Filtern nach TM-Dubletten
Sie können doppelte Einträge aus einem Translation Memory entfernen.
Möglicherweise entstehen viele Dubletten, wenn Sie einen der folgenden Vorgänge ausführen:
- Bestätigen von zahlreichen identischen Übersetzungen mit jeweils unterschiedlichem Kontext in das TM
- Verwenden eines Translation Memory, in dem mehrere Übersetzungen für ein und dasselbe Ausgangssegment und ein und denselben Kontext zulässig sind
- Verwenden eines Translation Memory ohne Kontextinformationen
- Importieren von TMX-Dateien in das Translation Memory mit vielen identischen Ausgangssegmenten
- Bestätigen von zahlreichen Nichttextsegmenten (reinen Zahlensegmenten oder aus Strichen bestehenden Segmenten usw.)
Im Fenster Nach Dubletten filtern können Sie nach den Dubletten in Ihrem Translation Memory suchen. Sie können diesen Vorgang für jeweils ein Translation Memory ausführen.
Schließlich erhalten Sie Gruppen mit Einträgen. Einträge in ein und derselben Gruppe sind auf irgendeine Weise Dubletten – gemäß den im Fenster Nach Dubletten filtern eingerichteten Bedingungen.
Navigation
- Beginnen Sie mit der Bearbeitung eines Translation Memory.
-
Klicken Sie auf der Registerkarte Translation-Memory-Editor des Menübands auf Dubletten entfernen. Das Fenster Nach Dubletten filtern wird angezeigt.
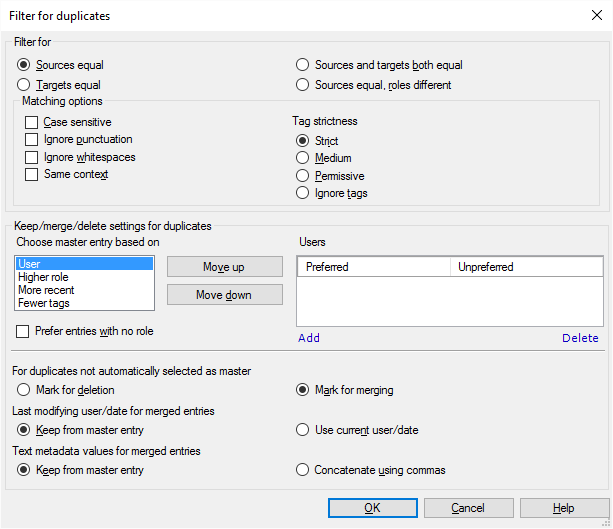
Möglichkeiten
Zwei Einträge sind normalerweise Dubletten, wenn der Ausgangstext in beiden Einheiten identisch ist.
- Unter Filtern nach können Sie die entsprechenden Einstellungen anpassen. Für Ihre Auswahl stehen Ihnen Optionsfelder zur Verfügung.
Bereinigen von nicht überarbeiteten, nicht bestätigten Übersetzungen in einem Translation Memory: Klicken Sie auf Ausgangstexte gleich, Rollen unterschiedlich. Dadurch werden die Einträge angezeigt, bei denen dasselbe Segment von einem Übersetzer und auch von einem Überprüfer bestätigt wurde. In diesem Fall behalten Sie das von einem Überprüfer bestätigte Segment.
- Ausgangstexte gleich: Einträge sind Dubletten, wenn der Ausgangstext bei beiden identisch ist.
- Zieltexte gleich: Einträge sind Dubletten, wenn der Zieltext in beiden Einheiten identisch ist.
- Ausgangs- und Zieltexte gleich: Einträge sind Dubletten, wenn der Ausgangstext sowie der Zieltext bei beiden identisch sind.
- Ausgangstexte gleich, Rollen unterschiedlich: Einträge sind Dubletten, wenn der Ausgangstext in den Einheiten identisch, die Rolle, in der sie bestätigt wurden, jedoch unterschiedlich ist. Eine kann beispielsweise von einem Übersetzer und die andere von einem Überprüfer 2 bestätigt worden sein. Verwenden Sie diese Option, um nicht überarbeitete Übersetzungen im Translation Memory zu entfernen.
- Wählen Sie als Nächstes aus, wie die Segmente verglichen werden, also was als "gleich" gilt. Entscheiden Sie, wie streng Sie dies handhaben möchten. Dies können Sie mit den Kontrollkästchen und Optionsfeldern unter Übereinstimmungsoptionen einrichten. Normalerweise sind alle Kontrollkästchen deaktiviert, das heißt, zwei Segmente sind identisch, wenn sie genau die gleichen Wörter, Tags, Leerzeichen und die gleiche Interpunktion aufweisen. Der Kontext des Ausgangssegments und die Groß-/Kleinschreibung können unterschiedlich sein.
- So berücksichtigen Sie beim Abgleich die Groß-/Kleinschreibung, sodass sie ebenfalls übereinstimmen muss: Aktivieren Sie das Kontrollkästchen Groß-/Kleinschreibung.
- So nehmen Sie zwei Segmente als identisch an, selbst wenn die Interpunktion unterschiedlich ist: Aktivieren Sie das Kontrollkästchen Satzzeichen ignorieren.
- So nehmen Sie zwei Segmente als identisch an, selbst wenn die Leerzeichen unterschiedlich sind: Aktivieren Sie das Kontrollkästchen Leerräume ignorieren.
- So nehmen Sie zwei Ausgangssegmente nur als identisch an, wenn der jeweilige Kontext gleich ist: Aktivieren Sie das Kontrollkästchen Gleicher Kontext.
- Permissiv bedeutet, dass nur die Anzahl der Tags gleich sein muss.
- Medium bedeutet, dass die Tags den gleichen Typ (öffnend/schließend/leer) aufweisen müssen, aber die Tag-Namen und Attribute unterschiedlich sein können.
- Genau bedeutet, dass die Tags genau gleich sein müssen. Standardmäßig wird diese Einstellung in memoQ verwendet.
Sie können die entsprechenden Einstellungen unter Beibehalten/Zusammenfügen/Löschen-Einstellungen für Dubletten anpassen.
In einer Gruppe mit doppelten Einträgen wird ein Eintrag immer als "Mastereintrag" verwendet. Sie können festlegen, wie mit den anderen Einträgen in der Gruppe verfahren wird:
- Sie können sie löschen.
- Sie können zusätzliche Angaben aus den Einheiten im Mastereintrag zusammenfügen.
- Sie können sie beibehalten, sodass die Dublette bestehen bleibt.
Sie können Ihre Auswahl für die jeweilige Gruppe treffen, wenn wieder der Translation-Memory-Editor angezeigt wird.
Als Erstes muss festgelegt werden, welcher Eintrag der Mastereintrag in der Gruppe ist. Wählen Sie ein Element der Liste Mastereintrag auswählen basierend auf: Benutzer, Höhere Rolle, Aktueller, Weniger Tags. Beispielsweise können Sie als Mastereintrag einen Eintrag verwenden, der von einem bestimmten Benutzer hinzugefügt wurde. Normalerweise wird dieser Logik gefolgt:
- Als Mastereintrag wird der Eintrag verwendet, der von einem bevorzugten Benutzer stammt.
- Wenn nicht ein Eintrag mit einem bevorzugten Benutzer vorhanden ist, wird die Einheit ausgewählt, die in der höheren Rolle bestätigt wurde. Überprüfer 2 ist beispielsweise höher als Übersetzer, und Übersetzer ist höher als ein Eintrag ohne Rolle. Sie können auch die Einträge ohne Rolle als höchste Einheiten festlegen: Aktivieren Sie dazu das Kontrollkästchen Einträge ohne Rolle bevorzugen.
- Wenn nicht ein Eintrag mit der höchsten Rolle vorhanden ist, wird der aktuellste Eintrag ausgewählt.
- Wenn mehrere Einträge mit dem gleichen Zeitstempel vorhanden sind, wird der Eintrag ausgewählt, der weniger Tags im Ausgangs- und im Zielsegment aufweist.
Sie können die Reihenfolge dieser Bedingungen ändern. Klicken Sie auf eine Bedingung, und klicken Sie auf die Schaltfläche Nach oben bzw. Nach unten.
In der Liste Benutzer können Sie die bevorzugten Benutzer auflisten. Dabei handelt es sich um leitende Mitarbeiter, d. h. um Überprüfer, die regelmäßig Segmente in der Rolle Überprüfer 1 oder Überprüfer 2 bestätigen. Klicken Sie auf Hinzufügen, um einen bevorzugten Benutzer hinzuzufügen. So entfernen Sie einen Benutzer aus der Liste: Klicken Sie auf den Namen des Benutzers. Klicken Sie auf Entfernen.
Sie haben auch die Möglichkeit, nicht bevorzugte Benutzer hinzuzufügen. Wenn Sie eine Liste mit nicht bevorzugten Benutzern angeben, werden andere Benutzer ihnen gegenüber bevorzugt behandelt. Beispiel: Wenn die Dublettengruppe vier Einträge von nicht bevorzugten Benutzern enthält und einen von einem Benutzer, der nicht in der Liste aufgeführt ist, wird dieser fünfte Benutzer für den Mastereintrag ausgewählt.
Wählen Sie anschließend aus, wie mit den Einträgen verfahren wird, die im Mastereintrag zusammengefügt werden.
Sie können mehr als einen Benutzer zu diesen Listen hinzufügen, wenn dessen Benutzernamen mit den gleichen Zeichen beginnen. Wenn beispielsweise alle Übersetzer Benutzernamen wie tr-jp1, tr-fr3, tr-de1 aufweisen, können Sie alle zur Nicht bevorzugt-Liste hinzufügen. Klicken Sie auf den Link Hinzufügen: Aktivieren Sie im Fenster Bevorzugten/nicht bevorzugten Benutzer hinzufügen das Kontrollkästchen Das ist ein Benutzernamen-Präfix. Geben Sie tr- in das Feld Benutzername ein und klicken Sie auf OK. Die Spalte Nicht bevorzugt hat nun eine Zeile "tr-*". Das heißt, dass memoQ alle Benutzer, deren Benutzername mit „tr-“ beginnt, als nicht bevorzugte Benutzer behandelt.
- Für nicht automatisch als Master ausgewählte Dubletten: Klicken Sie auf Für Löschen markieren oder Für Zusammenfügen markieren. Normalerweise werden die Nicht-Mastereinträge für das Zusammenfügen im Mastereintrag markiert.
Wählen Sie "Für Löschen markieren" nur dann aus, wenn Sie sich absolut sicher sind, dass die doppelten Einträge völlig identisch sind, also alle Segmente, alle Tags, alle Kontexte und alle Felder gleich sind. In allen anderen Fällen sollten Sie Für Zusammenfügen markieren auswählen. Andernfalls gehen Informationen aus dem Translation Memory verloren.
- Zuletzt ändernder Benutzer/geändertes Datum für zusammengefügte Einträge: Wählen Sie aus, ob das Änderungsdatum und der zuletzt ändernde Benutzer aus dem Mastereintrag oder aus der aktuellen Bearbeitungssitzung übernommen werden sollen. Klicken Sie auf Aus Mastereintrag beibehalten oder Aktuellen Benutzer/Datum verwenden. Die Datums- und Benutzerangaben aus den Nicht-Mastereinträgen (den zusammengefügten Einträgen) können nicht beibehalten werden.
- Text-Meta-Daten-Werte für zusammengefügte Einträge: Wenn die Meta-Daten-Felder im Mastereintrag und in den Nicht-Mastereinträgen (den zusammengefügten Einträgen) sich widersprechende Inhalte enthalten, wählen Sie aus, wie damit verfahren werden soll. Sie können den Wert aus dem Mastereintrag oder alle Angaben verwenden, wobei sie durch Kommas getrennt aneinandergereiht werden. Klicken Sie für Ersteres auf Aus Mastereintrag beibehalten. Klicken Sie für Letzteres auf Mithilfe von Kommas verketten.
Abschließende Schritte
So suchen Sie nach allen Dubletten und kehren zum Translation-Memory-Editor zurück: Klicken Sie auf OK.
So kehren Sie zum Translation-Memory-Editor zurück, ohne nach den Dubletten zu suchen: Klicken Sie auf Abbrechen.
Nachdem die Dubletten gefunden wurden, wird eine spezielle Liste angezeigt, die die Gruppen mit Dubletten enthält und nicht die einzelnen Einträge.
Weitere Informationen: siehe Dokumentation zum Translation-Memory-Editor.