PO Gettext ファイル
POファイルはローカリゼーションファイルで、主にUnixコンピュータで多言語プログラムを記述するために使用されます。PO Gettextファイルはバイリンガルで、単一のソース言語とターゲット言語を含むことができます。
memoQはPO Gettextファイルを直接作業できます。エクスポートされたファイルはバイリンガルです。
操作手順
-
文書のインポートオプションウィンドウでPO Gettextファイルを選択し、フィルタと構成を変更をクリックします。
-
文書のインポート設定ウィンドウが表示されます。フィルタドロップダウンリストからPO Gettext フィルタを選択します。
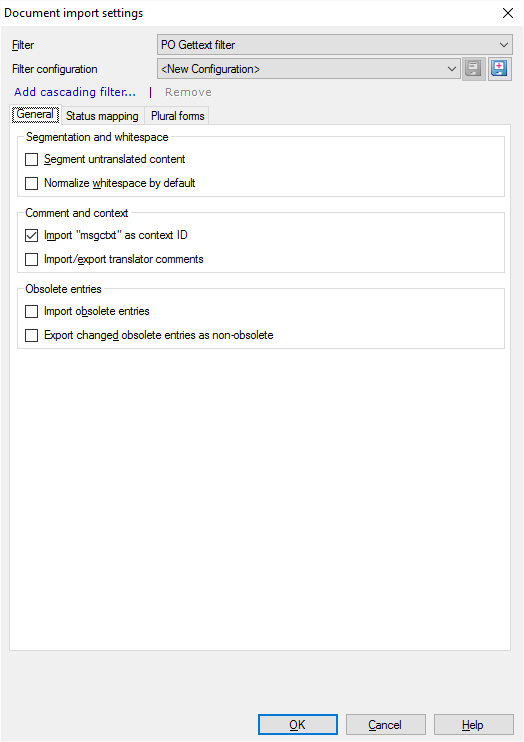
その他のオプション
-
通常、memoQは翻訳されていないテキストをセグメントに分割しません。POファイルはエントリから構成されます。各エントリは、センテンスの数に関係なく、1つのセグメントになります。エントリをセグメントに分割するには:セグメントと空白の未翻訳のコンテンツをセグメント化チェックボックスをオンにします。
-
通常、memoQでは、PO Gettextファイルをインポートするときに、スペース (ブレークとノーブレーク)、タブ、改行文字を変更しません。しかし、memoQはそれらを正規化することができます:タブ、スペース、ノーブレークスペース、改行文字のシーケンスを1つのスペース文字に変換できます。ホワイトスペースを正規化すると、memoQはエントリの先頭と末尾のホワイトスペースも削除します。スペースを正規化するには:既定で空白を標準化チェックボックスをオンにします。
例:
正規化前:
This is a
test, with a lot of spaces.
正規化後:
This is a test, with a lot of spaces.
-
PO Gettextファイルでは、各エントリに「msgctxt」という属性があります。通常、memoQはこの属性をセグメントのコンテキストとしてインポートします。コンテキストが不要な場合は、"msgctxt" をコンテキスト ID としてインポートチェックボックスをオフにします。
-
通常、memoQはPO Gettextファイルからコメントをインポートしません。コメントをインポートするには:翻訳者のコメントをインポート/エクスポートチェックボックスをオンにします。
コメントがインポートされていない場合は、それらはエクスポートされません:PO Gettextファイルからコメントをインポートしない場合、memoQは翻訳者が作成したコメントをエクスポートしません。エクスポートしたファイルに翻訳者またはレビュー担当者のコメントを表示する場合は、ソースファイルにコメントがない場合でも、このチェックボックスをオンにします。
-
PO Gettextファイルでは、ローカライズされるプログラムに表示されない古いエントリ、または翻訳されるべきでないエントリが使用されます。通常、memoQではインポートしません。
- 古いエントリをインポートするには:古いエントリをインポートチェックボックスをオンにします。
- 通常、古いエントリをインポートすると、それらの翻訳は古いものになります。しかし、それらを再びアクティブにすることができます。そのためには、変更された古いエントリを古くないエントリとしてエクスポートチェックボックスをオンにします。
POファイルのエントリの構造は次のとおりです:
ホワイトスペース
#. extracted-comments
#: reference...
#, flag...
#| msgid previous-untranslated-string
msgid untranslated-string
msgstr translated-string
-
msgid untranslated-stringはソースとしてインポートされ、msgstr translated-stringはターゲットとしてインポートされます。msgidとmsgstrフィールドには、翻訳ユニットのソース文字列とターゲット文字列が含まれます。msgidエレメントはPOドメイン内で一意です。
例:
.
msgid " "
"memoQ Zrt. is "
" "
"%s. \n"
"What is"
" "
"the company about?"
は下記と同じです:
msgid "memoQ Zrt. is %s. \n What is the company about?" - msgctxtエレメントはコンテキストIDとしてインポートされます。#| msgidエレメントは廃止としてマークされます。
- # フラグエレメントは保持されます。フラグは、翻訳ユニットの状態 (例えば、完了またはファジー) を示すために使用されます。ファジーフラグは、(状況マッピングタブ上の) memoQセグメントステータスにできます。複数のフラグはコンマで区切ります。
- # translator-commentsは、ファイルのインポート時にmemoQコメントとしてインポートおよびエクスポートできます。これらのコメントは翻訳者によって追加され、POファイルには存在しません。コメントは、extracted-commentsとreference commentsの前に挿入されます。
- # extracted-commentsと# reference commentsフィールドは構造内に保持されます。これらはmemoQによって変更されません。Extracted commentsエレメントは、ソース文字列と同じ行またはその前の行にある場合、ソースコードから抽出されます。Reference commentsエレメントは、スペースで区切られた場所のリストで、翻訳ユニットがソースファイル内のどこにあるかを指定します。1つの翻訳ユニットに複数の参照 (ロケーションごとに1つ) を含めることができます。
- 古いエントリとは、POファイルが更新された時にコメントアウトされるエントリです。たとえば、翻訳対象でないテキストは廃止されます。通常、msgmergeエレメントはエントリをコメントアウトする (廃止にする) ために使用されます。古いエントリは#~でマークされます。
PO Gettextファイルのエントリには、2つのステータス値があります:fuzzyとnon-fuzzy。これらをmemoQにインポートしたり、PO Gettextファイルにエクスポートしたりするには、状況マッピングタブをクリックします。
- 通常、memoQはファイルをインポートするときにGettextステータスをインポートしません。そのためには、インポート時に gettext 状況をマッピングチェックボックスをオンにします。
- この場合も、memoQがPO Gettextファイルをエクスポートするとき、最初はmemoQステータスをエクスポートしません。そのためには、エクスポート時に memoQ 状況をマッピングチェックボックスをオンにします。
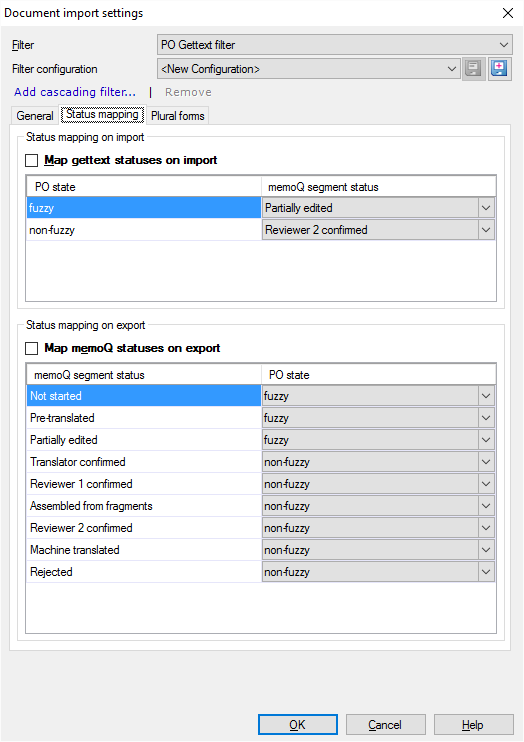
memoQがPO Gettextファイルをインポートすると、ファイルから読み取ったステータスがわかります。
- 通常、「fuzzy」エントリは部分的に編集済み (編集済み) としてインポートされます。これを変更するには、「fuzzy」の横にあるドロップダウンボックスから別のステータスを選択します。
- 通常、「non-fuzzy」エントリはレビュー担当者 2 確定済みとしてインポートされます。これを変更するには、「non-fuzzy」の横にあるドロップダウンボックスから別のステータスを選択します。
memoQがPO Gettextファイルをエクスポートするとき、各セグメントの状態は「fuzzy」または「non-fuzzy」としてエクスポートされます。
通常、開始前、前翻訳済み、および部分的に編集済み (編集済み) セグメントは「fuzzy」としてエクスポートされます。その他のすべては「non-fuzzy」としてエクスポートされます。これを変更するには、下部のリストにある1つまたは複数のドロップダウンボックスから別のステータスを選択します。
エントリに数値プレースホルダが含まれている場合、複数のフォームがソース言語またはターゲット言語で異なる場合、PO Gettextファイルにテキストのバリエーションを含めることができます。
これは複数形タブで設定できます。バリエーションを許可するには:複数形エントリを調整チェックボックスをオンにします。
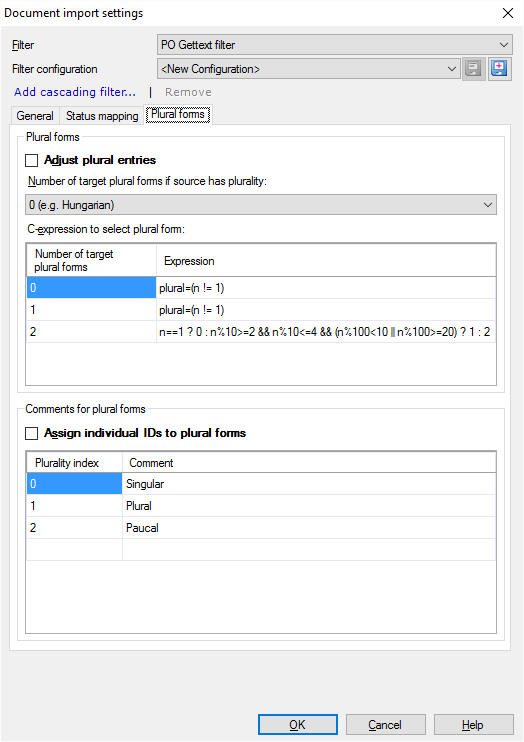
実際のエントリでは、単数形と複数形は次のようになります:
#: src/msgcmp.c:338 src/po-lex.c:699
msgid "found %d fatal error"
msgid_plural "found %d fatal errors"
msgstr[0] "s'ha trobat %d error fatal"
msgstr[1] "s'han trobat %d errors fatals"
ソース言語の複数形の数を選択します。ソースに複数形がある場合のターゲットの複数形の数ドロップダウンリストで、0を選択できます(例:ハンガリー語)、1 (例:ラテン言語)、または2 (例:スラブ言語)。
各フォームの横にある式は、どの複数形をいつ使用するかを示しています。これは、C式を使用して設定できます。C式は、Cプログラミング言語の構文に従う条件式です (ここでは詳しく説明しません)。
それぞれの複数のタイプは名前を持つことができます。これらの名前を使用するには:複数形に個別に ID を割り当てるチェックボックスをオンにします。スクリーンショットに表示されている名前が自動的に表示されます。各名前をクリックして変更します。
複数形に個別に ID を割り当てるチェックボックスをオンにすると、この情報がmsgctxt (コンテキスト) 属性に追加されます。そうしないと、2つのターゲット複数形があり、ソースとコンテキストIDが両方で同じになる可能性があります。この場合、コンテキストは、複数の情報が存在しない限り、2つの異なる単位として翻訳メモリに格納するのに十分な情報を提供しません。
完了したら
-
設定を確定して文書のインポートオプションウィンドウに戻るには:OKをクリックします。
文書のインポートオプションウィンドウで:OKを再度クリックすると、ドキュメントのインポートが開始されます。
-
文書のインポートオプションウィンドウに戻り、フィルタ設定を変更しない場合:キャンセルをクリックします。
-
重ねがけフィルタの場合は、チェーン内の別のフィルタの設定を変更できます。ウィンドウの上部にあるフィルタの名前をクリックします。
バイリンガルフィルタとマルチリンガルフィルタの後にフィルタを連鎖させることができます。たとえば、多言語Excel、および区切り記号付きテキストは、重ねがけフィルタの最初のフィルタにすることができますが、正規表現タグ化ツールは常に最後に適用されるべきです。