Translation memory CSV import settings (dialog)
memoQ can import tabular text files – tab-separated or CSV files - into translation memories. These files contain rows and columns, but the columns are not always the same as the fields in a translation memory.
Most of the time, the file you import will have different columns than the fields in a translation memory.
Sometimes the columns have names, and sometimes they do not. In the Translation memory CSV import settings window, memoQ gives you means to convert the columns to translation memory fields, no matter whether they have names or not.
If you import a text file, even the character encoding can be a question. The Translation memory CSV import settings window offers a preview where you can check if every character appears as it should.
How to get here
- Open a project. In Project home, choose Translation memories.
From the Resource console: Open the Resource console. Choose Translation memories.
From an online project: As a project manager, you can open an online project for management. In the memoQ online project window, choose Translation memories.
- If you need the translation units from one CSV file in a new translation memory, create a translation memory first. If you import two or more CSV files, you can create the new translation memory in the Import TM files wizard.
- Right-click the name of the translation memory you need to import the terms into. From the menu, choose Import.
-
An Open window appears. Find and select the CSV files you need to import. Click Open.
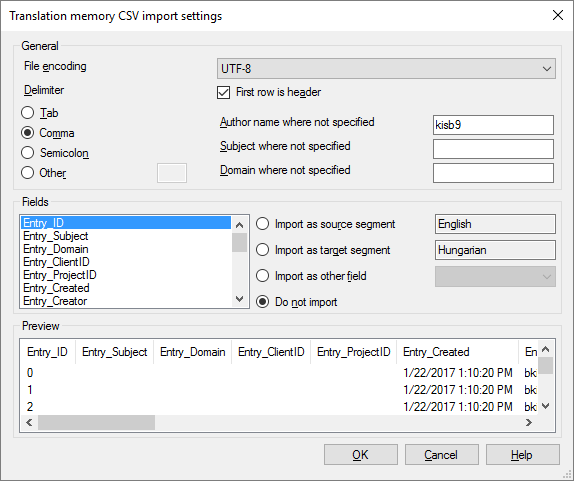
If you opened one file, the Translation memory CSV import settings window opens.
If you opened two or more CSV files, the Import TM files wizard opens. On its last page (Review import settings):
- To choose import settings for one of the CSV files: Click the Change settings link for that file. The Translation memory CSV import settings window opens.
- To choose common import settings for two or more CSV files: Select those files, and click the the Change import settings of selected link. The Translation memory batch CSV import settings window opens:
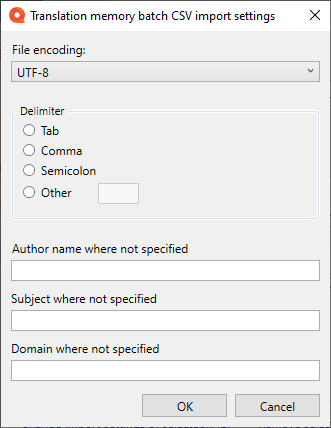
This window contains only those settings that can be applied to all the selected CSV files.
What can you do?
Nowadays, characters are almost always encoded in Unicode - which can encode practically any character or symbol.
Plain-text files may use simpler, older encodings. If the file you import is not Unicode, memoQ will warn you before the Translation memory CSV import settings window opens.
At the bottom, check the Preview box if every character appears as it should. If not, choose a different encoding from the File encoding drop-down box (at the top). You may need to experiment until the characters appear correctly.
memoQ will choose a delimiter character from the file. In a tabular text file, the delimiter character separates the columns (cells) from each other.
Under Preview, check if the columns appear correctly.
If they do not, you may need to choose another delimiter.
Click Tab or Comma or Semicolon or Other. If you click Other, type exactly one character in the box next to it. In this box, type the delimiter character that you expect in the file.
After you choose the other delimiter character, check the Preview box again.
memoQ imports each row from the table in a new entry in the translation memory.
Each column can be imported in a field in the translation memory.
If the file has column headers, select the First row is header checkbox. It will be easier to match columns to translation memory fields.
To match the columns and the fields to each other, use the settings under Fields.
For each field, you can select how it should be imported. A field is a column in the table. Under Fields, you can match (or not match) fields in a CSV file to fields of a term base entry. (You can omit fields from the CSV file.)
- Fields list: Go through every field name listed, and select how they should be imported. All changes in the controls to the right apply to the field that is currently selected in this list.
- Import as source segment: Click this to import the contents of the selected field as the source segment in the language you specify. If there is a column where the header is the English name of the source language of the translation memory, memoQ will automatically match it.
- Import as target segment: Click this to import the contents of the selected field as target segment in the language you specify. If there is a column where the header is the English name of the target language of the translation memory, memoQ will automatically match it.
- Import as other field: Click this to import the contents of the selected field as Subject, Domain, Client, Project, Author, or Modify. (These are the regular descriptive fields of a project or a translation memory, and they can be there in every entry in the translation memory.)
- Do not import: Click this if you do not want to import the contents of the selected field.
If these details are missing from the text file, you can still add them to the new entries.
Type the details in the Author name where not specified, Subject where not specified, and Domain name where not specified boxes.
If these details are there in the text file: memoQ will use those, not the ones you type here.
When you finish
To import the text file in the translation memory, and return to Project home or to the Resource console: Click OK.
To return to Project home or to the Resource console, without importing entries: Click Cancel.