TMマッチスコアおよび数字置換
memoQは、TMと資料からのほぼ正確な一致とあいまい一致の数字を調整することができ、TMに格納されている数字の代わりにルックアップセグメントから実際の数字を入力することができます。2つのセグメントの違いが数字だけで、翻訳中の数字を自動的に修正できる場合、マッチ率は99%となり、手動で修正する必要はありません。これにより、コスト(たくさんのハイファジー)と労力を削減することができます。
関連項目:一般的なマッチ率の概要については、翻訳メモリおよびライブ文書資料からのマッチ率に関するトピックを参照してください。
自動調整のシナリオ
- ソースとターゲットで数字が異なる(例:1.000と1000)
- スペースとノーブレークスペースによる桁区切りがある数字
- 数字内のスペース (例:2 345)
- .99のような数字 (整数部分は0)
- プラス記号 (例:U+002BまたはU+FF0B)
- TM設定の完全一致に対するインラインタグの厳密さに基づいて99%のファジー一致を100%一致に上げるためのタグ調整。タグの厳密性とマッチ率も参照してください
- オプションとして、memoQ(バージョン7.8.100以降)では、数字の修正のみの場合、完全一致 (100%) を返すことができます。これは、ドキュメントとマッチの違いが数字だけで、他に何もない場合に機能し、memoQはその違いに合わせてマッチを調整することができます。これは、翻訳メモリ設定またはライブ文書設定でオンにすることができます。
中国語、日本語、韓国語のテキストに含まれるラテン語の数字に対しても、数字マッチングが機能します。ただし、中国語および日本語のネイティブな数字形式はまだサポートされていません。
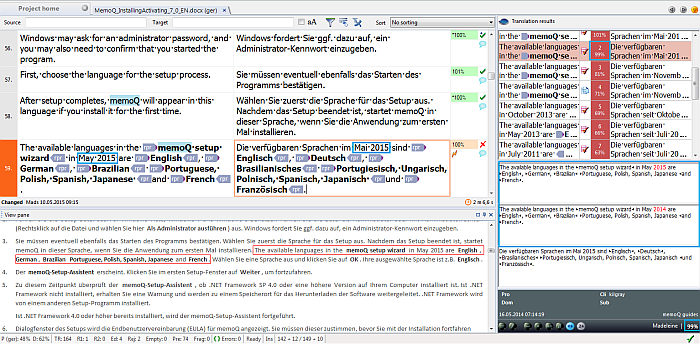
年号修正の例

数字形式の修正例
注意:memoQ 2015の使用開始時にTMを移行する必要はありません。しかし、改善された一致の恩恵を受けようとするならば、TMを修復する必要があります (リソースコンソール > 翻訳メモリ、TMを選択してリソースの修復リンクをクリックしてください)。
注意:セグメントスコアは単語の長さに依存します。同じ単語でも、短いと重さが減り、長いと重さが増えます。1単語のセグメントは3単語のセグメントよりもスコアが低くなります。両方のセグメント(ルックアップとTM)の5単語以下で、両方のセグメントが128文字より短い場合、レーベンシュタインアルゴリズムが使用されます(レーベンシュタインの編集距離を参照)。