Regex tagger
The Regex Tagger can turn parts of the imported text into inline tags. You may want to do this to preserve parts that look like code, placeholders, or XML tags - so that they are not altered during translation. Practically, you can do this to parts of text that belong to the structure rather than the contents.
There are three clear advantages of turning some parts of the text into tags:
- They can't be changed during translation - you can't break program code by changing placeholders or tags accidentally.
- They are easy to copy: During translation, in the translation editor, press F9 or Ctrl to copy tags from the source cell.
- They give better matches from the translation memory: If tags are different, you can still get a close-to-exact match. For example, your text may contain a placeholder that looks like '{{number}}'. If it isn't tagged in the text, and there is a TM match where the placeholder is different, the match rate will be below 90 percent. But if these placeholders are tagged both in the text and the TM, the match rate will be higher than 95%.
Save more: Tagging structural parts of the text may allow you to save time and money.
The Regex Tagger uses regular expressions to find the parts that need to be tagged (as the name suggests).
You can't import documents into memoQ with the Regex Tagger alone. But it can be the second or third filter in a cascading filter.
Use Regex Tagger or Regex taggers after another filter: For example, a cells in an Excel workbook may contain tags that must not be altered. You can set up a cascading filter where the second - or last - filter is the Regex Tagger. At the end of the chain, you can add a sequence of Regex taggers, to tag the document several different ways.
Tag text directly in the translation editor: During translation, if you discover that something needs to be tagged, you don't have to import the document again. You can run the Regex Tagger directly from the translation editor. It's on the Preparation ribbon.
How to get here
- Start importing a document (any monolingual format).
- In the Document import options window, select the documents, and click Change filter and configuration.
- The Document import settings window appears.
- Below Filter configuration, click the Add cascading filter link.
- The Select filter to chain window appears. From the Filter drop-down box, choose Regex tagger. Click OK.
- In the Document import settings window, the filter chain appears below the cascading filter controls. Click Regex tagger.
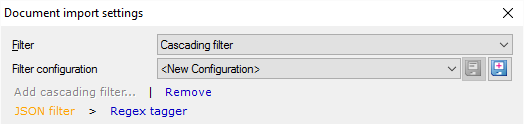
- The Regex tagger controls appear.
- Open a project, and a document for translation.
- In the Preparation ribbon, click Regex Tagger.
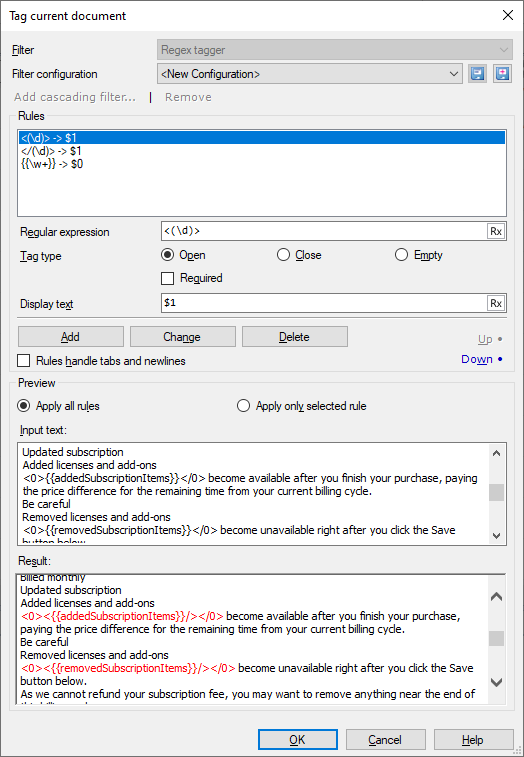
- The Tag current document window appears. It's the same as the Regex tagger settings in the Document import settings window.
What can you do?
Most of this window is for writing and testing regular expression rules that memoQ uses to find parts of text that are replaced with inline tags. After you write up rules like this, you can save them as a filter configuration. You can also load a set of rules that was saved earlier.
To load an existing set of patterns: Choose one from the Filter configuration dropdown.
To save the rules you just created: In the Filter configuration dropdown, choose <new configuration> , and click the Save ![]() icon next to it. The Create new filter configuration window appears, where you can give a name to the new set of rules.
icon next to it. The Create new filter configuration window appears, where you can give a name to the new set of rules.
You can set up several rules in a single regular expression filter configuration. These are listed in the top box of the Rules section.
To add a pattern, first type a regular expression in the Regular expression text box. This can be a simple expression: for example, if you want to replace the word 'memoQ' with an inline tag, simply type 'memoQ' in the Regular expression text box.
You can also enter more complex expressions where a simple pattern can represent several different character sequences. If you need assistance, open the Regex Assistant: Click the ![]() icon on the right, and create a regex, or choose one from the regex library. Copy it, then switch back to this window, and paste your regex into the Regular expression text box.
icon on the right, and create a regex, or choose one from the regex library. Copy it, then switch back to this window, and paste your regex into the Regular expression text box.
For example, the regular expression <[^/]*?> matches text that starts with the < character, followed by the shortest possible sequence of characters that does not contain the / character, and ends in a > character. In short, text that matches this pattern looks like an XML opening <tag>.
To learn more about regular expressions: See the topic about Regular expressions.
After you type the regular expression, choose what type of tag you want to see in the place of the text. You can choose to use an opening tag ![]() , a closing tag
, a closing tag ![]() , or an empty tag
, or an empty tag ![]() . These correspond to the types of tags commonly used in XML markup.
. These correspond to the types of tags commonly used in XML markup.
If you check the Required check box, memoQ will add a tagging error to a segment if you don't copy the corresponding tag to the target text in the translation editor.
In the Display text text box, you can specify what memoQ should write inside the tag. This is called a replacement rule, and you also use these in auto-translation rules. You can write any text here, but you can also use the pre-defined $0 expression: if the replacement rule is $0, the tag will contain the text that memoQ found when matching the pattern.
Note: If the regular expression contains several non-fixed parts, you can use $1, $2 etc. to refer to the first, second etc. non-fixed part in the replacement rule. You can choose from available options if you click the Pattern link next to the Display text box.
After you fill in the Display text box, click Add to add the rule to the list.
To modify an existing rule, click the rule in the list, and click Change.
To remove a rule from the list, click the rule, and click Delete.
If you want the Regex Tagger to work on tabs and newlines, too, check the Rules handle tabs and newlines check box.
Dealing with tabs and newlines: A segment in memoQ never contains tabs or line breaks. If they appear, they are represented by a type of a tag. But when you need to import a text-based document (TXT, HTML, XML etc.), you may want to tag newlines and tabs yourself. Normally, the filters before the Regex Tagger will have already converted these characters into a tag. But then you do not have the chance to tag them yourself. To work with tabs and newlines in the Regex tagger, check the Rules handle tabs and newlines check box. Then the filters before the Regex tagger will not touch the tabs and newlines (they won't convert them into tags). But then need to make sure that you tag the tabs and newlines with the Regex Tagger. If you do not tag them, memoQ won't import the document.
The lower part of the window shows how the rules work. After you fill in or edit the Rules list, the Input text box shows what parts of the original text will match your patterns. The Result box shows how memoQ tags them. Matches and replacements are highlighted in red.
Normally, the Input text and Result boxes highlight the matches from all patterns. If you want to see highlights from one rule only, click the Apply only selected rule radio button, then click a rule in the Rules list.
The order of the rules matters: Click the Up and Down buttons to move rules up and down. This can be useful if two patterns match the same paragraph, and the parts they match are overlapping.
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window.
In the Document import options window: Click OK again to start importing the documents.
To confirm the settings, and return to the translation editor: Click OK. memoQ starts to tag the document.
To return the translation editor, and not tag the document: Click Cancel.