正規表現
正規表現は、テキスト内の文字シーケンスを検索するための強力な手段です。memoQでは、セグメンテーションルール、自動翻訳ルール、または正規表現タグ化ツールのルールを定義するために使用されます。正規表現は、検索と置換や、翻訳エディタのフィルタフィールドでも使用できます。
文字列の検索は、ワードプロセッサやテキストエディタを使用していたユーザーにとっては良く知られているタスクです。検索または検索ダイアログで、もし「cat」を検索すると、「cat」、「cats」、「sophisticated」などの単語 (または単語の一部) が強調表示されます。
正規表現を使用すると、検索する単語をより自由に指定することができます。2、3文字の「c」の後に続く文字「a」、1桁以上の複数の数字を含む、または「cat」、「dog」や「mouse」のいずれかの単語を含むなど、特定のシーケンスを識別できます。さらには引用符の間にある単語の出現などのシーケンスを識別できます。このページを参照し、例を試すことで、正規表現について理解を深めることができるはずです。詳細を学習する準備ができていない場合は、正規表現アシスタントがお手伝いします。
注意:正規表現は、パターンマッチング法の基礎となっている数学的理論に由来しています。regexpやregexなどの省略系で表示されることが多いですが、ここでは、正規表現を使用します。
正規表現の構文には多くのバリエーション (フレーバー) があります:memoQは.NET正規表現エンジンを使用するため、.NETフレーバーが使用されます。この記事では、.NET regex構文の一部のみを説明します。詳細なドキュメントについては、Microsoft Learn Webサイトの関連部分を参照してください。
標準の.NET正規表現機能
ワープロの昔ながらの検索機能では、すべての文字は文字通りに解釈されます。「Yes? No...」を検索すると、「Yes? No...」が強調表示されるか、テキストにこれらの文字がない場合には、何も強調表示されません。正規表現では、特別な意味を持つ文字があります。これらはメタ文字と呼ばれます。最も重要なメタ文字:
|
表現 |
説明 |
|---|---|
|
. |
すべての文字に一致します。 |
|
| |
左側か右側の表現がターゲット文字列に一致します。たとえば、a|bは「a」または「b」に一致します。 |
|
[] |
[] 内のすべての文字は、ターゲット文字に一致します。たとえば、[ab]は「a」および「b」に一致します。[0-9] はあらゆる数字に一致します。 |
|
[^] |
[] 内のどの文字も、ターゲット文字に一致しません。たとえば、「[^ab]」は「a」と「b」を除くすべての文字に一致します。'たとえば、[^ab]は「a」および「b」以外のすべての文字に一致します。[^0-9]は数字以外の文字に一致します。 |
|
* |
表現内のアスタリスクの左側の文字は、0回以上一致すべきです。たとえば、be*は「b」、「be」と「bee」に一致します。 |
|
+ |
表現内の+記号の左側の文字は、1回以上一致すべきです。たとえば、be+は「be」と「bee」に一致しますが、「b」には一致しません。 |
|
? |
表現内のクエスチョンマークの左側の文字は、0回または1回一致すべきです。たとえば、be?は「b」と「be」に一致しますが、「bee」には一致しません。 |
|
{num} |
かっこ内の数字の左側の文字は、numの回数と一致すべきです。たとえば、be{2}は「bee」に一致しますが、「be」には一致しません。 |
|
() |
グループを作成し、文字列の一致セクションを「記憶します」。グループは、文字列の一部を再配列するために使用できます。例:日付を異なるフォーマットに変換するときなど |
|
\ |
エスケープ文字。エスケープ文字文字列「\」自体を使用したい場合には、「\\」を使用してください。 |
混乱していますか?この表は、短い概要と参照のみを表しています。これらの表現すべての意味は、以下のセクションに分類できます。
次に、ドットに焦点を当ててみましょう。正規表現では、「ここに入るあらゆる文字」を意味します。つまり、正規表現では、No...は以下のすべてと一致します:
- Notes
- Notte
- No...
- No&%X
では、「No...」という文字列のみに正確に一致するよう、正規表現を記述するには、どのようにしたら良いでしょうか?特別な意味を持つ文字と一致するには、それを「エスケープ」する必要があります。つまり、前に円記号(バックスラッシュ)を付けます。したがって、No\.\.\.は「No...」と完全に一致し、その他には一致しません。
正規表現アシスタントにはまさにテストの場所があります。テスティンググラウンドテキストボックスにテキストをコピーして貼り付け、次を検索ボックスに正規表現を入力します。memoQは、正規表現に一致するテキスト部分をハイライト表示します:
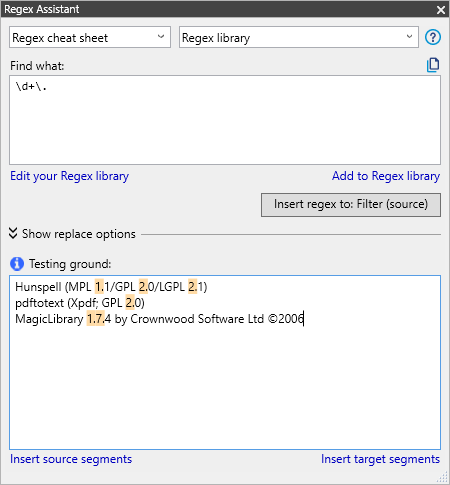
ドットを網羅し、新しい正規表現の方法の試し方も勉強しました。次はもう少し難しい表現に進みましょう。正規表現にかっこを使用することで、一連の文字列つまり文字クラスを指定できます。[ab][01]は、「a」または「b」で始まり、「0」または「1」で終わる2文字のシーケンスに一致します。この例では、4つの一致(「a0」、「b0」、「a1」、「b1」)が考えられます。
文字クラスは、「カンマまたは感嘆符に続く1桁」のようなもの(たとえば[0123456789][,!]のように表記)を表現するために使用できます。ただし、これでは記述するのが大変です。正規表現では、更に詳細を識別できます。[0-9][,!と記述することで、前述の正規表現と全く同じ文字領域を指定できます。
文字クラスを使用してアルファベット文字に一致させることができますか?「はい」であり「いいえ」でもあります:正規表現[a-z]は、aとzの間の文字 (英語アルファベットの文字) のいずれかと一致します。しかし、memoQはさまざまな言語に対応しており、各言語のアルファベットには、特殊な文字が含まれている場合もあります。たとえば、アイスランド語の「đ」は、「a-z」の範囲には含まれません。しかし、このような文字を扱う簡単な方法があります - 以下の短縮系の部分を参照してください。
また、memoQの正規表現のすべての文字は、大文字と小文字を区別して解釈されます。したがって、[a-z]は「f」に一致しますが、「F」には一致しません。
一致しない文字を指定するために文字クラスを使用することもできます。正規表現[^0a].は、最初の文字が「0」または「a」でない2文字のシーケンスと一致します。
前に説明したように、特殊メタ文字を通常の文字として使用するには、特殊メタ文字をエスケープする必要があります (メタ文字の前に円記号 (バックスラッシュ) を追加します)。実際の「+」記号と一致させるには、正規表現で\+文字を使用する必要があります。他にも実用的なエスケープシーケンスがあります。例えば、\tはタブ文字と一致したり、\nは改行と一致したりします。また、多くのエスケープシーケンスは文字クラスの短縮系です。
|
シーケンス |
説明 |
|---|---|
|
\s |
スペース、タブ、または改行 |
|
\S |
空白以外なら何でも |
|
\d |
数字 |
|
\D |
数字以外なら何でも |
|
\w |
英数字とアンダースコア |
|
\W |
英数字以外なら何でも |
これらのショートハンドは、前節の基本的な文字クラスとは少し異なります:\dは[0-9] だけでなく、すべてのUnicode 10進数 (多くの表記法から) と一致します。また、\wは [a-z] だけでなく、すべてのUnicode文字 (小文字と大文字)、数字、アンダースコア(_)とマッチします。
これで、特定の位置で文字を一致させる方法を学習しました。次に、memoQに一致させる文字の数を指定します。これには、「+」や「?」のような特殊文字と表現「{num}」を使用します。
|
表現 |
説明 |
|---|---|
|
* |
表現内のアスタリスクの左側の文字は、0回以上一致すべきです。たとえば、be*は「b」、「be」と「bee」に一致します。 |
|
+ |
表現内の+記号の左側の文字は、1回以上一致すべきです。たとえば、be+は「be」と「bee」に一致しますが、「b」には一致しません。 |
|
? |
表現内のクエスチョンマークの左側の文字は、0回または1回一致すべきです。たとえば、be?は「b」と「be」に一致しますが、「bee」には一致しません。 |
|
{num} |
かっこ内の数字の左側の文字は、numの回数と一致すべきです。たとえば、be{2}は「bee」に一致しますが、「be」には一致しません。 |
-
正規表現x+は、1以上の「x」から成る一連の文字列に一致します(つまり、「x」、「xx」、「xxx」など)。
-
正規表現x{3}は、3つの「x」から成る一連の文字列に一致します(つまり、「xxx」です。「x」や「xx」ではありません)。テキストが「xxxx」の場合には、この正規表現は最初の3つの「x」が致し、4つめは無視されます:「xxxx」。通常の[検索]ダイアログで、「cats」の中で「cat」という単語を見つけるのと同じです。
-
「{num}」数量子を使用して、最小値 (および必要に応じて最大値) を指定することもできます。したがって、x{3,5}は3~5つの「x」に致し、x{3,}は少なくとも3つの「x」に一致します。
x{,5}は次のようには動作しません:最大で5つの「x」に一致するため、x{0,5}と設定。
-
正規表現x*yは、任意の数 (0も含む) の「x」が前に付いた「y」と一致します。つまり、「y」、「xy」、「xxy」のようなものと一致しますが、「zy」は一致しません。
-
正規表現zx?yは「z」の後に0または1つの「x」と「y」が続くものと一致します。つまり、「zy」や「zxy」と一致しますが、「zxxy」とは一致しません。
さらに強力に使用するには、文字セットやショートハンドを数量子と組み合わせます:[0-9]+%または\d+%は、1つ以上の数字に続いてパーセント記号があるものと一致します。たとえば、「1%」または「99%」とは一致しますが、「10a%」は一致しません。
パイプ記号 (「|」) を使用すると、「これか、あれかまたはその他のいずれかに一致する」というように、複数の小さな正規表現をつなぐことができます。正規表現EUR|USD|GBPは、これらの単語のどれにも一致し、これらのみに一致します。
別の選択を使用する場合、希望する結果を得るよう、丸括弧で囲みグループ化する必要があります。たとえば、次の語句のいずれかと一致する正規表現が必要とします:「EUR 15 million」、「USD 37 million」、「GBP 5 million」。まずは、EUR|USD|GBP \d+ millionと入力してみます。ただし、この場合には次の文字列のみに一致します:「EUR」、「USD」、「GBP [任意の桁数] million」。正規表現で選択肢をグループ化する必要があります:(EUR|USD|GBP) \d+ million。EUR|USD|GBPは、「EUR」または「USD」または「GBP」のいずれかで、\d+は0から始まる任意の整数です。
セグメンテーションルールで、memoQでは、翻訳文書のテキスト内でパターンを一致させるために正規表現のみを使用しています。自動翻訳ルールに対しては、グループと関係のある強力な別の正規表現機能(一致したテキストの置換および並べ替え)を使用します。
|
検索する文字列 |
置換する文字列 |
説明 |
|---|---|---|
|
いいえ |
xx |
「no」という文字を検索し、「xx」に置き換えます。(この例では、正規表現特有の要素はありません。) |
|
no... |
xx |
「no」とそれに続く3文字を検索し、「xx」に置き換えます。たとえば、「notes」を「xx」または「monotone」を「moxxe」に置き換えます。 |
| (one) two | $1 three |
「one two」を検索し、「one three」に置き換えます。 |
|
(one) (two) |
$2 $1 $1 |
「one two」を検索し、「two one one」に置き換えます。 |
|
(EUR|USD|GBP) (\d+) million |
$2 Millionen $1 |
「EUR」、「USD」、または「GBP」の後に数字と「million」という単語が続くものを検索し、数字、「Millionen」、および通貨コードに置き換えられます。これは金額を英語からドイツ語に変換する方法です。 |
-
一致したテキストと1つの文字列を置換:
検索と置換ウィンドウの次を検索ボックスに正規表現を入力し、置換テキストボックスに置換式を入力することができます。上の表の最初の2行は、文字列を別の文字列に置き換える簡単な例を示しています。
-
一致したテキストの一部を再配置する/または置換する:
ここで、その正規表現のすべての部分を丸かっこで囲む必要があります。丸かっこで囲まれた一致はmemoQによって記憶され、1で始まる数字が割り当てられます。置換式を記述するときに、$1、$2などで記憶されたサブストリングを参照できます。$1は括弧内の最初のグループを参照し、$2は括弧内の2番目のグループを参照します。以下同様です。
先ほどの正規表現の例をもう一度見てみましょう。通貨と値を並べ替えるには、\d+を括弧で囲む必要があります:(EUR|USD|GBP) (\d+) million。置換式では、EUR|USD|GBPは$1、および\d+は$2で参照できます。ドイツ語で順序を変更するには、置換式$2 Millionen $1を使用します。
memoQでの拡張
|
シーケンス |
説明 |
|---|---|
|
インラインまたはmemoQタグ |
|
|
\itag |
インラインタグ |
|
\mtag |
memoQタグ |
正規表現でタグを検索するには、次の3つの特別なエスケープシーケンスを使用してそれらを一致させることができます:
- \tag:すべてのタグに一致します
- \itag:インラインタグに一致します (次のように表示されもの:
 )
) - \mtag:memoQタグに一致します (テキストで {中括弧} で表示されるタグ)
タグは通常、その前後のテキストのすぐ隣にあります (スペースはありません)。タグとテキストの組み合わせを探している場合は、正規表現を読みやすくするために、上記のシーケンスを括弧「()」で囲みます。例:「(\itag)int」は、「integrated」、「interesting」、「intentional」のような単語が続くインラインタグ(開始、終了、または空)に一致します。
セグメンテーションルールと自動翻訳ルールを作成するには、単語リスト(略語、月名、通貨など)を使用すると便利です。理論的には、正規表現の選択肢としてグループ化されたこれらの単語をリストすることが可能です (上記の選択肢に関する部分を参照)。ただし、これらの正規表現は非常に複雑で、維持するのが困難です。これを簡単にするために、memoQには、正規表現にカスタムリストという特別な拡張機能があります。
正規表現で使用される単語のリストは、セグメンテーションルールダイアログ、自動翻訳ルールダイアログのカスタムリストタブ、または自動翻訳ダイアログの翻訳ペアタブで定義できます。
- セグメントルールセットの編集ウィンドウのカスタムリストタブのカスタムリストを使用して、セグメンテーションで重要な文字、略語を収集します (「.」、「!」、「e.g.」など)。
- 自動翻訳ルールセットの編集ウィンドウのカスタムリストタブにあるカスタムリストを使用して、ソースとターゲットで同じ形式を持つ単語を収集します (「€」、「$」など)。
- 自動翻訳ルールセットの編集ウィンドウの翻訳ペアタブのカスタムリストを使用して、ソース単語とそれに対応するターゲットを収集します (たとえば、英語とドイツ語のプロジェクトでは、「January」は「Januar」、「February」は「Februar」、「March」は「März」などに翻訳される必要があります)。
カスタムリストの名前は、常にハッシュ記号(「#」)で始まる必要があります。memoQは常に、カスタムリスト内の単語をプレーンテキストとして扱います。特殊な意味を持つメタ文字として扱うことはありません。
セグメンテーションルールには、もう1つの特別なアイテムを含めることができます:「#!#」。この拡張は正規表現一致に対しては何もしません。代わりに、memoQに対して、式がインポートされたドキュメント内のテキストと一致する場所にセグメントブレークを置くように指示します。
自動翻訳ルールウィンドウのカスタムリストタブでカスタムリストを使用する例:
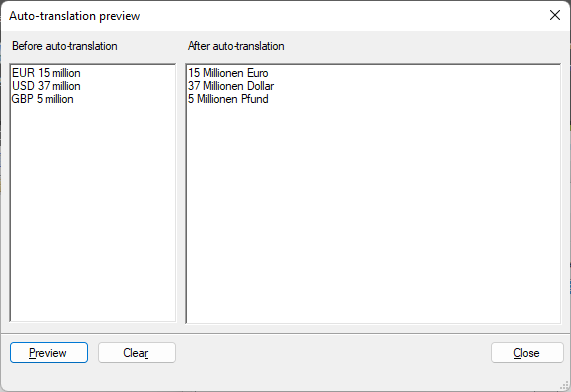
memoQが翻訳結果で「EUR 15 million」に対しては「15 Millionen EUR」を、「USD 37 million」に対しては「37 Millionen USD」を提案して欲しい場合。カスタムリストタブで、#currency#カスタムリストを作成し、値としてEUR、USD、およびGBPを追加します。
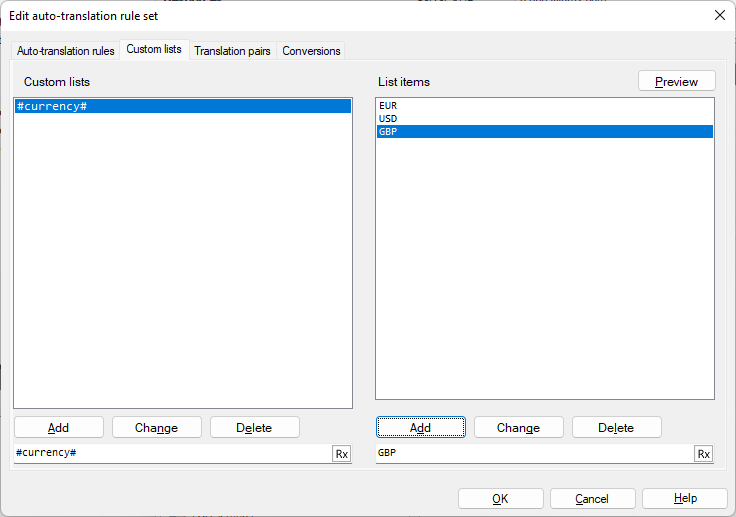
次に、自動翻訳ルールタブで正規表現(#currency#) (\d{1,}) million ((EUR|USD|GBP) (\d{1,}) millionと同じ) と置換式$2 Millionen $1を作成します。上記の正規表現と置換式のプレビューは次のようになります:
![]()
memoQが翻訳結果で「EUR 15 million」に対しては「15 Millionen Euro」を、「USD 37 million」に対しては「37 Millionen Dollar」を提案するには:翻訳ペアタブで、#currency2#という名前のカスタムリストを作成し、次の翻訳ペアを追加します:「EUR」–「Euro」、「USD」–「Dollar」、「GBP」–「Pfund」。
異なる名前を使用する:翻訳ペアタブ上のリストの名前は、カスタムリストタブ上のものと異なる必要があります。
![]()
次に、自動翻訳ルールタブで正規表現(#currency2#) (\d{1,}) millionと置換式$2 Millionen $1を作成します。上記の正規表現と置換式のプレビューは次のようになります: