XLIFF 2 files (XML Localization Interchange Format version 2.x)
XLIFF (XML Localization Interchange File Format) is an XML-based format created to standardize the way localizable data are passed between tools during translation and localization. It's also a common format for translation tools.
XLIFF files are bilingual or multilingual - XLIFF is not a source document format. The files contain entire segments, similarly to the way memoQ shows them in the translation editor. There is status information; there are tags; and match rates may also be saved. In addition, the XLIFF file may contain "skeleton" and preview data, required to export translated documents. But if the XLIFF file comes from a different tool, memoQ can't interpret the skeleton or the preview data.
XLIFF is a standard: XLIFF was standardized by OASIS in 2002. Its current specification is v2.1, released on 2018-02-13.
XLIFF 1 and XLIFF 2 files are not compatible. To import XLIFF 1 files, use the XLIFF 1 filter,
Use this filter to import XLIFF 2 files from different tools: When you receive an XLIFF 2 file that was saved in another translation tool, use this filter to import it.
XLIFF comes in, XLIFF goes out: After memoQ imports an XLIFF file from a different tool, it can export an XLIFF file only. memoQ can't export the translation in the original format: for that, you need the original tool.
In this window, you can set up how memoQ imports XLIFF 2 files. To keep things simple, we'll call them "XLIFF files" when the difference between versions is not important.
How to get here
- Start importing an XLIFF 2 file.
- In the Document import options window, select the XLIFF 2 files, and click Change filter and configuration.
-
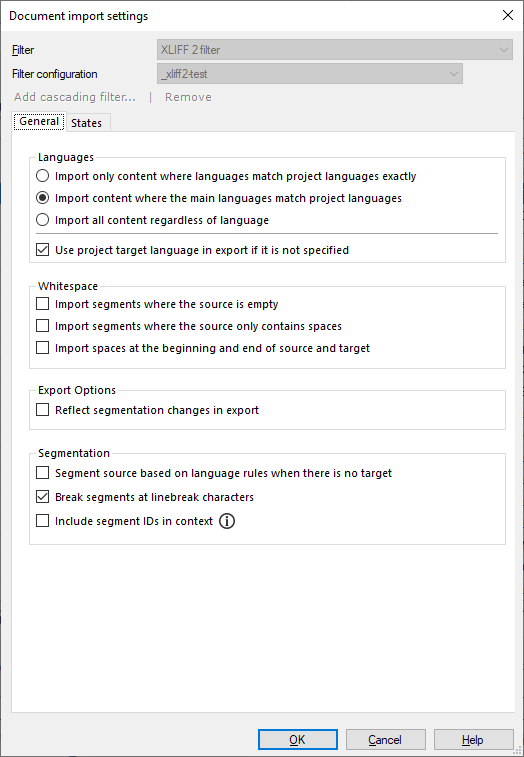
The Document import settings window appears. From the Filter dropdown, choose XLIFF 2 filter.
What can you do?
XLIFF 2 files can be multilingual. In addition, the languages in the XLIFF 2 file may be different from the languages of the project.
Normally, memoQ looks for the main languages of the project in the XLIFF 2 file. If they are found, memoQ imports the text that belongs to those languages. But the sublanguages can be different in the project and the XLIFF 2 file.
- This can be a problem if the XLIFF 2 file has different sublanguages of the same main language (such as US English and UK English). In this case, memoQ won't know which one to import.
- Another problem is if the XLIFF 2 file doesn't have one or more of the languages of the project.
To sort this out: Use the radio buttons on the General tab, under Languages:
- To import only those parts where even the sublanguages are the same as in the project: Click the Import only content where languages match project languages exactly radio button.
- To import every unit from the XLIFF 2 file, regardless of the languages: Click the Import all content regardless of language radio button.
To export the translation with the correct target language code: The target-language segments may be missing from the XLIFF 2 file. When these are translated, memoQ exports them with the target language of the project. If, for any reason, you need to keep the language codes in the XLIFF 2 file after export, clear the Use project's target language in export if it is not specified check box.
Normally, memoQ drops whitespace at the beginning and end of XLIFF segments. To keep those in the imported document: Check the Import spaces at the beginning and end of source and target check box.
Normally, memoQ does not import XLIFF segments that are empty or contain only spaces. To change this: Check the Import segments where the source is empty or Import segments where the source only contains spaces check box as needed.
XLIFF 2 files contain segmented text in the form of <segment> elements. (They also have text in <ignorable> elements, but memoQ does not import those.)
Normally, memoQ leaves the XLIFF segmentation as it is: Whatever was one segment in the XLIFF file will become one segment in memoQ.
In the translation editor, you can normally split and join memoQ segments within an XLIFF <unit> element's content.
For <segment> elements that do not have a <target> element inside, you can decide whether or not you need to segment the text inside their <source> elements.
To split untranslated, unsegmented text in the <segment> elements:
- To start a new segment at the end of every sentence: Check the Segment source based on language rules when there is no target check box. memoQ will segment the source text based on the segmentation rules set up for the project.
-
To start a new segment at newline characters: Check the Break segments at linebreak characters check box.
If this check box is checked, and a <segment> has both <source> and <target> elements, they might contain a different number of newline characters. This would mean a different number of source and target segments. To solve this problem:
- memoQ pairs one source and one target segment as long as it is possible.
- If there are no more source segments, all remaining target content gets into the last segment.
- If there are no more target rows, the remaining segments will have empty target cells.
If the Break segments at linebreak characters check box is cleared, memoQ imports newline characters as inline tags.
The XLIFF 2 filter always imports IDs from the XLIFF file structure: Normally, it puts together any group and unit IDs to create the segment's context.
For example, if a <unit id="unit2"> element has <segment id="s1"> and <segment id="s2"> inside, memoQ imports context for those segments as unit2. This allows joining segments that belong to the same unit.
To add the segment IDs to the context (that is, to have unit2-s1 and unit2-s2 as context in our example): Check the Include segment IDs in context check box. But when you do this, you will not be able to join those segments.
Normally, the exported XLIFF 2 target document has same structure as the imported source. To change the structure of the exported target file based on split or joined memoQ segments, check the Reflect segmentation changes in export check box. The setting works like this:
-
memoQ adds a number to the id attribute value of split segment parts. For example, split segments of the original <segment id="s1"> will be <segment id="s1-1">, <segment id="s1-2">, etc.
-
memoQ puts together the id attribute values of joined segments. For example, the joined segments <segment id="s1"> and <segment id="s2"> will be <segment id="s1-s2">. (To do this, make sure the Include segment IDs in context check box is cleared.)
This setting only works when <segment> elements have IDs.
When an XLIFF 2 document has <note> elements, memoQ imports their content as comments. Notes for <file>, <group>, and <unit> elements show for each of their child segments in memoQ. Notes that have the appliesTo attribute apply to either the source or the target text.
memoQ also imports the content of <meta> tags as comments. All <meta> content within one <metaGroup> gets into one comment.
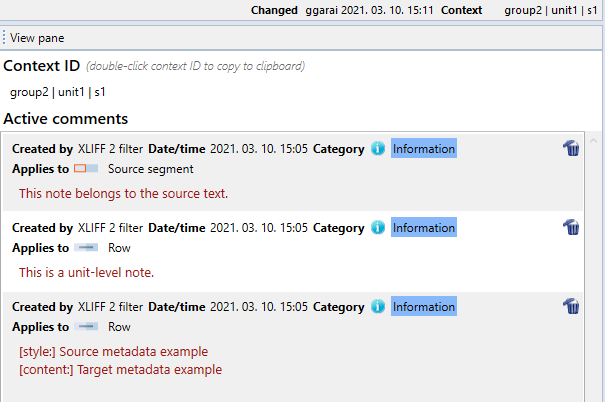
Comments created in memoQ do not get exported into the XLIFF files, but the original <note> elements stay there.
<unit> elements in XLIFF 2 documents may have an <originalData> child element that contains information about placeholders in that unit's text. memoQ imports these data as inline tags, and shows their content based on tag detail level.
Segments may contain <mrk> tags that most often mark a term or a comment. memoQ imports these data as inline tags, and shows their content based on tag detail level. If an opening <mrk> tag contains the <translate="no"> attribute, memoQ imports the tag pair and the text between them as one single empty tag. In this case, the Filtered option shows the type (term or comment) and the text between the tags. The Medium option shows only the text between the tags.
In an XLIFF 2 document, some parts may be marked as "not to be translated". Each <file>, <group>, or <unit> element can have a translate attribute. If content is not to be translated, this attribute is set to "no". The XLIFF 2 filter imports these parts as locked segments. You can unlock them in memoQ after importing.
XLIFF 2 is a document format that has everything that a translation tool needs. So, the status of segments can also be stored in XLIFF 2 files.
Standard XLIFF 2 has a specific set of states, but translation tools can add their own subState attributes - so it's not entirely standard.
Only states can be mapped: memoQ currently does not handle subState attributes.
To see (and change) how XLIFF 2 states are mapped into memoQ segment statuses: Click the States tab.
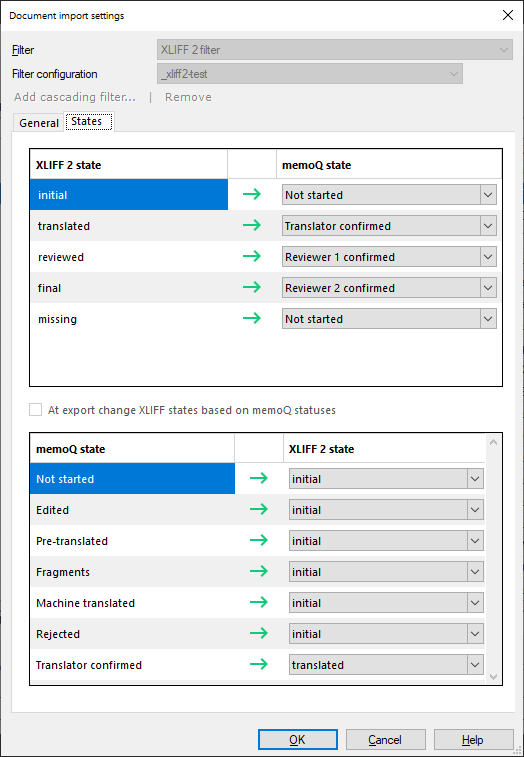
On this tab, you can match the segment status codes in memoQ to the standard segment states in XLIFF 2. For example, memoQ may import the initial state in XLIFF 2 as Not started, and export the status Translator confirmed as translated in XLIFF 2.
The Import list shows how XLIFF 2 states are translated into memoQ segment status codes when memoQ imports an XLIFF document.
To change the mapping: In one of the dropdowns next to an XLIFF 2 state, choose a different memoQ status code.
To export the XLIFF 2 document with segment states mapped to memoQ segment statuses: Check the At export change XLIFF states based on memoQ statuses check box.
In the list below, you can set an XLIFF 2 state attribute value for each memoQ segment status. To change the XLIFF 2 state: Choose one from the dropdown. You cannot add new export mappings because the segment status codes are hard-coded in memoQ.
When you finish
To confirm the settings, and return to the Document import options window: Click OK.
To return the Document import options window, and not change the filter settings: Click Cancel.
In the Document import options window: Click OK again to start importing the documents.