PO Gettext files
PO files are localization files, mostly used for writing multilingual programs on Unix computers. PO Gettext files are bilingual and can contain a single source and target language.
memoQ can directly work with PO Gettext files. The exported file is bilingual.
How to get here
- Start importing a PO Gettext (.po) file.
- In the Document import options window, select the PO Gettext files, and click Change filter and configuration.
- The Document import settings window appears. From the Filter drop-down list, choose PO Gettext filter.
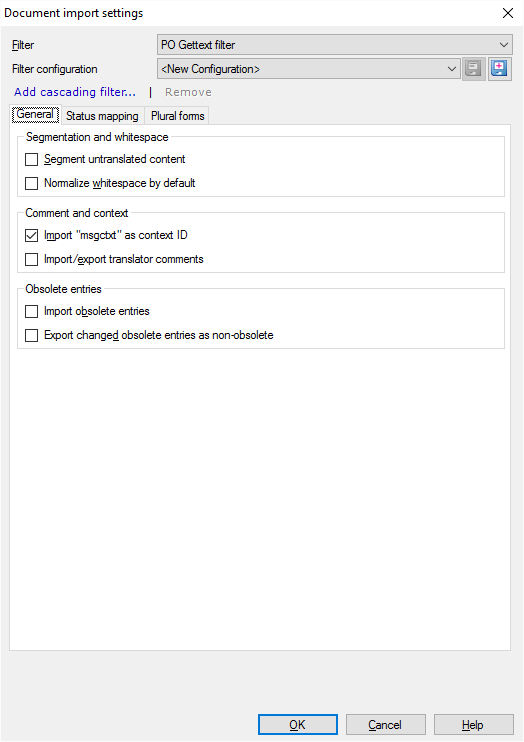
What can you do?
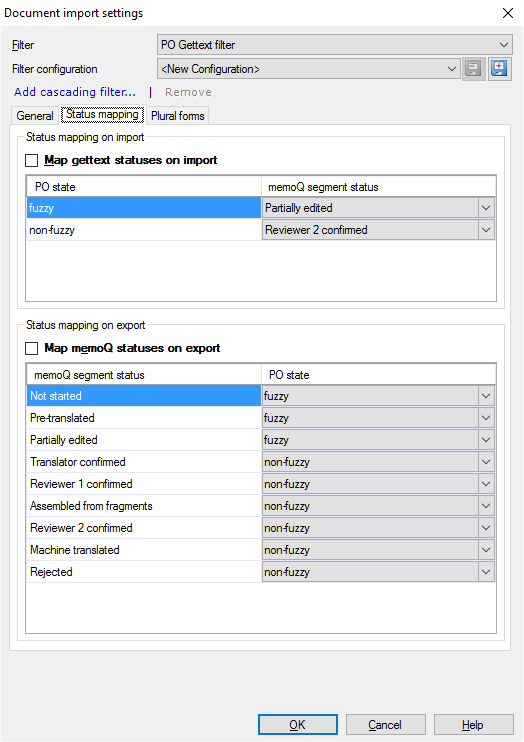
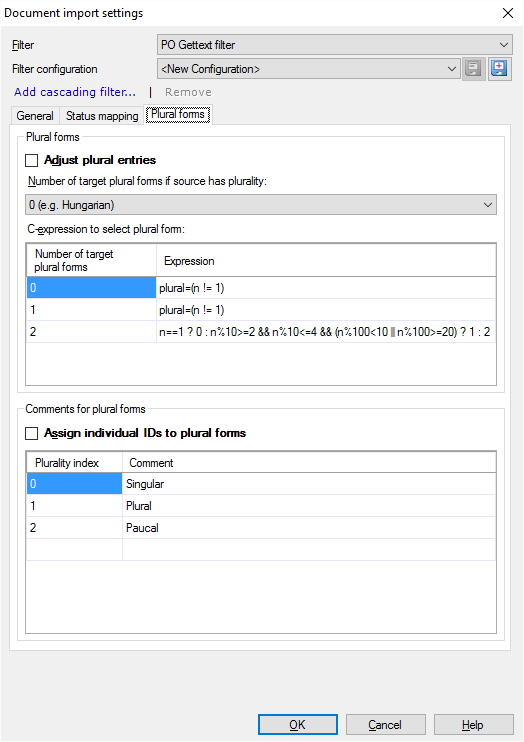
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window.
In the Document import options window: Click OK again to start importing the documents.