正規表現テキストフィルタ - 構造化テキストファイル
正規表現テキストフィルタでは、memoQは構造化されたテキストファイルをインポートし、そこから翻訳可能なコンテンツを抽出できます。memoQは、インポートされたコンテンツのコンテキストとコメントを抽出することもできます。
構造化テキストファイルの簡単な例を次に示します:
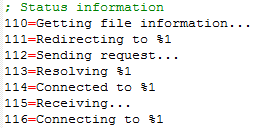
主に正規表現を使用して正規表現テキストフィルタを制御できます。
正規表現テキストフィルタは、次の3つのステップで構造化テキストファイルを処理します:
- ファイルを段落に分割します。
- 翻訳用テキストを含む段落を識別して抽出します。
- 抽出された段落から、翻訳用テキスト、およびオプションでコンテキストとコメントが抽出されます。
フィルタのオプションは、次の3つの手順に従います:
- 段落の区切り方を指定する必要があります。
- インポートした段落の外観を記述します。
- 実際に翻訳する必要があるパーツをリストします。
この手順では、正規表現を作成する必要があります。これは、多少の試行錯誤が必要になる場合があります。その間、memoQでは、何がどのようにインポートするかを示すプレビュータブが表示されます。
正規表現が必要です:これは、段落またはその部分が一致しなければならないパターンを記述する方法です。memoQでは、Microsoft.NETファッションの正規表現を使用しています。.NET正規表現の一般的な説明については、Microsoftのドキュメントを参照してください。memoQでの正規表現の使用例については、正規表現の記事を参照してください。
操作手順
- 構造化テキストファイルのインポートを開始します。
- 文書のインポートオプションウィンドウでテキストファイルを選択し、フィルタと構成を変更をクリックします。
- 文書のインポート設定ウィンドウが表示されます。フィルタドロップダウンリストから正規表現テキストフィルタを選択します。
設定を受け取る場合があります:別のユーザーから事前定義された正規表現設定を受け取った場合、またはmemoQ TMSで使用可能なフィルタ構成が手元にある場合は、フィルタ構成ドロップダウンからフィルタ構成を選択できます。この場合、ダイアログボックスで設定を変更する必要はありません。
その他のオプション
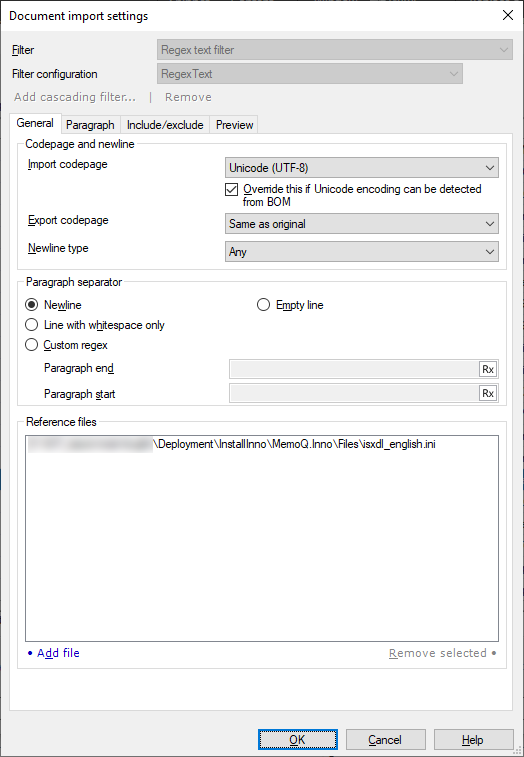
一般タブでは、ドキュメントのインポートとエクスポート用コードページのを設定できます。また、段落の区切り方を指定したり、memoQがプレビュータブでプレビューを表示するために使用する参照ファイルを追加することもできます。
コードページと改行セクションで、インポートおよびエクスポートのコードページを設定できます。
- インポート用コードページドロップダウン:ソースファイルのエンコーディングを選択します。通常、memoQはUnicode (UTF-8)を使用しますが、実際のファイルは異なる場合があります。プレーンテキストエディタでファイルを見る必要があるかもしれません。しかし、ファイルがバイトオーダーマーク (BOM) で始まる場合、memoQはそれを使用してエンコーディングを検出します。エンコーディングを自分で設定する場合は、BOMからUnicodeエンコードが検出された場合は無効化チェックボックスをオフにします。
- エクスポート用コードページドロップダウン:翻訳されたドキュメントをエクスポートするときにmemoQが使用するエンコーディングを選択します。通常、memoQはソースドキュメントと同じエンコーディングを使用します。ただし、別のエンコーディングを選択しなければならない場合もあります。たとえば、ソースエンコーディングがUnicodeではなく、フランス語から日本語に翻訳する場合に必要です。
- 改行の種類ドロップダウン:元のファイルでmemoQが検索する改行の種類を選択します。通常、memoQはあらゆる種類の新しい行を検出します (Windows、Linux/Unix、Macは異なるものを使用しています)。特定のタイプを選択する必要がある場合があります。これは、改行のように見える文字シーケンスを1つにしてはならない場合です。
テキストエディタは、エクスポートされたファイルのエンコーディングを検出できない場合があります:テキストエディタはエクスポートしたファイルを最初は正しく開かないことがあるので、エクスポート用エンコーディングに注意してください。これは、プレーンテキストファイルのエンコーディングを簡単に検出できないためです。ほとんどのテキストエディタでは、エンコーディングを手動で設定できます。
段落区切り記号セクションでは、段落を区切る方法をmemoQに指示できます。
- 改行(W)ラジオボタン:ファイル内の1行が1つの段落になる場合にクリックします。ほとんどの場合、構造化テキストファイルはこれになります。
- 空の行ラジオボタン:一部の構造化テキストファイル形式 (LaTeXなど) では、段落は複数行にまたがり、空の行で終わります。複数行の段落を含むファイルを処理する場合は、これをクリックします。
- 空白文字だけの行ラジオボタン:段落が複数の行で構成され空の行で終わる場合に、このオプションをクリックします。ただし、空の行には空白文字 (スペース、タブ) が含まれている場合があります。
-
カスタム正規表現ラジオボタン:段落が改行文字または空の行で区切られていない場合にクリックします。段落が複雑な場合は、段落の終わりと始まりを示す正規表現を作成できます。
このラジオボタンをクリックした場合は、パラグラフの末尾とパラグラフの先頭テキストボックスに正規表現を記述する必要があります。正規表現は、段落の末尾と先頭に一致させる必要があります。パラグラフの末尾テキストボックスには、次の段落の先頭と重複するパターンを含めないでください。また、パラグラフの先頭テキストボックスには、前の段落と重複するパターンを含めないでください。
サポートが必要な場合は、正規表現アシスタントを開きます:右側の
 アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
参照ファイルセクションでは、memoQがプレビュータブに表示するファイルを追加できます。memoQは、インポートするファイルを自動的に追加します。
- 新しいファイルをリストに追加するには:ファイルの追加リンクをクリックします。
- リストからファイルを削除するには:名前をクリックして、選択した項目を削除リンクをクリックします。
パラグラフタブでは、正規表現ルールを指定できます。各ルールは段落全体に一致する必要があります (つまり、段落全体をカバーする正規表現を記述する必要があります)。ルールが段落に一致する場合、memoQはその段落からテキストをインポートします。パラグラフタブでは、段落のどの部分をインポートするかを指定することもできます。
サポートが必要な場合は、正規表現アシスタントを開きます:右側の![]() アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
このタブでルールを指定しない場合、memoQはすべての段落を翻訳対象としてインポートします。
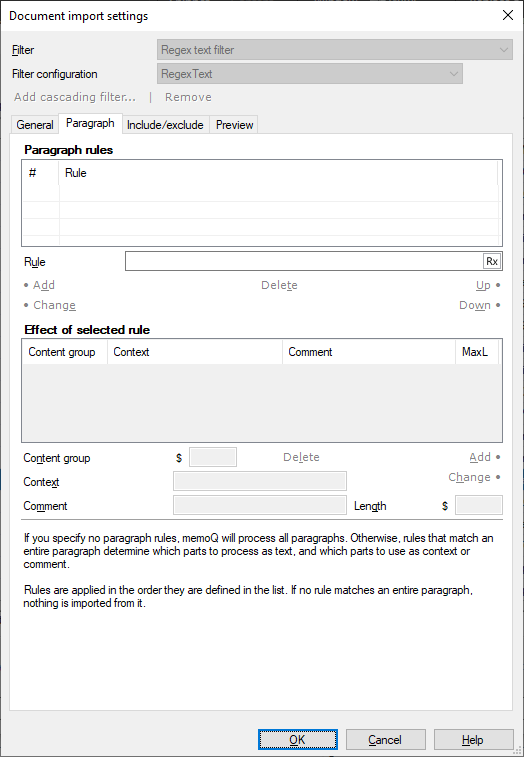
パラグラフルールテーブルを使用して、段落全体に一致する正規表現をリストします。
-
新しい正規表現を追加するには:ルールテキストボックスに入力します。追加をクリックします。
特別な正規表現が必要です:ルールテキストボックス内の正規表現には、少なくとも1つのキャプチャグループ (つまり、括弧内の何か文字) が含まれている必要があります。また、先頭に
^(キャレット)、末尾に$(ドル記号) は使用できません。例:このページの上部にあるテキストの場合、正規表現は
(\d+)=(.+)です。これにより、memoQは、数字のシーケンスで始まり、その後に等号 (=) が続き、その後に任意の文字が続く段落を、段落の最後まで選択するようになります。 -
リスト内の既存の正規表現を変更するには:テーブル内のルールをクリックします。ルールテキストボックスを変更します。変更をクリックします。
-
テーブルから正規表現を削除するには:ルールをクリックします。削除をクリックします。
-
リスト内でルールを上下に移動するには:選択して、上または下をクリックします。これは、2つのパターンが同じ段落に一致するが、コンテンツグループが異なる場合に便利です。この場合、処理の順序が重要です。
コンテンツグループを使用して、インポートするコンテンツ、コンテキスト、およびコメントをマークします:正規表現では、括弧( )を使用してコンテンツグループをマークします。次に、コンテンツグループをその番号で参照できます。左から右へ最初のコンテンツグループは$1、2番目のコンテンツグループは$2へと続きます。
ルールごとに、段落の各部分の動作を指定できます。上のテーブルのルールをクリックします。次に、選択したルールの効果セクションの設定を使用して、どのコンテンツグループがコンテンツであるか、どのコンテンツグループがコンテキストであるかなどを指定します。選択したルールからコンテンツグループを指定します。
- リストにコンテンツグループを追加するには:コンテンツグループテキストボックスに番号を入力します。追加をクリックします。memoQは、このコンテンツグループを翻訳対象テキストとしてインポートします。コンテンツグループのコンテキストとコメントが必要な場合は、(追加をクリックする前に) コンテキストボックスとコメントボックスにその情報を書き込むことができます。固定テキストにすることもできます。ただし、コンテンツグループ参照 ($0、$1など) も使用できます。
上の例では、翻訳するテキストが2番目のコンテンツグループにあるためコンテンツグループは2です。行の先頭の数字をコンテキストとして使用する必要があるので、コンテキストは$1です。
- コンテンツグループの設定を変更するには:リスト内のコンテンツグループをクリックします。コンテンツグループ、コンテキスト、およびコメントのテキストボックスを変更します。変更をクリックします。
- リストからコンテンツグループを削除するには:リスト内でクリックします。削除をクリックします。
含める/除外するタブでは、インポートを微調整できます。パラグラフタブでは、インポートする段落の部分を指定しています。含める/除外する設定は、段落からインポートされたテキストに適用されます。
パラグラフ設定で許可されたテキストから、翻訳が必要なものと必要でないものを指定できます。
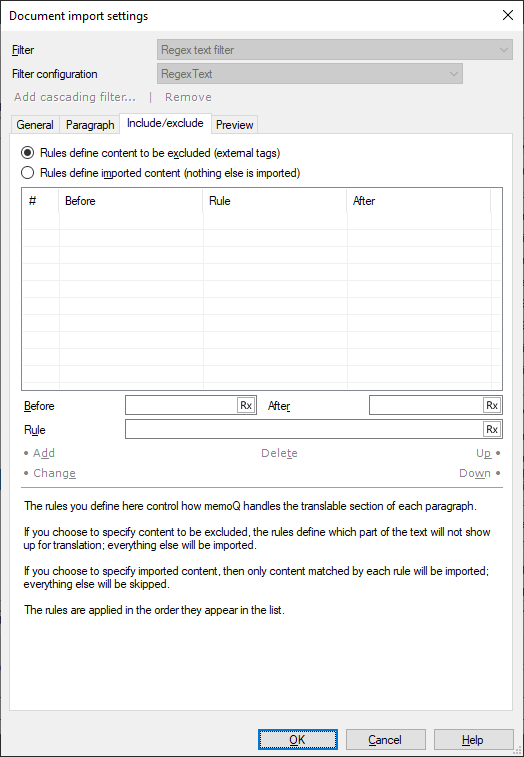
まず、ラジオボタンを使用して、以下のルールでインポートする必要のあるコンテンツを記述するか、またはルールで実際にテキストの一部を除外するかを指定します。
- インポートしたテキストで表示したくないパーツのパターンを記述する場合に除外するコンテンツの定義ルール (外部タグ)クリックします。
- インポートすべきパーツのパターンを記述する場合にインポートするコンテンツの定義ルール (他はインポートされない)をクリックします。
ルールでは、コンテンツ自体に対して正規表現を作成できます。また、コンテンツが含まれる部分または除外される部分の前後にある場合にも、正規表現を作成できます。
サポートが必要な場合は、正規表現アシスタントを開きます:右側の![]() アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
アイコンをクリックして、正規表現を作成するか、正規表現ライブラリから選択します。次に正規表現の挿入先ボタンをクリックします。memoQは必要に応じて、あなたの正規表現をテキストボックスに挿入します。
- ルールを追加するには:ルールボックスに正規表現を入力します。必要に応じて、これ以前または以後(A)テキストボックスに、コンテンツの前後にある文字の正規表現をさらに記述します。追加をクリックします。
- ルールを変更するには:リスト内のルールをクリックします。ルール、これ以前、および以後(A)のテキストボックスを変更します。追加をクリックします。
- ルールを削除するには:リスト内のルールをクリックします。削除をクリックします。
- リスト内でルールを上下に移動するには:ルールをクリックし、上または下をクリックします。これは、ルールが同じテキストに一致するが、オーバーラップしている場合 (たとえば、一方が他方より多くの文字をカバーしている場合) に便利です。この場合、処理の順序が重要です。
プレビュータブでは、一般タブで指定した参照ファイルのいずれかのテキストが表示されます。具体的には、プレビューにはドキュメントからインポートされるテキストが表示されます。プレビューを使用して、次の項目を確認します:
- 文字エンコーディングは正しいですか?(すべての文字が正しく表示されますか?)
- 段落が正しく区切られていますか?(2つの水平バー間の各行は、1つの段落になります。)
- インポートされたテキストは正しくハイライト表示されていますか?
3つの質問すべてに「はい」と答えられた場合は、OKをクリックしてファイルをインポートできます。
重要:次のスクリーンショットは、実際のINIファイルのインポート例を示しています。既定では、memoQにはこのプレビューは表示されません。
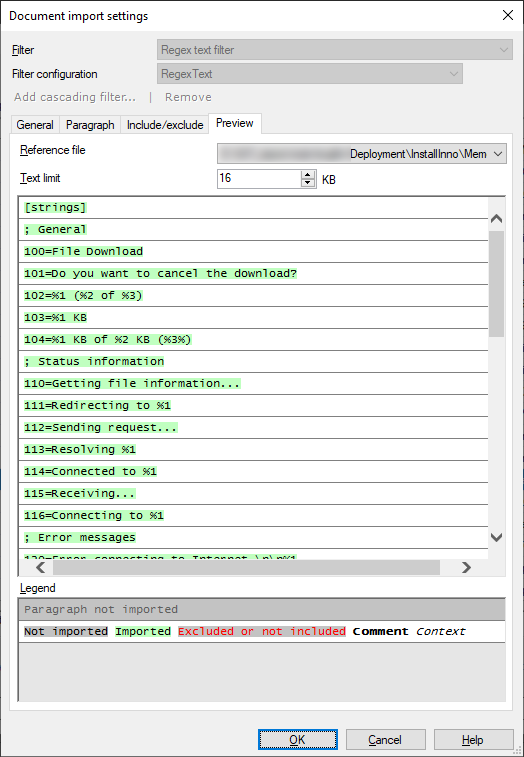
参照ファイルドロップダウンから、表示する参照ファイルを選択します。通常、memoQには、インポート用に選択した最初のファイルが表示されます。
テキスト制限数値ボックスで、テキストの表示量を選択します。通常、memoQはファイルの最初の16キロバイトを表示します。ファイルのエンコーディングによって異なりますが、約4000~16000文字です。
プレビュータブには、段落が水平バーで区切られて表示されます。色でインポートされるものとインポートされないものを示します。
- テキストがグレーの背景 (黒または赤の文字) で表示される場合、そのテキストはインポートされません。文字が黒の場合、パラグラフタブ上のルールのためにコンテンツがスキップされます。テキストが赤の場合は、含める/除外するタブ上のルールのためにテキストが除外されます。
- テキストが緑色の背景で表示される場合は、インポートされまれます。
- 背景が白のテキストは、段落のコメント (太字) またはコンテキスト (斜体) です。
完了したら
-
設定を確定して文書のインポートオプションウィンドウに戻るには:OKをクリックします。
文書のインポートオプションウィンドウで:OKを再度クリックすると、ドキュメントのインポートが開始されます。
-
文書のインポートオプションウィンドウに戻り、フィルタ設定を変更しない場合:キャンセルをクリックします。
-
重ねがけフィルタの場合は、チェーン内の別のフィルタの設定を変更できます。ウィンドウの上部にあるフィルタの名前をクリックします。