Filter for TM duplicates
You can clean the translation memory from duplicate entries.
You may end up with a lot of duplicates if you do one of the following:
- Confirm a lot of identical translations to it, using different contexts.
- Use a translation memory that allows several translations for the same source segment and the same context.
- Use a translation memory without context information.
- Import TMX files into the translation memory with many identical source segments.
- Confirm a lot of non-textual segments (all-number segments, or segments made up from dashes etc.).
In the Filter for duplicates window, you can start looking for the duplicates in your translation memory. You can run this on one translation memory at a time.
In the end, memoQ gives you groups of entries. Entries in the same group are duplicates of each other in a way or another - according to the condition you set up in the Filter for duplicates window.
How to get here
- Start editing a translation memory.
-
On the Translation memory editor ribbon, click Remove Duplicates. The Filter for duplicates window appears.
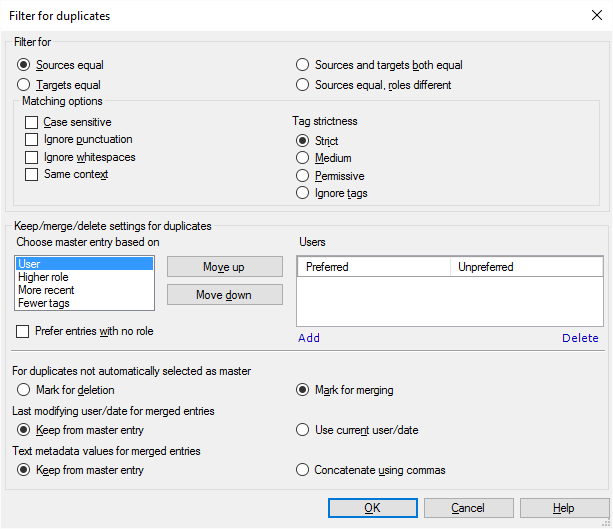
What can you do?
Two entries are usually duplicates of each other if the source text is the same in both of them.
- Under Filter for, you can fine-tune this. You have radio buttons to make your choice.
To clean up your translation memory from unedited, unapproved translations: Click Sources equal, roles different. This will get you the entries where the same segment was confirmed by a translator and also by a reviewer. In that case, you will want to keep the one confirmed by a reviewer.
- Sources equal: entries are duplicates if the source text is the same in both of them
- Targets equal: entries are duplicates if the target text is the same in both of them
- Sources and targets both equal: entries are duplicates if both the source and the target text is the same in them.
- Sources equal, roles different: entries are duplicates if the source text is the same in them, but the role in which they were confirmed are different. For example, one may have been confirmed by a Translator, and the other by a Reviewer 2. Use this to get rid of unedited translations in the translation memory.
- Next, choose how the segments are compared; what counts as 'same'. Decide how strict you want to be about this. To set this up, use the checkboxes and radio buttons under Matching options. Normally, all these checkboxes are cleared, which means that two segments are the same if they have the exact same words, tags, spaces, and punctuation. The context of the source segment, and lowercase and uppercase can be different.
- To make the checking case-sensitive, so that uppercase and lowercase must also be the same: Select the Case sensitive checkbox.
- To accept two segments as identical even if the punctuation is different: Select the Ignore punctuation checkbox.
- To accept two segments as identical even if the spaces are different: Select the Ignore whitespaces checkbox.
- To accept two source segments as identical only if the contexts are the same: Select the Same context checkbox.
- Permissive means that only the number of tags need to be the same.
- Medium means the tags must have the same type (open/close/empty), but tag names and attributes can be different. At first, memoQ uses this setting.
- Strict means that tags must be precisely the same.
You can fine-tune this under Keep/merge/delete settings for duplicates.
In a group of duplicate entries, one will always become the 'master' entry. You can decide what happens to the other entries in the group:
- Delete them
- Merge extra details from them into the master entry
- Keep them, so the duplicate remains
You can make your choice for each group when you're back in the translation memory editor.
First, memoQ needs to decide which entry is the master in the group. Choose one from the Choose master entry based on list: User, Higher role, More recent, Fewer tags. For example, your master entry will be one that was added by a certain user. Normally, memoQ follows this logic:
- The master entry will be the one that comes from a preferred user.
- If there is not one entry with a preferred user: Choose the one that was confirmed in the higher role. For example, Reviewer 2 is higher than Translator, and Translator is higher than a entry with no role. In fact, you can make the entries with no role the highest ones: To do that, select the Prefer entries with no role checkbox.
- If there is not one entry that has the highest role: Choose the most recent one.
- If there are several entries from the same time: Choose the one that has fewer tags in the source and the target segment.
You can change the order of these. Click a condition, and click the Move up or the Move down button.
In the Users list, you can list the preferred users. These will be senior people - reviewers -, who regularly confirms segments in the Reviewer 1 or the Reviewer 2 role. To add a preferred user, click Add. To remove a user from the list: Click the name of the user. Click Remove.
You can add unpreferred users, too. If you have a list of unpreferred users, other users will be preferred to them. For example, if the duplicate group has four entries from unpreferred users, and one from a user who's not on the list, memoQ will choose this fifth one as the master entry.
Then, choose what happens to those entries that are merged into the master entry.
You can add more than one user to these lists, if their user names start with the same characters. For example, if all translators have user names like tr-jp1, tr-fr3, tr-de1, you can add all of them to the Unpreferred list. Click the Add link: In the Add preferred/unpreferred user window, select the This is a user name prefix checkbox. Enter tr- into the User name box,and click OK. The Unpreferred column now has a line "tr-*". This means that memoQ treats all users whose user name begins with "tr-" as unpreferred users.
- For duplicates not automatically selected as master: Either click Mark for deletion or Mark for merging. Normally, memoQ marks the non-master entries for merging into the master entry.
Don't choose Mark for deletion unless you are absolutely sure that the duplicate entries are completely identical, same segments, same tags, same context, same fields. In all other cases, you should choose Mark for merging. Otherwise you'll lose information from the translation memory.
- Last modifying user/date for merged entries: Choose if the modification date and the last modifying user should come from the master entry - or from the current editing session. Either click Keep from master entry or Use current user/date. You can't keep dates and users from the non-master (merged) entries.
- Text metadata values for merged entries: If the metadata fields have conflicting contents in the master entry and in the non-master (merged entries), choose what should happen. You can use the value from the master entry, or you can use all of them, appended together with commas. For the former, click Keep from master entry. For the latter, click Concatenate using commas.
When you finish
To look for all the duplicates, and return to the translation memory editor: Click OK.
To return to the translation memory editor, and not look for the duplicates: Click Cancel.
After memoQ finds the duplicates, it displays a special list that contains the groups of duplicates, and not the individual entries.
To learn more: See the documentation about the translation memory editor.