PO Gettext-Dateien
Bei PO-Dateien handelt es sich um Lokalisierungsdateien, die größtenteils zum Schreiben mehrsprachiger Programme auf Unix-Computern verwendet werden. PO Gettext-Dateien sind zweisprachig und können eine Ausgangssprache und eine Zielsprache enthalten.
PO Gettext-Dateien können in memoQ direkt verwendet werden. Die exportierte Datei ist zweisprachig.
Navigation
- Importieren Sie eine PO Gettext-Datei (PO-Datei).
- Wählen Sie im Fenster Dokument-Importoptionen die PO Gettext-Dateien aus, und klicken Sie auf Filter und Konfiguration ändern.
- Das Fenster Einstellungen für Dokumentenimport wird angezeigt. Wählen Sie in der Dropdown-Liste Filter die Option PO Gettext-Filter aus.
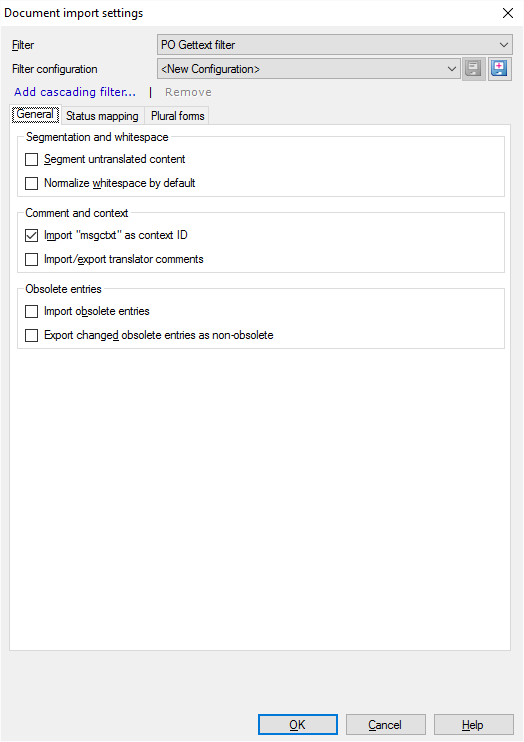
Möglichkeiten
- Normalerweise wird der nicht übersetzte Text in memoQ nicht in Segmente aufgeteilt. Eine PO-Datei besteht aus Einträgen. Jeder Eintrag wird in genau ein Segment umgewandelt, unabhängig davon, wie viele Sätze er enthält. So teilen Sie die Einträge in Segmente auf: Aktivieren Sie unter Segmentierung und Leerräume das Kontrollkästchen Nicht übersetzten Inhalt segmentieren.
- Normalerweise werden die Leer-, Tabstopp- und Zeilenumbruchzeichen beim Importieren von PO Gettext-Dateien nicht geändert. Sie können jedoch normalisiert werden: Folgen von Tabstopps, Leerzeichen und Zeilenumbruchzeichen können in ein einzelnes Leerzeichen umgewandelt werden. Beim Normalisieren von Leerräumen werden auch alle Leerräume am Anfang und am Ende von Einträgen gelöscht. So normalisieren Sie Leerzeichen: Aktivieren Sie das Kontrollkästchen Leerräume als Standard normieren.
Beispiel:
Vor der Normalisierung:
This is a
test, with a lot of spaces.
Nach der Normalisierung:
This is a test, with a lot of spaces.
- In einer PO Gettext-Datei weist jeder Eintrag ein Attribut mit dem Namen "msgctxt" auf. Normalerweise wird dieses Attribut in memoQ als Kontext des Segments importiert. Deaktivieren Sie das Kontrollkästchen "msgctxt" als Kontext-ID importieren, wenn der Kontext nicht importiert werden soll.
- Normalerweise werden Kommentare aus PO Gettext-Dateien in memoQ nicht importiert. So importieren Sie Kommentare: Aktivieren Sie das Kontrollkästchen Übersetzerkommentare importieren/exportieren.
Wenn Kommentare nicht importiert werden, werden sie auch nicht exportiert: Wenn Sie nicht auswählen, dass Kommentare aus einer PO Gettext-Datei importiert werden, werden Kommentare von Übersetzern in memoQ nicht exportiert. Wenn die Kommentare von Übersetzern oder Überprüfern in den exportierten Dateien angezeigt werden sollen, müssen Sie dieses Kontrollkästchen aktivieren, auch wenn die Ausgangsdateien keine Kommentare enthalten.
- In PO Gettext-Dateien handelt es sich bei veralteten Einträgen um die Einträge, die im lokalisierten Programm nicht angezeigt werden oder die nicht übersetzt werden sollen. Normalerweise werden sie nicht importiert.
- So importieren Sie veraltete Einträge: Aktivieren Sie das Kontrollkästchen Veraltete Einträge importieren.
- Wenn Sie veraltete Einträge importieren, werden die zugehörigen Übersetzungen im Allgemeinen als veraltet exportiert. Sie können sie aber wieder aktivieren. Aktivieren Sie dazu das Kontrollkästchen Geänderte veraltete Einträge als nicht veraltete Einträge exportieren.
Ein Eintrag in einer PO-Datei ist wie folgt strukturiert:
white-space
#. extracted-comments
#: reference...
#, flag...
#| msgid previous-untranslated-string
msgid untranslated-string
msgstr translated-string
- msgiduntranslated-string wird als Ausgangstext importiert und msgstrtranslated-string als Zieltext. Die Felder msgid und msgstr enthalten die ausgangs- und zielsprachliche Zeichenfolge einer Übersetzungseinheit. Die msgid-Elemente sind innerhalb einer PO-Domäne eindeutig.
Beispiel:
msgid " "
"memoQ Ltd. ist"
" "
"%s. \n"
"What is"
" "
"the company about?"
ist identisch mit:
msgid "memoQ Ltd. ist %s. \n Worum geht es bei dem Unternehmen?"
- Das msgctxt-Element wird als Kontext-ID importiert. Das #| msgid-Element ist als veraltet markiert.
- Das Element # flag wird beibehalten. Kennzeichen werden verwendet, um den Status einer Übersetzungseinheit anzugeben (z. B. Beendet oder Fuzzy). Ein Fuzzy-Kennzeichen kann einem memoQ-Segmentstatus zugeordnet werden (auf der Registerkarte Statuszuordnung). Mehrere Kennzeichen werden durch Kommas voneinander getrennt.
- Die # translator-comments können als memoQ-Kommentare importiert und exportiert werden, wenn Sie dies beim Importieren der Datei auswählen. Diese Kommentare werden von den Übersetzern hinzugefügt und sind in PO-Dateien nicht vorhanden. Die Kommentare werden vor den "extracted-comments"-Elementen und den Referenzkommentaren eingefügt.
- Die Felder # extracted-comments und # reference werden in ihrer Struktur beibehalten. Sie werden in memoQ nicht geändert. Die Extracted comments-Elemente werden aus dem Quellcode extrahiert, wenn sie sich in derselben Zeile wie die ausgangssprachliche Zeichenfolge oder in der Zeile davor befinden. Die Elemente der Reference comments sind durch Leerzeichen getrennte Listen mit Positionsangaben zu den Übersetzungseinheiten in einer Ausgangsdatei. Eine einzige Übersetzungseinheit kann mehrere Referenzen enthalten (eine pro Position).
- Veraltete Einträge sind Einträge, die auskommentiert werden, wenn eine PO-Datei aktualisiert wird. Text, der nicht zur Übersetzung vorgesehen ist, ist z. B. veraltet. In der Regel wird das msgmerge-Element zum Auskommentieren von Einträgen verwendet (sodass sie veraltet sind). Veraltete Einträge sind mit #~ markiert.
Eine umfassende Spezifikation zu diesem Dateiformat finden Sie hier bzw. hier.
Einträge in einer PO Gettext-Datei weisen zwei Statuswerte auf: fuzzy und non-fuzzy. Klicken Sie auf die Registerkarte Statuszuordnung, um sie in memoQ zu importieren oder wieder in die PO Gettext-Dateien zu exportieren.
- Normalerweise werden in memoQ beim Importieren einer Datei die Gettext-Statuswerte nicht importiert. Aktivieren Sie dazu das Kontrollkästchen Gettext-Status beim Import zuordnen.
- Zunächst werden die memoQ-Statuswerte beim Exportieren einer PO Gettext-Datei auch nicht exportiert. Aktivieren Sie dazu das Kontrollkästchen memoQ-Status beim Export zuordnen.
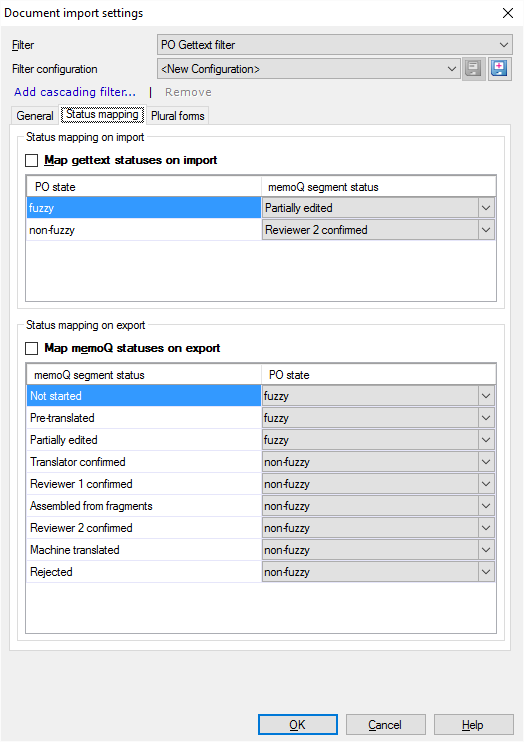
Beim Importieren einer PO Gettext-Datei in memoQ wird der aus der Datei gelesene Status interpretiert und umgewandelt.
- "fuzzy"-Einträge werden normalerweise als Teilweise bearbeitet (Bearbeitet) importiert. Um dies zu ändern, wählen Sie in der Dropdown-Liste neben "fuzzy" einen anderen Status aus.
- "non-fuzzy"-Einträge werden normalerweise als Durch Überprüfer 2 bestätigt importiert. Um dies zu ändern, wählen Sie in der Dropdown-Liste neben "non-fuzzy" einen anderen Status aus.
Beim Exportieren einer PO Gettext-Datei in memoQ wird der Status jedes Segments entweder als "fuzzy" oder "non-fuzzy" exportiert.
Normalerweise werden Segmente mit dem Status Nicht begonnen, Vorübersetzt und Teilweise bearbeitet (Bearbeitet) als "fuzzy" exportiert. Alle anderen Statuswerte werden als "non-fuzzy" exportiert. Um dies zu ändern, wählen Sie in einer oder mehreren Dropdown-Listen in der Liste unten einen anderen Status aus.
Wenn ein Eintrag numerische Platzhalter umfasst, können die PO Gettext-Dateien Varianten für den Text enthalten, sofern sich die Pluralformen in der Ausgangs- und der Zielsprache unterscheiden.
Dies können Sie auf der Registerkarte Pluralformen einrichten. So lassen Sie die Varianten zu: Aktivieren Sie das Kontrollkästchen Pluraleinträge anpassen.
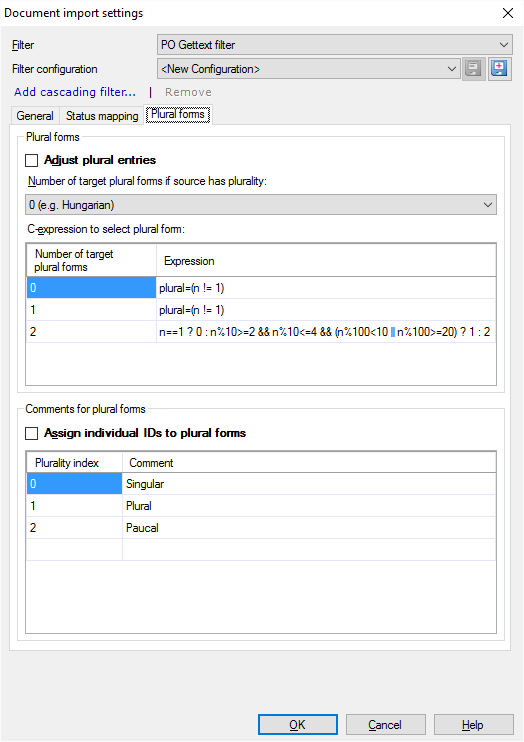
In den Einträgen sehen die Varianten für Singular und Plural wie folgt aus:
#: src/msgcmp.c:338 src/po-lex.c:699
#, c-format
msgid "found %d fatal error"
msgid_plural "found %d fatal errors"
msgstr[0] "s'ha trobat %d error fatal"
msgstr[1] "s'han trobat %d errors fatals"
Wählen Sie die Anzahl der Pluralformen in der Ausgangssprache aus. In der Dropdown-Liste Number of target plural forms if plurality is present in source können Sie 0 wählen (z. B. Ungarisch)", "1 (z.B. Lateinische Sprachen)" und "2 (z.B. Slawische Sprachen)" wählen.
Der Ausdruck neben jeder Form gibt an, wann welche Pluralform zu verwenden ist. Dies können Sie mit C-Ausdrücken einrichten. C-Ausdrücke sind bedingte Formeln der Programmiersprache C (wird hier nicht weiter ausgeführt).
Jeder Pluralform kann ein Name zugewiesen werden. So verwenden Sie diese Namen: Aktivieren Sie das Kontrollkästchen Einzelne IDs zu Pluralformen zuweisen. Die im Screenshot abgebildeten Namen werden automatisch angezeigt. Klicken Sie zum Ändern auf die einzelnen Namen.
Wenn das Kontrollkästchen Einzelne IDs zu Pluralformen zuweisen aktiviert ist, werden diese Informationen an das msgctxt-Attribut (Kontext) angefügt. Wenn Sie das Kontrollkästchen nicht aktivieren und zwei Pluralformen in der Zielsprache vorhanden sind, können der Ausgangstext und die Kontext-ID für beide gleich sein. In diesem Fall bietet der Kontext nicht ausreichend Informationen, damit sie im Translation Memory als zwei unterschiedliche Einheiten gespeichert werden können, da die Pluralinformationen nicht angegeben sind.
Abschließende Schritte
Gehen Sie folgendermaßen vor, um die Einstellungen zu bestätigen und zum Fenster Dokument-Importoptionen zurückzukehren: Klicken Sie auf OK.
Gehen Sie folgendermaßen vor, um zum Fenster Dokument-Importoptionen zurückzukehren und die Filtereinstellungen nicht zu ändern: Klicken Sie auf Abbrechen.
Wenn es sich um eine Filterverkettung handelt, können Sie die Einstellungen eines anderen Filters in der Kette ändern: Klicken Sie oben im Fenster auf den Namen des Filters.
Im Fenster Dokument-Importoptionen: Klicken Sie erneut auf OK, um die Dokumente zu importieren.