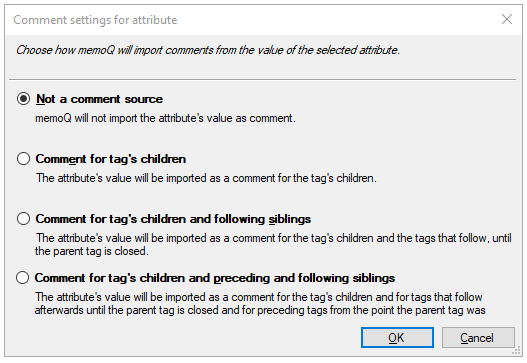
Comment - make the value of the selected attribute a comment for the children or the siblings of the selected tag. After clicking this button, the Comment settings for attribute window appears with a list of options and their explanation:
-
: Click this button to remove the selected attribute from the Tag attributes list.
-
: Click this button to add the attribute you entered into the text box on the left to the Tag attributes list.
If an attribute is missing: If an attribute is not listed in the configuration, memoQ treats it as non-translatable, not required and not filtered. These attributes will not be used for non-translation conditions, nor in context or comment processing.
You can import or ignore a tag, depending on the value of an attribute.
For example, a tag may have an attribute called translate. The value can be either translate="no" or translate="yes". You don't want to import the tags where it says translate="no".
To set conditions for importing the contents of a tag (and all its children):
- Click the Tags and attributes tab to get the list of tags from the reference documents. If needed: Click the Populate button.
- Select a tag that you want to import conditionally.
- In the Tag attributes list, select the tag that you want to use as condition.
- On the right, click Non-translation to set up the condition.
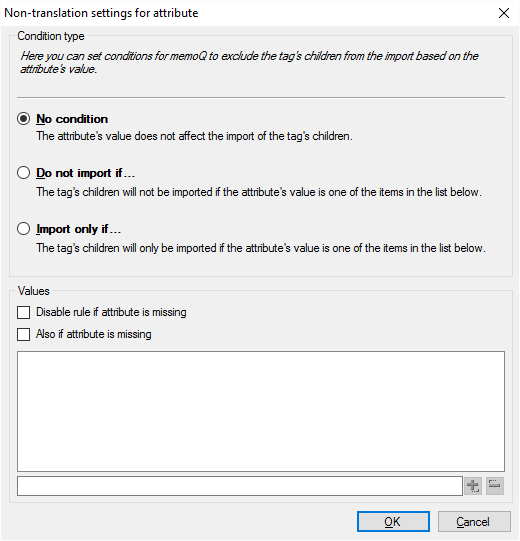
Under Values, add the values that you want to check for. If the tag has one of the values that you list, memoQ will import or ignore the tag contents, depending on the condition you set up at the top.
-
To list the values: Type a value in the text box at the bottom. Click the
button. If you need to test for several values, repeat this.If you want to check if the translate attribute is set to no, type "no" at the bottom, and click
. -
To ignore the tag if the attribute has one of the values listed: Click the Do not import if radio button. In the example, you would click this, so that memoQ omits the tags where translate="no" is set.
-
To import the tag if the attribute has one of the values listed: Click the Import only if radio button. In the example, you would add "yes" to the list (instead of "no"), and click this radio button. This causes memoQ to import the tags where translate="yes" is set.
If the attribute is missing: If you check the Disable rule if attribute is missing check box, memoQ will act as if you selected No condition. If you check the Also if attribute is missing check box, memoQ will act as if the attribute had an empty value.
XML documents contain entities - characters that can't be included in the text as they are, either because they are special characters in the XML syntax, or they don't fit in the document's encoding.
In XML text, entities look like &(entity-code);.
There are some standard entity groups that the XML standard recognizes. You can choose one or more of them. You can also set up custom entities that are specific to the documents you are importing.
On the Entities tab, you can tell memoQ which entities it should import as normal characters. That's how you will see them in the translation editor. But when exporting the translation, memoQ exports these characters as entity codes again.
To do this, use the settings on the Entities tab:
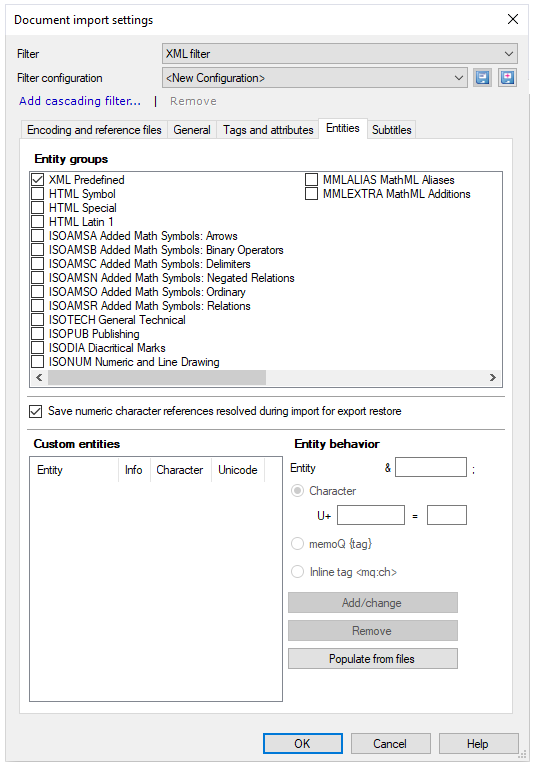
Here are the settings you can use:
-
Entity groups: In this list, you can select standard groups of entities which should be converted during import. XML Predefined entities (&, <, >, ", and ') are always handled.
-
Custom entities: In this list, you can specify non-standard entities that are specific to your document type. Custom entities can be handled in the translation editor as inline tags, memoQ formatting tags, or “normal” Unicode characters. You choose which one of the three radio buttons under Entity behavior to use.
-
To add a new entity to the list, type it in the Entity field.
-
To change the settings of an existing entity, select the entity in the Custom entities list. In the sample document, there is one custom entity, ©right;, which should be converted to © for translation.
-
-
Add/change: Click this button to add a custom entity to the Custom entities list. If you are modifying an existing custom entity, this saves your changes.
Note: In the first field under the Custom entities list, you can enter the entity appearing in your document between & and ;. Using the radio buttons, you can select whether this entity should be treated as a character or as a tag. If the entity should appear on the translation grid as a character, enter its Unicode code into the second field or enter the character into the third field.
- Remove: Click this button to remove the selected custom entity from the Custom entities list.
- Populate from files: Click this button to extract all custom entities that occur in any of the reference files. All custom entities re-appear in the Custom entities list.
When importing TTML files, memoQ finds information about the "begin" and "end" attribute in the .ttml file, reads them, and displays subtitles according to that information.

To set up length limits: In the Document import settings window, click the Subtitles tab.
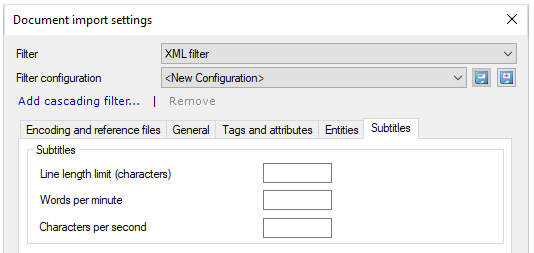
When you are working on a video translation, it is important to know how much text you can put on the screen at once. Change the value of the Line length limit (characters) field as needed.
Density means how much text is on the screen over time. You can set limits for Words per minute and Characters per second - the two most common measurements.
No warnings in memoQ itself during translation: when you confirm a segment, memoQ does not warn you if you are over these limits. You see which lines are longer than the limit only when you export the file.
However, the memoQ video preview tool shows all three values in real time when playing the video:
When the Translations pane opens, double-click the file you need to work on. It opens together with the memoQ video preview tool.
To tell the video preview tool where to find a video: Enter the URL into the Set video for... field.
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
In the Document import options window: Click OK again to start importing the documents.
When some parts have been translated, the translation document should look like this:
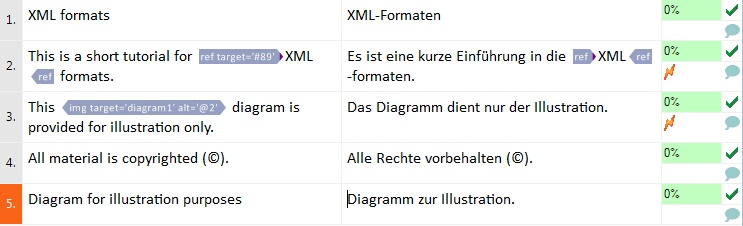
Things to mark on this screenshot:
- The text Aug-04-2006(NOT TO BE TRANSLATED) is missing from the document because the updInfo attribute was designated as non-translated.
-
The text Diagram for illustration purposes appears as a separate segment, and alt="@2" in the img tag in segment 3 indicates that the translatable attribute's value can be found two segments lower in the translation document.
Translatable attributes are collected and stored during the import process of the document, and inserted in the translation document at the position where the current block of content ends – that is, at the next structural tag.
- The opening tag ref was inserted in the target cell of segment 2 without the required attribute target, so memoQ shows a warning.
- The placeholder tag img is missing from the target cell of segment 3, so memoQ shows a warning.
- The entity '©right;' has been converted to '©' in segment 4.