新しい翻訳メモリ
memoQで新しい翻訳メモリを作成すると、新規翻訳メモリウィンドウが開きます。
翻訳メモリは、セグメントのペアを含むデータベースです (ソースとターゲット言語)。プロジェクトで翻訳メモリを使用すると、memoQは翻訳するセグメントの一致を提供します。翻訳メモリ内に、翻訳中のセグメントと同じセグメントまたは類似したセグメントがある場合、memoQは保存した翻訳を提供できます。これにより、セグメントを最初から翻訳する必要がなくなります。
プロジェクトでは、1つまたは複数の翻訳メモリを使用できます。翻訳エディタで作業している間、memoQは翻訳メモリからセグメントを検索し続けます。翻訳エディタは、翻訳メモリ内にある既存の翻訳を提供し、挿入します。memoQはまた、翻訳メモリ内のセグメント内にある語句も検索します。これらも翻訳結果に含まれますし、訳語検索ウィンドウを開いて翻訳を確認できます。逆方向の読み込みが可能な翻訳メモリもあります。プロジェクトに複数のターゲット言語がある場合は、ターゲット言語の1つを選択する必要があります。リソースコンソールから翻訳メモリを作成する場合は、2つの言語を選択できます。
空の翻訳メモリ:このコマンドは空の翻訳メモリを作成します。翻訳メモリに新しいエントリを追加するには、翻訳エディタで翻訳を確定してエントリを直接追加するか、ドキュメントをライブ文書資料内の翻訳と整合し、その整合結果を翻訳メモリにエクスポートします。
操作手順
-
リソースコンソール
 を開きます。
を開きます。 -
翻訳メモリ
 を選択します。
を選択します。 -
リストの下で新規作成をクリックします。
-
新規翻訳メモリウィンドウが開きます。
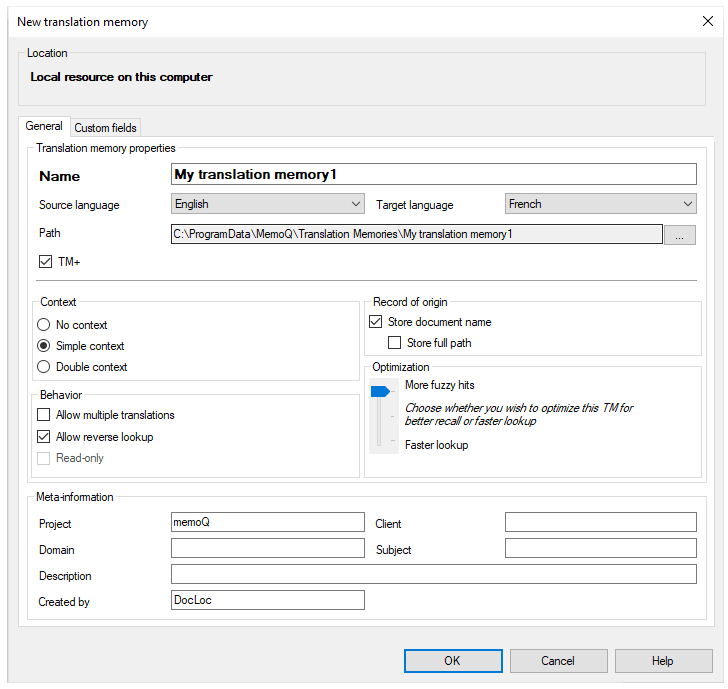
リソースコンソールまたはmemoQウィンドウの上部でマイコンピュータが選択されている場合
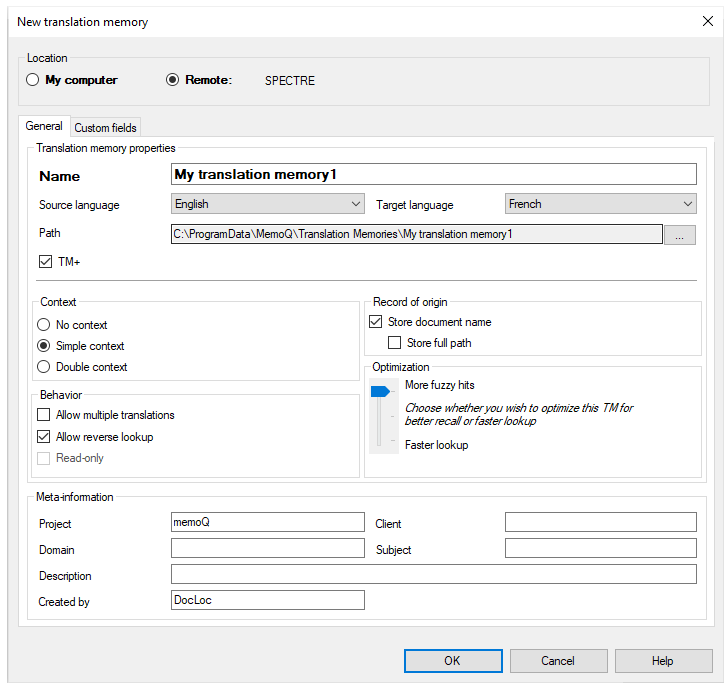
ローカルプロジェクトのユーザーであっても、リソースコンソールまたはmemoQウィンドウの上部でmemoQ serverが選択されている場合
その他のオプション
リソースコンソールから来て、上部でmemoQ serverが選択された場合:翻訳メモリを自分のコンピュータで作成するか、サーバーで作成するかを選択できます。
選択するには:マイコンピュータまたはリモートラジオボタンをクリックします。
ここでは、他のサーバーを選択することはできません。他のサーバーで翻訳メモリを作成するには:このウィンドウを閉じます。リソースコンソールの上部で他のサーバーを選択します。もう一度新規作成をクリックします。
memoQ project managerを実行している場合は、プロジェクトホームでも動作します:memoQ project managerでは、メインmemoQウィンドウの上部にあるサーバーを選択できます。ローカルプロジェクトが開いていて、上部でサーバーが選択されている場合は、ロケーションを選択できます。
翻訳メモリのプロパティで名前ボックスに名前を入力します。名前はコンピュータ、または作成場所のサーバーで一意である必要があります。
ソース言語およびターゲット言語ドロップダウンで、翻訳メモリの言語を選択します。
プロジェクトから言語を選択できません:プロジェクトから翻訳メモリの作成を開始すると、翻訳メモリにはプロジェクトの言語が表示されます。ID を変更することはできません。
パスボックスを変更しない:このボックスは、ローカル翻訳メモリを作成する場合に表示されます。翻訳メモリが保存されるフォルダのフルネームが表示されます。memoQにはTMなどのリソースの標準的な場所があります。システムの完全なバックアップを作成することが困難になるため、変更しないでください。リソースを別の場所に保存する必要がある場合は、memoQをインストールした直後に選択してください。オプションウィンドウの保存場所でロケーションを変更します。
memoQ 10.5以降のバージョンでは、新しい翻訳メモリはデフォルトでTM+になります。クラシックTMを作成するには:翻訳メモリのプロパティ領域で、TM+チェックボックスをオフにします。
TM+では、次のいずれかが可能です:
-
コンテキストの保存 - 翻訳メモリのセグメントとコンテキストの両方が同じである場合、翻訳メモリはコンテキストマッチを提供します。コンテキストマッチを返すには、翻訳メモリにコンテキストを格納する必要があります。
または
-
複数の訳文を許可(M) - 別の翻訳ツールから翻訳メモリをインポートする場合や、インポートするファイルに複数の翻訳が含まれている場合を除き、このオプションはお勧めできません。2つの翻訳が異なる場合、ほとんどの場合、コンテキストも異なります。翻訳メモリ内でコンテキストを使用する場合は、複数の訳文は必要はありません。
翻訳メモリのセグメントとコンテキストの両方が同じである場合、翻訳メモリはコンテキストマッチを提供します。コンテキストマッチを返すには、翻訳メモリにコンテキストを格納する必要があります。
たとえば、翻訳メモリから文書の翻訳を再構築する必要がある場合は、コンテキストマッチが必要です。また、新しいバージョンのソースドキュメントの翻訳を更新する必要があり、2つのバージョン間にほとんど違いがない場合にも便利です。
memoQには、2種類のコンテキストマッチがあります。
シンプルコンテキストマッチ:101%マッチ率
- テキストフローコンテキスト - ソースドキュメントにランニングテキストが含まれる場合、コンテキストは前後のセグメントになります。
- IDベースコンテキスト - これは、ソースドキュメントがテーブルまたは構造化されたドキュメントで、各エントリが識別子を持つ (または持つことができる) 場合に機能します。この場合、コンテキストは識別子であり、セグメントと識別子の両方が翻訳メモリ内で同じである場合、memoQはコンテキストマッチを返します。
二重コンテキストマッチ:102%マッチ率
-
二重コンテキストは、ランニングテキストおよび識別子の両方があるドキュメントで可能です。この場合、memoQは翻訳メモリで両方をチェックできます。
マッチ率の詳細については:翻訳メモリとライブ文書資料からのマッチ率に関するトピックをご覧ください。
コンテキストのない翻訳メモリ:
コンテキストを保存しない翻訳メモリを作成することもできます。これはお勧めできません。ただし、翻訳メモリを参照のみに使用し、別の翻訳ツールから翻訳メモリファイルをインポートする場合を除きます。翻訳メモリにコンテキストが保存されていない場合は、プロジェクト内で作業用またはマスターの翻訳メモリにしないでください。セグメントを確定すると、memoQは常にコンテキストの保存を試みます。コンテキストなし翻訳メモリにセグメントを確定すると、データが失われます。
この設定は、翻訳メモリの作成後は変更できません。
複数の訳文を使用しない:memoQでは、同じソース言語セグメントの複数の翻訳を保存できます。別の翻訳ツールから翻訳メモリをインポートする場合や、インポートするファイルに複数の翻訳が含まれている場合を除き、このオプションはお勧めできません。2つの翻訳が異なる場合、ほとんどの場合、コンテキストも異なります。翻訳メモリ内でコンテキストを使用する場合は、複数の訳文は必要はありません。複数の訳文を許可(M)チェックボックスのチェックマークがオフであることを確認します。
通常、翻訳メモリはリバーシブルです。つまり、memoQはソース言語とターゲット言語の両方でセグメントを検索できます。つまり、ターゲット言語を別のプロジェクトのソース言語として使用できます。
しかし、memoQはソース言語が重要であることを知っています。プロジェクトの言語方向が逆の場合、翻訳メモリの名前はイタリック体で表示されますが、そこに表示されます。
逆方向の言語を持つプロジェクトでは、翻訳メモリを作業用またはマスタの翻訳メモリにすることはできません。
新しい翻訳メモリーをリバーシブルにしたくない場合:逆方向のルックアップを許可チェックボックスをオフにします。
この設定は、翻訳メモリの作成後は変更できません。
翻訳エディタでセグメントを確定すると、memoQはセグメントとその翻訳と共にドキュメントの名前を保存します。これは、翻訳をレビューしている場合、または翻訳をどの程度信頼するかを決定する必要がある場合に興味深いでしょう。
翻訳メモリにドキュメント名を含めない場合:文書名の保存(U)チェックボックスをオフにします。
同じ名前の異なるドキュメントが2つ以上ある場合:これは、さまざまなフォルダからインポートされたドキュメントで作業する場合に可能です。保存されている名前が異なることを確認するには、フルパスの保存チェックボックスをオンにします。
オンに戻すことができます:そのためには、翻訳メモリのプロパティウィンドウを開きます。
この設定は、低速のコンピュータを使用している場合や、memoQ serverの負荷を軽減する場合に便利です。
通常、memoQはできるだけ多くのマッチを返します。ただし、返されるファジーマッチの数が少なくなるように調整することもできます。しかし、返されるファジーマッチの方がはるかに高速です。
完全一致またはコンテキストマッチのために翻訳メモリを使用する場合は、安全に翻訳メモリを使用できます。
新しい翻訳メモリを調整するには、右側にある他のあいまい一致や速いルックアップと表示されているスライダを使用します。スライダを速いルックアップの方向に移動できます。
スライダには3つのストップがあります。通常、memoQは最大一致数を提供します。中間の設定があり、バランスのとれた結果が得られます。一番下の設定は最小一致数を返しますが、これが最速です。
これは後で変更できます:そのためには、翻訳メモリのプロパティウィンドウを開きます。
カスタムフィールドタブで実行します。
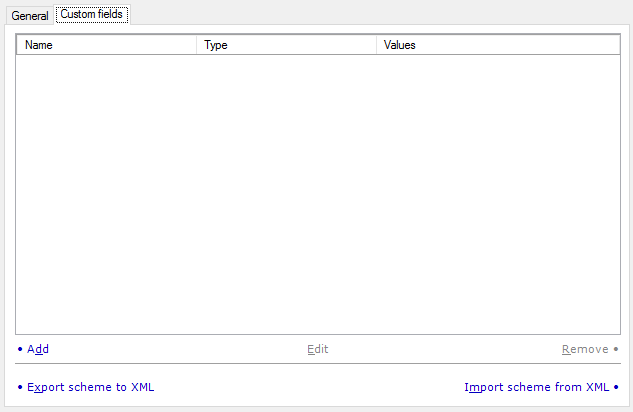
カスタムフィールドを新しい翻訳メモリに追加できます。各翻訳ユニットは、通常のフィールド (すべての翻訳メモリに存在する) とカスタムフィールド (ここで追加する) にメタデータを持つことができます。翻訳メモリごとに異なるカスタムフィールドを持つことができます。
最大20個のカスタムフィールド:翻訳メモリには20を超えるカスタムフィールドを含めることはできません。
次の場合、このリストにはいくつかのカスタムフィールドが既に含まれています:
- カスタムフィールドがオプションウィンドウのその他カテゴリの既定のTMスキーマタブですでに定義されている、または
- カスタムフィールドを持つ翻訳メモリ (リソースコンソールまたはプロジェクトホームの翻訳メモリペイン) を複製してここに配置します。
次のオプションを使用できます:
- 追加:このリンクをクリックすると、デフォルトのTMスキームに新しいカスタムフィールドが追加されます。カスタムフィールドプロパティウィンドウが開きます。新しいカスタムフィールドの名前と種類を指定します。タイプにPicklist (single)またはPicklist (multiple)を選択した場合は、フィールドに設定可能な値をリストする必要があります。
- 編集:このリンクをクリックして、選択したカスタムフィールドの種類を変更します。カスタムフィールドプロパティウィンドウが開きます。名前の変更はできません:名前ボックスはグレーアウトされます。フィールドのタイプを変更できます。タイプにPicklist (single)またはPicklist (multiple)を選択した場合は、フィールドに設定可能な値をリストする必要があります。
- 削除:このリンクをクリックすると、選択したカスタムフィールドがリストから削除されます。これは、OKボタンをクリックする前にのみ機能します。
- XMLにスキーマをエクスポート(X):このリンクをクリックすると、カスタムフィールドのリストがXMLファイルとしてエクスポートされます。このファイルは、このコンピュータでも、memoQを実行している他のコンピュータでも、新しい翻訳メモリを作成するときに使用できます。
- XMLからスキーマをインポート(M):このリンクをクリックすると、以前に別のmemoQからXMLファイルに保存されたカスタムフィールドのリストが入力されます。
TMの保存後はカスタムフィールドを変更または削除できません:OKをクリックすると、memoQはカスタムフィールドを翻訳メモリに保存します。その後は、ピックリストの値のみを変更できます。保存後にカスタムフィールドを削除するには:このフィールドを使用している翻訳ユニットがないことを確認してください。翻訳メモリをTMXファイルにエクスポートします。新しい翻訳メモリを作成します。TMXファイルを新しいTMにインポートします。不要なカスタムフィールドはありません。
完了したら
翻訳メモリを作成するには:OKをクリックします。