XML-Dateien (eXtensible Markup Language)
XML ist das weltweit vielseitigste Datenformat. XML-Dateien können Text, strukturierte Daten und selbst Programmcode enthalten. Der wohl größte Vorteil liegt darin, dass XML-Dateien von Mensch und Maschine gleichermaßen gut lesbar sind.
Das XML-Format definiert eine Art Markup, mit dem nahezu alles Erdenkliche codiert werden kann. XML kann wie folgt aussehen:
XML kann wie folgt aussehen:
<thing>
<part-of-thing looks="good">
Here is the part of thing
</part-of-thing>
</thing>
Ein umschlossener Teil wie <thing>...</thing> wird als Element bezeichnet.
Der Teil für die Codierung ("<thing>", "</thing>", "<part-of-thing>" usw.) wird als Tag bezeichnet. "<thing>" oben ist ein öffnendes Tag und "</thing>" unten ein schließendes Tag. Es kann Elemente ohne Inhalt geben. Diese könnten als "<emptiness></emptiness>" angegeben werden, in XML wird dies jedoch durch die Angabe von "<emptiness/>" vereinfacht. Dabei handelt es sich um ein sogenanntes leeres Tag.
In einem Tag, mit dem ein Element beginnt, können Teile vorhanden sein, die das Element beschreiben. Sie werden als Attribute bezeichnet. Im Beispiel ist "looks="good"" ein Attribut. Ein Attribut verfügt über einen Namen ("looks") und einen Wert ("good").
Dabei besteht ein Problem: In XML ist Text mit Markup gemischt. Im Markup sind zwei Zeichen sehr speziell: < und >. Der Text in den Elementen darf diese Zeichen nicht enthalten. Stattdessen wird in XML < (kleiner als) für "<" und > (größer als) für ">" angegeben.
Alles, was im XML-Text wie &(Symbol); aussieht, stellt ein einzelnes Zeichen dar. Diese werden als Zeichenentitäten oder einfach nur Entitäten bezeichnet. Bei einem weiteren Zeichen, dem Et-Zeichen ("&"), handelt es sich ebenfalls um ein Sonderzeichen. Wenn Sie also im Text ein reales Et-Zeichen angeben möchten, müssen Sie die Entität & angeben.
Wenn Sie einen bestimmten Typ von Dokument oder bestimmte Daten in XML beschreiben möchten, müssen Sie festlegen, welche Elemente, Tags, Attribute und Entitäten verwendet werden. Wenn ein bestimmtes auf XML basiertes Dokumentformat erstellt wird, heißt das, dass Sie ein wohldefiniertes Set an Tags in einer wohldefinierten Struktur ausgewählt haben. HTML ist ein Beispiel dafür. In HTML können nicht einfach beliebige Tags verwendet werden. Für die zu verwendenden Tags gibt es Regeln. Wenn Sie andere Tags verwenden, die in den HTML-Regeln nicht definiert sind, wird das Dokument ungültig.
Die Regeln, mit denen die Tags und Attribute beschrieben werden, die Sie in einem Typ von XML-Dokument verwenden können, werden als Dokumenttypdefinition bezeichnet. Ein Dokumenttyp wird in separaten Dateien beschrieben. Dabei handelt es sich entweder um eine Dokumenttypdefinitionsdatei (DTD-Datei) oder um ein XML-Schema.
In vielen Fällen enthalten XML-Dateien Text. Und Text muss übersetzt werden.
Viele bekannte Dokumenttypen sind verschleierte XML-Dokumente. HTML ist XML. Word-Dokumente, zumindest das DOCX-Format, sind XML. XLIFF-Dateien sind XML. TMX-Dateien mit Translation-Memory-Inhalten sind XML. Es gibt noch viele weitere, und bei allen handelt es sich um unterschiedliche Formen von XML-Dateien. Eine bestimmte Form von XML-Dokument wird als Dokumenttyp bezeichnet.
XML-Dokumente können in memoQ verarbeitet werden. Wenn das verwendete Dokument jedoch in einer bekannten XML-Form vorliegt (z. B. HTML, DOCX oder XLIFF), verfügt memoQ in der Regel über den jeweiligen speziellen Filter. Zudem wird der entsprechende spezielle Filter automatisch ermittelt, wenn Sie das Dokument öffnen. Wenn Sie ein Word-Dokument importieren, wird daher niemals die Verwendung des XML-Filters vorgeschlagen. Trotzdem wird in memoQ der Großteil des Dokuments mithilfe des XML-Filters gelesen.
In vielen Programmierungs- und Datenbanksystemen werden Inhalte in XML-Dateien gespeichert – oder exportiert. Wenn Sie diese Dateien in memoQ übersetzen, verwenden Sie diesen XML-Filter, um sie zu importieren.
XML-Dateien können mehrsprachig sein. Verwenden Sie dafür den Filter für mehrsprachige XML-Dateien: Manche XML-Dateien enthalten den gleichen Text in mehreren Sprachen. Verwenden Sie zum Importieren dieser Dateien den Filter für mehrsprachige XML-Dateien.
XML-Konfigurationen sind komplex, und es lohnt sich, sie zu speichern: Es kann mehrere Stunden dauern, um memoQ so vorzubereiten, dass alles richtig importiert wird. Stellen Sie daher sicher, dass Sie nach Abschluss der Vorbereitung im Fenster "Einstellungen für Dokumentenimport" auf die Schaltfläche "Speichern" neben der Dropdown-Liste "Filterkonfiguration" klicken. Wenn Sie das nächste Mal eine XML-Datei der gleichen Herkunft importieren möchten, können Sie in derselben Dropdown-Liste "Filterkonfiguration" einfach die gespeicherte Konfiguration auswählen.
Navigation
- Importieren Sie eine XML-Datei.
- Wählen Sie im Fenster Dokument-Importoptionen die XML-Dateien aus, und klicken Sie auf Filter und Konfiguration ändern.
- Das Fenster Einstellungen für Dokumentenimport wird angezeigt. Wählen Sie aus der Dropdown-Liste Filter die Option XML-Filter.

Möglichkeiten
Um eine XML-Datei problemlos importieren zu können, müssen Sie zahlreiche Einstellungen vornehmen. Zur Vereinfachung wird in diesem Thema das folgende Beispiel verwendet:
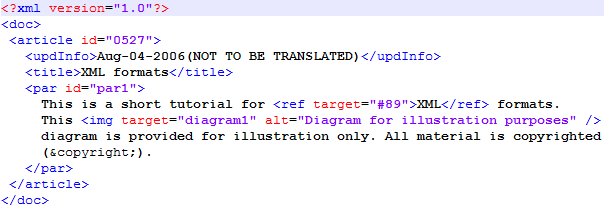
Wie jedes XML-Dokument enthält es "normalen" Text, der übersetzt werden soll, aber auch Tags wie <doc>, die in erster Linie beschreibende bzw. strukturelle Informationen beinhalten. Tags können Attribute aufweisen, die Werte besitzen (id="0527"). In den folgenden Abschnitten wird erläutert, wie diese Elemente in memoQ interpretiert werden können.
Überprüfen Sie, ob in memoQ die richtige Zeichencodierung zum Importieren der XML-Dateien verwendet wird. Normalerweise gibt die Kopfzeile der XML-Datei die Codierung an. Wenn sie fehlt, wird in memoQ im Allgemeinen die UTF-8-Codierung verwendet. Überprüfen Sie im Bereich Vorschau, ob alles korrekt dargestellt wird. Wenn dies nicht der Fall ist, wählen Sie in der Liste Standardcodierung eine andere Codierung aus.
Diese Codierung gilt nur für die Vorschau und die Referenzdateien: Die eigentliche Codierung für den Import und Export müssen Sie auf der Registerkarte Allgemein noch einrichten.
Anhand der Dokumenttypdefinition (DTD) oder des XML-Schemas (XSD) kann in memoQ ermittelt werden, welche Tags und Attribute im XML-Dokument vorhanden sein können. Ohne eine DTD-Datei oder ein XML-Schema werden eine oder mehrere Referenzdateien gelesen, um die Tags und Attribute zu ermitteln. Normalerweise werden automatisch alle Dokumente hinzugefügt, die Sie als Referenzdateien importieren. Klicken Sie zum Hinzufügen weiterer Dateien auf Datei hinzufügen.
Verwenden Sie immer das Schema oder die DTD, wenn diese verfügbar sind: Wenn Sie über die DTD oder das XML-Schema verfügen, rufen Sie sie bzw. es ab: Klicken Sie neben dem Feld DTD/Schema auf Durchsuchen, und suchen Sie die DTD- oder die XSD-Datei.
In memoQ kann bei vorhandener DTD oder vorhandenem XML-Schema automatisch eine Filterkonfiguration ausgewählt werden: Klicken Sie bei Verwendung einer DTD oder eines XML-Schemas auf die Registerkarte Allgemein, und geben Sie im Feld DTD oder URL von Namespace den Namen (nur den Namen) der DTD-Datei ein. Wenn Sie über ein Schema verfügen, enthält die XSD-Datei eine Adresse für den Namespace. Kopieren Sie diesen aus der Datei in das Feld DTD oder URL von Namespace. Vergessen Sie nicht, die Filterkonfiguration zu speichern. Beim nächsten Import einer XML-Datei mit der gleichen DTD oder dem gleichen Schema wird automatisch dieselbe Konfiguration geladen, da sie der DTD bzw. dem Schema zugeordnet wurde.
Normalerweise gibt die Kopfzeile der XML-Datei die Codierung an.
Im Allgemeinen wird in memoQ versucht, die Codierung der importierten Dateien zu ermitteln. Wenn die Codierung in der XML-Datei nicht angegeben ist, wird die UTF-8-Codierung verwendet.
Wenn Sie diese ändern möchten, klicken Sie auf die Registerkarte Allgemein und verwenden Sie die Einstellungen unter Inhalt.
Wenn die Codierung in memoQ nicht korrekt erkannt wurde: Deaktivieren Sie das Kontrollkästchen Codierung ermitteln, wenn möglich. Wählen Sie in der Dropdown-Liste Eingabecodierung, wenn nicht erkannt die gewünschte Codierung aus. Sie können die Codierung auf der Registerkarte Codierung und Referenzdateien im Feld Vorschau überprüfen.
Wenn als Eingabecodierung nicht Unicode verwendet wird und für die Zielsprache eine andere Schrift als in der Ausgangssprache verwendet wird: Wählen Sie in der Dropdown-Liste Ausgabecodierung die Codierung aus, die beim Exportieren der Übersetzung in memoQ verwendet werden soll. Im Allgemeinen wird dieselbe Codierung wie im Ausgangsdokument verwendet, wobei es völlig normal ist, wenn die Eingabecodierung eine Form von Unicode ist (z. B. UTF-8).
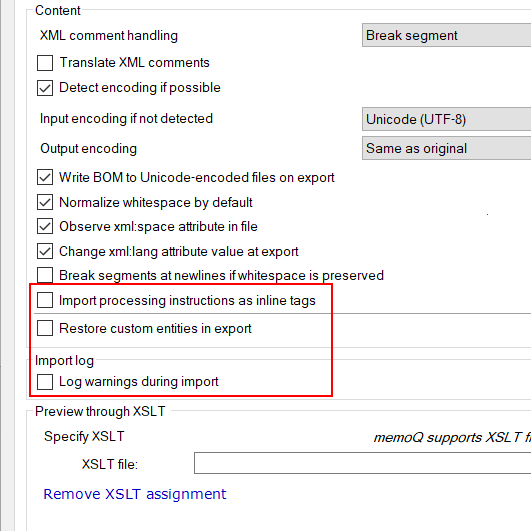
Normalerweise werden XML-Dateien in memoQ mit einer Bytereihenfolge-Marke am Anfang der Datei exportiert. Dies ist für einige Content-Management-Systeme erforderlich. In anderen Systemen wird sie ignoriert. Deaktivieren Sie also das Kontrollkästchen BOM in Unicode-codierte Dateien beim Export schreiben nicht.
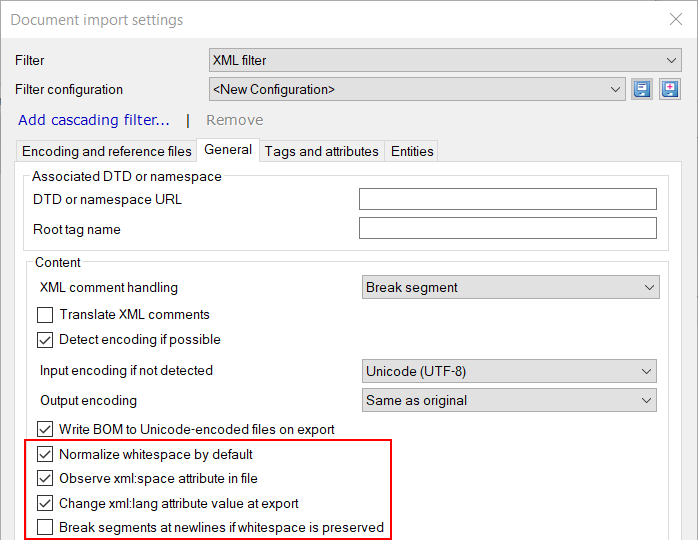
Mehrere Leerzeichen mit nur einem Leerzeichen ersetzen: Normalerweise werden Folgen von Tabstopps, Leerzeichen oder Zeilenumbruchzeichen in memoQ in ein einzelnes Leerzeichen umgewandelt. Zudem werden Leerraumfolgen am Anfang und am Ende von Elementen gelöscht. Verwenden Sie diese Option, wenn das XML-Dokument zur Verbesserung der Lesbarkeit nur Leerzeichen verwendet. Wenn die Leerraumzeichen für die Formatierung oder Struktur erforderlich sind, deaktivieren Sie das Kontrollkästchen Mehrere Leerzeichen mit nur einem Leerzeichen ersetzen.
Hinweis: In dem Beispieldokument enthält der Text innerhalb des Elements <par> Zeilenumbrüche und Leerzeichen, die keine wichtigen Informationen enthalten – sie erleichtern dem menschlichen Auge lediglich die Lesbarkeit des Dokuments. Andererseits kann es schwierig sein, diese Leerraumzeichen während der Übersetzung zu bearbeiten. Lassen Sie also in diesem Fall die Leerraumnormalisierung eingeschaltet.
memoQ behält keine Leerzeichen innerhalb von Tags bei: Auch wenn Sie Mehrere Leerzeichen mit nur einem Leerzeichen ersetzen deaktivieren, entfernt memoQ alle zusätzlichen Leerzeichen innerhalb von Tags. Wenn zum Beispiel das Ausgangsdokument <br /> enthält, exportiert memoQ immer <br/>, d. h. ohne das Leerzeichen.
Attribut "xml:space" in Datei beachten: XML-Dokumente können Attribute enthalten, durch die vorgegeben wird, ob Leerräume in einem bestimmten Element normalisiert werden sollen. Normalerweise werden in memoQ diese in den Dokumenten enthaltenen Anweisungen befolgt. Wenn Leerräume im gesamten Dokument gleich behandelt werden sollen, deaktivieren Sie das Kontrollkästchen Attribut "xml:space" in Datei beachten.
Attributwert xml:lang beim Export ändern: Normalerweise überschreibt memoQ xml:lang-Attributwerte mit dem ISO-Code der tatsächlichen Zielsprache. Wenn Sie die ursprünglichen Werte für dieses Attribut beibehalten wollen, deaktivieren Sie das Kontrollkästchen Attributwert xml:lang beim Export ändern.
Segmentierung bei Umbrüchen, wenn Leerräume beibehalten werden: Aktivieren Sie dieses Kontrollkästchen, wenn bei jedem Zeilenumbruchzeichen ein neues Segment beginnen soll. Der aus XML-Dateien importierte Text kann nur Zeilenumbruchzeichen enthalten, wenn Leerräume beibehalten werden sollen, d. h., wenn das Kontrollkästchen Mehrere Leerzeichen mit nur einem Leerzeichen ersetzen deaktiviert ist oder wenn dies im "xml:space"-Attribut angegeben ist. Wenn Leerraumzeichen beibehalten werden, wird davon ausgegangen, dass Zeilenumbruchzeichen im Text eine Bedeutung haben, und im Allgemeinen sollte dann jede Zeile als separates Segment übersetzt werden.
Es empfiehlt sich, das Kontrollkästchen Segmentierung bei Umbrüchen, wenn Leerräume beibehalten werden zu aktivieren, wenn Sie das Kontrollkästchen Mehrere Leerzeichen mit nur einem Leerzeichen ersetzen deaktivieren.
In einigen XML-Dateien müssen auch die Kommentare übersetzt werden. Normalerweise werden diese in memoQ nicht importiert.
Wenn Sie dies ändern möchten, klicken Sie auf die Registerkarte "Allgemein".
So importieren Sie die XML-Kommentare zur Übersetzung: Aktivieren Sie das Kontrollkästchen XML-Kommentare übersetzen.
Normalerweise wird bei jedem in memoQ erkannten Kommentar ein neues Segment begonnen. Wenn die Kommentare übersetzt werden sollen, werden sie in ein separates Segment an der Position importiert, an der sie sich im Text befinden. Kommentare werden entsprechend den Segmentierungsregeln im Projekt segmentiert.
So importieren Sie die XML-Kommentare als Inline-Tags: Wählen Sie in der Dropdown-Liste XML-Kommentarhandhabung die Option Als <mq:cmt> Tag importieren aus. Die Kommentare werden in besondere Inline-Tags (mq:cmt) transformiert. Wenn die Kommentare übersetzt werden sollen, sind sie zu übersetzende Attribute des Inline-Tags mq:cmt. Auf der Registerkarte Tags und Attribute müssen Sie diese Attribute als zu übersetzen markieren. In diesem Fall wird der Text der Kommentare nicht segmentiert.
Verwenden Sie keine älteren memoQ-{Tags}: Wählen Sie in der Dropdown-Liste „XML-Kommentarhandhabung“ nicht die Option Als memoQ {tag} importieren aus.
64-Zeichen-Vorschau, wenn Kommentare nicht übersetzt werden: Wenn Sie keine Kommentare zur Übersetzung importieren, werden im Übersetzungseditor die ersten 64 Zeichen in der gefilterten und in der langen Ansicht von Tags als Vorschauen angezeigt. Der vollständige Text der Kommentare wird mit der Strukturdatei der XML-Datei gespeichert, sodass sie wieder in die übersetzte Datei exportiert werden können.
Normalerweise wird in memoQ eine Standardvorschau von XML-Dokumenten angezeigt. In dieser Vorschau werden alle Tags und die Struktur des Dokuments angezeigt.
Wenn das XML-Dokument jedoch einen formatierten Text enthält, kann eine Vorschau mit besserer Formatierung generiert werden.
Normalerweise umfasst XML keine Angaben zur tatsächlichen Formatierung. Diese Informationen müssen von außerhalb hinzugefügt werden. Dazu ist ein XML-Stylesheet oder eine XML-Stylesheetvorlage (XSLT) erforderlich.
Mit XSLT werden die XML-Dateien in ein anderes Format transformiert, das gut dargestellt werden kann. Wenn eine XML-Datei über XSLT z. B. in HTML konvertiert wird, kann sie in einem Webbrowser angezeigt werden.
In memoQ werden XSLT-Dateien unterstützt, die XML-Dateien in HTML transformieren. Sie müssen diese Datei selbst erstellen. Diese Dateien können in memoQ nicht erstellt werden.
Informationen zum Erstellen von XSLT-Dateien finden Sie auf dieser Webseite: https://www.w3schools.com/xml/xsl_intro.asp. Zur Warnung: Sie müssen Interesse für Programmierung mitbringen, um daraus einen Nutzen zu ziehen.

Klicken Sie nach dem Erstellen der XSLT-Datei auf die Schaltfläche mit den drei Punkten  neben dem Feld für die XSLT-Datei.
neben dem Feld für die XSLT-Datei.
XSLT muss HTML generieren: Mit dem XML-Stylesheet muss eine HTML-Ausgabe erstellt werden. Wenn mit dem Stylesheet ein anderes Format (Nur-Text, RTF oder ein anderes XML-Format) ausgegeben wird, können Sie es hier nicht verwenden.
So ändern Sie die XSLT-Vorschau: Klicken Sie auf XSLT-Zuweisung entfernen. Geben Sie dann bei Bedarf eine andere XSLT-Datei an.
Auf der RegisterkarteAllgemein werden weitere Einstellungen angezeigt (siehe Screenshot unten).
-
XML-Dateien können Verarbeitungsanweisungen enthalten. Sie sehen wie Tags aus, beginnen jedoch mit den Zeichen „<?“. Sie werden von dem Content-Management-System ausgeführt, in dem die Datei gespeichert ist, oder andernfalls von einem anderen Programm verarbeitet, in dem die Datei angezeigt wird. Die Verarbeitungsanweisungen werden in memoQ normalerweise als nicht übersetzte Format-Tags angezeigt.
Dies empfiehlt sich allerdings nicht. So zeigen Sie Verarbeitungsanweisungen als Inline-Tags an: Aktivieren Sie das Kontrollkästchen Verarbeitungsanweisungen als Inline-Tags importieren. Sie werden dann in memoQ als mq:pi-Inline-Tags angezeigt.
-
Es können auch benutzerdefinierte Entitäten vorhanden sein (Einzelheiten folgen weiter unten auf dieser Seite). Diese stellen Zeichen dar, die im XML-Standard nicht definiert sind, aber in dem Content-Management-System oder dem Programm verwendet werden, in dem die Datei angezeigt wird.
Normalerweise werden sie in memoQ als Zeichen und nicht als Entitätscodes (&(Entitäten-Name);) angezeigt und exportiert.
So stellen Sie die Entitätscodes für diese Zeichen beim Exportieren der Übersetzung wieder her: Aktivieren Sie das Kontrollkästchen Benutzerdefinierte Entitäten bei Export wiederherstellen. Wenn benutzerdefinierte Entitäten wiederhergestellt werden, wird „©“ im Zieltext als „©right;“ exportiert.
-
XML-Dateien können verschiedene Probleme aufweisen, und in memoQ können beim Importieren von XML-Dateien mehrere Probleme auftreten. So rufen Sie ein Protokoll aller Warnungen ab: Aktivieren Sie das Kontrollkästchen Warnungen beim Import protokollieren. Die Probleme werden in einer Textdatei aufgelistet. Wenn Warnungen vorhanden sind, werden Sie in memoQ aufgefordert, die Protokolldatei in dem Ordner zu speichern, in dem sich auch das Ausgangsdokument befindet.
Beispiel für ein Protokoll mit Importproblemen:
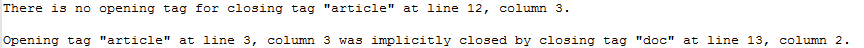
Normalerweise werden in memoQ der gesamte Text und alle anderen Inhalte aus XML-Dateien importiert. Wenn Sie steuern möchten, was als Text importiert wird, oder einige Inhalte von der Übersetzung ausschließen möchten, benötigen Sie die Optionen auf der Registerkarte "Tags und Attribute".
Sie können Optionen für jedes Tag und Attribut festlegen. Zuvor müssen jedoch in memoQ alle Tags und Attribute aus den importierten Dateien gelesen werden.
So rufen Sie die Tags und Attribute aus den Referenzdateien ab: Klicken Sie auf Ausfüllen.
Neubeginnen und Auswählen anderer Dateien für die Vorschau: Klicken Sie auf Liste bereinigen. Kehren Sie zur Registerkarte Codierung und Referenzdateien zurück. Wählen Sie andere Referenzdateien aus. Klicken Sie wieder auf die Registerkarte Tags und Attribute. Klicken Sie auf Ausfüllen.
Auf der Registerkarte Tags und Attribute sind mit „Tags“ Elemente gemeint – bestimmte Tags und der Inhalt zwischen ihnen. Wenn Sie z. B. eine Übersetzung für das „Tag“ Abstract einrichten, gehört sie zum Inhalt zwischen den Tags <Abstract> und </Abstract>.
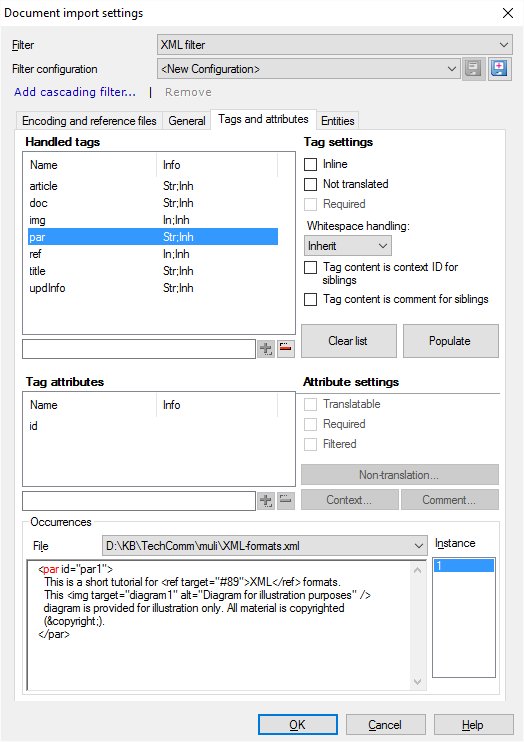
Während Sie die Tags und die zugehörigen Attribute einrichten, können Sie sie unten im Fenster Dokumentimport in der Vorschau anzeigen.
Unter Vorkommen sind die Stellen aufgeführt, an denen das ausgewählte Tag in einem der Referenzdokumente vorkommt. Tags werden rot hervorgehoben und Attribute grün.
- Datei: Wählen Sie in dieser Dropdown-Liste eine Referenzdatei zur Ansicht aus.
- Instanz: Klicken Sie auf eine Zahl, um ein Vorkommen des ausgewählten Tags in der ausgewählten Referenzdatei anzuzeigen.
Um auszuwählen, ob bestimmte Tags übersetzt werden oder ob mit ihnen ein neues Segment beginnt, verwenden Sie die Einstellungen im Abschnitt Tags:
- Tag-Handhabung: Diese Liste enthält alle Tags, die aus den XML-Dateien eingelesen wurden, sowie die Tags, die Sie hinzugefügt haben.
Einstellungen für die einzelnen Tags sind abgekürzt: In der Spalte Info der Liste Tag-Handhabung werden die Abkürzungen der Tag-Einstellungen angezeigt. Es handelt sich um folgende Abkürzungen: Str steht für ein strukturelles Tag (Segment wird geteilt), In für ein Inline-Tag (Segment wird nicht geteilt, wird als Inline-Tag importiert), NT für „Nicht übersetzt“ und Req für „Erforderlich“. Sie können auch die Leerraumzeichen-Handhabung festlegen: Inh bedeutet, dass das Tag die Leerraumeinstellungen vom übergeordneten Tag übernimmt (das Element, in dem es enthalten ist); Pres bedeutet, dass Leerräume beibehalten werden; und Norm bedeutet, dass Leerräume normieren werden. Kontext-Handhabung und Kommentaroptionen: Ctxt bedeutet, dass der Inhalt des Tags als Kontext-ID importiert wird. Com bedeutet, dass der Inhalt des Tags als Kommentar importiert wird. All diese Typen und Optionen werden nachfolgend erläutert.
Klicken Sie zum Festlegen dieser Optionen für ein Tag in der Liste Tag-Handhabung auf das entsprechende Tag. Treffen Sie dann mithilfe der Kontrollkästchen rechts Ihre Auswahl.
- Inline: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Tag als Inline-Tag zu verwenden. Bei Inline-Tags handelt es sich um Markup innerhalb von Segmenten. Sie werden als Inline-Tags angezeigt. In anderen Tools werden Inline-Tags möglicherweise als interne Tags bezeichnet. Wenn Sie dieses Kontrollkästchen nicht aktivieren, wird das Tag als strukturelles Tag behandelt. Strukturelle Tags sind Elemente, die Inhaltsblöcke für die Übersetzung darstellen. Strukturelle Tags werden nie innerhalb des Texts für die Übersetzung angezeigt: Mit ihnen beginnt immer ein neues Segment. In anderen Tools werden strukturelle Tags auch als externe Tags bezeichnet.
Im Beispiel: Geben Sie die ref- und img-Tags als Inline-Tags an, da sie innerhalb von Sätzen angezeigt werden. Alle anderen Tags sollten strukturelle Tags bleiben.
- Nicht übersetzt: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Tag von der Übersetzung auszuschließen. Diese Textteile werden nicht für die Übersetzung importiert.
Wenn ein Element nicht übersetzt wird, werden auch seine untergeordneten Elemente nicht übersetzt: Wenn Sie ein Element als nicht übersetzt festlegen, werden andere in ihm enthaltene Elemente auch nicht importiert. Legen Sie im Beispiel die Text- oder die Main-Elemente nicht als nicht übersetzt fest, da dann nichts importiert wird.
- Erforderlich: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Tag als erforderlich festzulegen. Bei erforderlichen Tags handelt es sich um spezielle Inline-Tags, die in die Übersetzung kopiert werden müssen. Wenn ein erforderliches Tag in der Übersetzung fehlt, wird im entsprechenden Segment ein Fehler angezeigt, und das Dokument kann nicht exportiert werden.
- Leerraumzeichen-Handhabung: Wählen Sie in dieser Dropdown-Liste aus, wie Leerräume in diesem Element behandelt werden. Erben bedeutet, dass Leerräume im Element auf die gleiche Weise behandelt werden wie im übergeordneten Element. Das Hauptelement erhält die auf der Registerkarte Allgemein angegebene Standardeinstellung. Erhalten bedeutet, dass alle Leerräume erhalten bleiben und in das zu übersetzende Dokument importiert werden. Normieren bedeutet, dass Folgen von Leerraumzeichen durch ein einzelnes Leerzeichen ersetzt werden.
- Tag-Inhalt ist Kontext-ID für Geschwisterelemente: Wenn Sie dieses Kontrollkästchen aktivieren, wird der Inhalt des ausgewählten Tags als Kontext-ID des nächsten Segments verwendet, das aus den Elementen auf derselben Ebene in der Hierarchie importiert wird.
Hinweis: Diese Kontext-ID wird nicht für alle Segmente übernommen, die aus derselben Hierarchieebene importiert werden. Stattdessen wird die Kontext-ID nur für das nächste geeignete Segment verwendet. Andere Geschwisterelemente bleiben ohne Kontext-ID.
- Tag-Inhalt ist Kommentar für Geschwisterelemente: Wenn Sie dieses Kontrollkästchen aktivieren, wird der Inhalt des ausgewählten Tags als Kommentar für die Segmente verwendet, die aus den Elementen auf derselben Ebene in der Hierarchie importiert werden.
Hinweis: Der Kommentar bzw. die Kontext-ID wird nur in einem Element verwendet, und zwar in dem Element, das sich nach dem Element befindet, das als Kontext oder Kommentar verwendet wird.
-
 : Klicken Sie auf diese Schaltfläche, um das ausgewählte Tag aus der Liste Tag-Handhabung zu entfernen.
: Klicken Sie auf diese Schaltfläche, um das ausgewählte Tag aus der Liste Tag-Handhabung zu entfernen. -
 : Klicken Sie auf diese Schaltfläche, um das im Textfeld eingegebene Tag in die Liste Tag-Handhabung aufzunehmen.
: Klicken Sie auf diese Schaltfläche, um das im Textfeld eingegebene Tag in die Liste Tag-Handhabung aufzunehmen. Wenn ein Tag in der Liste fehlt: Wenn eine XML-Datei in memoQ importiert wird, werden möglicherweise Tags gefunden, die in der Konfiguration nicht aufgeführt sind. Diese Tags werden als strukturelle und zu übersetzende Tags importiert. Sie erben die Leerraumeinstellungen vom jeweils übergeordneten Element. Der zugehörige Inhalt wird nicht als Kommentar oder Kontext-ID importiert.
Attribute von Tags können ebenfalls als Kontext-IDs oder Kommentare verwendet werden. Attribute können jedoch auch zu übersetzenden Text enthalten.
So wählen Sie aus, wie mit Attributen verfahren wird:
- Wählen Sie ein Tag in der Liste Tag-Handhabung aus. Unter Tag-Attribute werden die Attribute aufgelistet, die zum ausgewählten Tag gehören.
- Verwenden Sie die Kontrollkästchen rechts zum Ändern der Einstellungen für das ausgewählte Attribut.
Attributeinstellungen werden als Abkürzungen angezeigt: In der Spalte Info der Liste Tag-Attribute werden die folgenden Attribute angezeigt: ÜS steht für "Zu übersetzen", Req für "Erforderlich" und F für "Gefiltert". NX und NY geben Bedingungen zum Importieren oder Ignorieren des Tags an, dem das Attribut zugewiesen ist. CxC und CxS stehen für Kontext-ID-Optionen, und CmC und CmS sind Kommentaroptionen.
Unterschied beim Attribut "xml:lang": Sie können nicht kontrollieren, wie memoQ das Attribut xml:lang verarbeitet – es geschieht automatisch, basierend auf der Einstellung Attributwert xml:lang beim Export ändern. memoQ importiert das Attribut xml:lang von Inline-Tags nicht, es sei denn, jemand fügt es manuell hinzu. Sie können das Attribut xml:lang zwar zu Inline-Tags hinzufügen, jedoch können Sie keine Optionen angeben.
Folgende Optionen stehen zur Verfügung:
- Zu übersetzen: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Attribut als zu übersetzen festzulegen. Das heißt, dass der Wert des Attributs als normaler Text importiert wird.
- Erforderlich: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Attribut als Attribut festzulegen, das in jedem in die Übersetzung eingefügten Tag vorhanden sein muss. Ein erforderliches Attribut ist nicht unbedingt zu übersetzen: Es wird in memoQ zur Qualitätsprüfung verwendet und um die Wohlgeformtheit der Übersetzung sicherzustellen.
- Gefiltert: Aktivieren Sie dieses Kontrollkästchen, um das ausgewählte Attribut auszublenden, wenn Sie in die Ansicht Gefilterte Inline-Tags anzeigen im Übersetzungseditor wechseln.
- Kontext: Klicken Sie auf diese Schaltfläche, um den Wert des ausgewählten Attributs als Kontextinformationen für die untergeordneten oder die gleichgeordneten Elemente des ausgewählten Tags festzulegen. Nachdem Sie auf diese Schaltfläche geklickt haben, wird das Fenster Kontexteinstellungen für Attribute mit einer Liste der Optionen und entsprechenden Erläuterungen angezeigt:
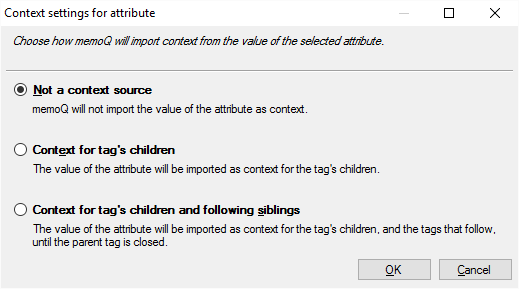
Im Beispiel: Das id-Attribut des par-Elements kann als Kontext-ID verwendet werden.
- Kommentar: Klicken Sie auf diese Schaltfläche, um den Wert des ausgewählten Attributs als Kommentar für die untergeordneten oder die gleichgeordneten Elemente des ausgewählten Tags festzulegen. Nachdem Sie auf diese Schaltfläche geklickt haben, wird das Fenster Kommentareinstellungen für Attribute mit einer Liste der Optionen und entsprechenden Erläuterungen angezeigt:
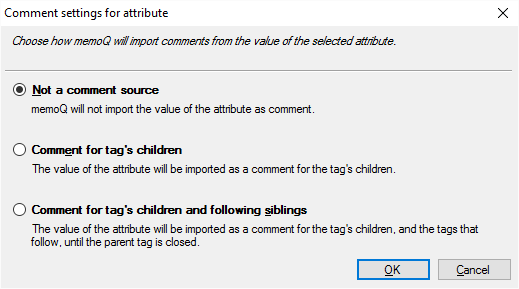
-
: Klicken Sie auf diese Schaltfläche, um das ausgewählte Attribut aus der Liste Tag-Attribute zu entfernen.
-
: Klicken Sie auf diese Schaltfläche, um das im Textfeld eingegebene Attribut in die Liste Tag-Attribute aufzunehmen.
Wenn ein Attribut fehlt: Wenn ein Attribut in der Konfiguration nicht aufgeführt ist, wird es als nicht zu übersetzen, nicht erforderlich und nicht gefiltert behandelt. Diese Attribute werden nicht für Nicht-Übersetzungsbedingungen oder in der Kontext- oder Kommentarverarbeitung verwendet.
Abhängig vom Wert eines Attributs können Sie ein Tag importieren oder ignorieren. Mit anderen Worten können Sie Bedingungen zum Importieren der Inhalte eines Tags (und aller zugehörigen untergeordneten Elemente) festlegen.
Ein Tag kann beispielsweise über das Attribut "translate" verfügen. Der Wert kann entweder translate="no" oder translate="yes" sein. Die Tags, für die translate="no"angegeben ist, sollen nicht importiert werden.
Gehen Sie dazu wie folgt vor:
- Klicken Sie auf die Registerkarte Allgemein. So rufen Sie bei Bedarf die Liste der Tags aus den Referenzdokumenten auf: Klicken Sie auf die Schaltfläche Ausfüllen.
- Wählen Sie ein Tag aus, das bedingt importiert werden soll.
- Wählen Sie in der Liste Tag-Attribute das Attribut aus, das als Bedingung verwendet werden soll.
- Klicken Sie rechts auf Nicht zu übersetzen …, um die Bedingung einzurichten.
Das Fenster Nicht-Übersetzungseinstellungen für Attribut wird angezeigt:
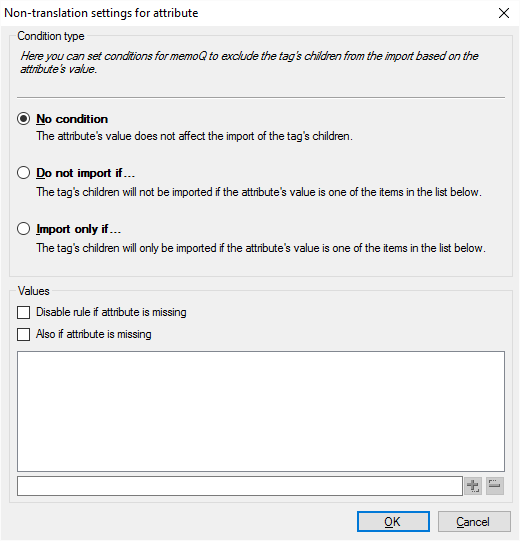
Listen Sie unter Werte die Werte auf, die Sie überprüfen möchten. Wenn das Tag einen der Werte hat, die Sie auflisten, importiert oder ignoriert memoQ den Tag-Inhalt, je nachdem, welche Bedingung Sie oben festgelegt haben.
- So listen Sie die Werte auf: Geben Sie im Textfeld unten einen Wert ein. Klicken Sie auf die Schaltfläche . Wenn Sie mehrere Werte testen möchten, wiederholen Sie diesen Vorgang.
Wenn Sie überprüfen möchten, ob das übersetzen-Attribut auf Nein festgelegt ist, geben Sie unten "no" ein und klicken dann auf
. - So wird das Tag ignoriert, wenn das Attribut einen der aufgelisteten Werte aufweist: Klicken Sie auf das Optionsfeld Kein Import, wenn. Im Beispiel klicken Sie auf dieses Optionsfeld, damit in memoQ die Tags weggelassen werden, für die translate="no" festgelegt ist.
- So wird das Tag importiert, wenn das Attribut einen der aufgelisteten Werte aufweist: Klicken Sie auf das Optionsfeld Import nur, wenn. Im Beispiel fügen Sie der Liste den Wert Ja hinzu (anstelle von Nein) und klicken auf dieses Optionsfeld. Dadurch werden in memoQ die Tags importiert, für die translate="yes" festgelegt ist.
Wenn das Attribut fehlt: Wenn Sie das Kontrollkästchen Regel deaktivieren, wenn Attribut fehlt aktivieren, wird in memoQ so verfahren, als hätten Sie Keine Bedingung ausgewählt. Wenn Sie das Kontrollkästchen Auch, wenn Attribut fehlt aktivieren, wird so verfahren, als hätte das Attribut einen leeren Wert.
XML-Dokumente enthalten Entitäten. Dabei handelt es sich um Zeichen, die nicht so wie sie sind in den Text eingefügt werden können, weil sie entweder in der XML-Syntax Sonderzeichen sind oder weil sie nicht mit der Codierung des Dokuments übereinstimmen.
Im XML-Text sehen Entitäten so aus: '&(Entitäten-Code);'.
Einige Standardgruppen von Entitäten werden im XML-Standard erkannt. Sie können eine oder mehrere davon auswählen.
Darüber hinaus können Sie spezifische benutzerdefinierte Entitäten für die importierten Dokumente einrichten.
Wenn Sie auf dieser Registerkarte die "Handhabung" einer Entität in memoQ angeben, bedeutet das, dass die Entität als normales Zeichen importiert wird. So wird sie dann auch im Übersetzungseditor angezeigt. Wenn die Übersetzung in memoQ exportiert wird, werden diese Zeichen wieder als Entitätscodes exportiert.
Verwenden Sie für diese Entitäten die Einstellungen auf der Registerkarte Entitäten:
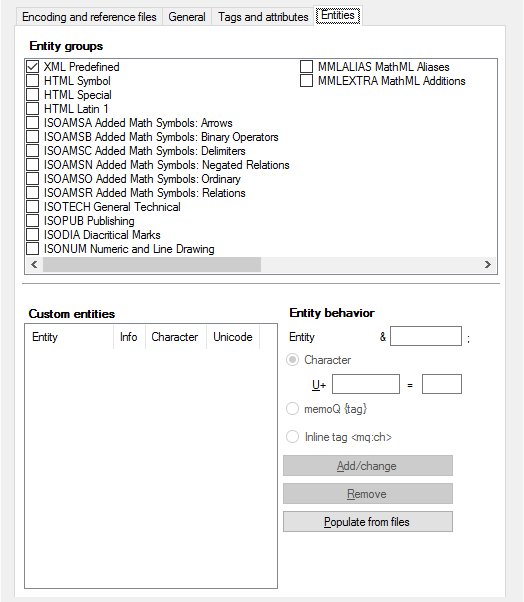
Sie können diese Einstellungen verwenden:
- Gruppe von Entitäten: In dieser Liste können Sie Standardgruppen von Entitäten auswählen, die während des Imports konvertiert werden sollen. XML Predefined-Entitäten (&, <, >, " und ') werden immer verarbeitet.
- Benutzerdefinierte Entitäten: In dieser Liste können Sie beliebige nicht standardmäßige Entitäten angeben, die für Ihren Dokumententyp spezifisch sind. Benutzerdefinierte Entitäten können im Übersetzungseditor wie Inline-Tags, memoQ-Format-Tags oder "normale" Unicode-Zeichen behandelt werden. Dies können Sie über die drei Optionsfelder unter Entitätsverhalten auswählen. Wenn Sie der Liste eine neue Entität hinzufügen möchten, geben Sie sie im Feld Entität ein. Zum Ändern der Einstellungen einer vorhandenen Entität wählen Sie die Entität in der Liste Benutzerdefinierte Entitäten aus. Im Beispieldokument ist die benutzerdefinierte Entität ©right; vorhanden, die für die Übersetzung in © konvertiert werden soll.
- Hinzufügen/ändern: Klicken Sie auf diese Schaltfläche, um der Liste Benutzerdefinierte Entitäten eine benutzerdefinierte Entität hinzuzufügen. Wenn Sie eine vorhandene benutzerdefinierte Entität ändern, werden damit die vorgenommenen Änderungen gespeichert.
Hinweis: Im ersten Feld neben der Liste Benutzerdefinierte Entitäten können Sie die im Dokument vorhandene Entität zwischen & und ; eingeben. Mithilfe der Optionsfelder können Sie auswählen, ob diese Entität als Zeichen oder als memoQ-Tag behandelt werden soll. Wenn die Entität im Übersetzungsfenster als Zeichen angezeigt werden soll, geben Sie den entsprechenden Unicode-Code im zweiten Feld ein, oder geben Sie das Zeichen im dritten Feld ein.
- Entfernen: Klicken Sie auf diese Schaltfläche, um die ausgewählte benutzerdefinierte Entität aus der Liste Benutzerdefinierte Entitäten zu entfernen.
- Von Datei(en) Liste erstellen: Klicken Sie auf diese Schaltfläche, um alle benutzerdefinierten Entitäten von den Referenzdateien zu extrahieren. Nach dem Klicken auf Von Datei(en) Liste erstellen werden alle benutzerdefinierten Entitäten in der Liste Benutzerdefinierte Entitäten angezeigt.
Abschließende Schritte
Gehen Sie folgendermaßen vor, um die Einstellungen zu bestätigen und zum Fenster Dokument-Importoptionen zurückzukehren: Klicken Sie auf OK.
Gehen Sie folgendermaßen vor, um zum Fenster Dokument-Importoptionen zurückzukehren und die Filtereinstellungen nicht zu ändern: Klicken Sie auf Abbrechen.
Im Fenster Dokument-Importoptionen: Klicken Sie erneut auf OK, um die Dokumente zu importieren.
Ergebnis für das Beispieldokument
Wenn einige Teile übersetzt wurden, müsste das Übersetzungsdokument so aussehen:

Anmerkungen zu diesem Screenshot:
- Der Text Aug-04-2006(NOT TO BE TRANSLATED) fehlt im Dokument, da das Attribut updInfo als nicht übersetzt festgelegt wurde.
-
Der Text Diagram for illustration purposes wird als separates Segment angezeigt, und mit alt="@2" im img-Tag in Segment 3 wird angegeben, dass der Wert des zu übersetzenden Attributs zwei Segmente weiter unten im Übersetzungsdokument zu finden ist.
Hinweis: Zu übersetzende Attribute werden während des Importvorgangs für das Dokument erfasst, gespeichert und an der Position in das Übersetzungsdokument eingefügt, an der der aktuelle Inhaltsblock endet – also beim nächsten strukturellen Tag.
- Das öffnende Tag ref wurde im Zielsegment 2 ohne das erforderliche Attribut „target“ eingefügt – daher zeigt memoQ eine Warnung an.
- Das Platzhalter-Tag img fehlt im Zielsegment 3 – daher zeigt memoQ eine Warnung an.
- In Segment 4 wurde die Entität '©right;' zu '©' konvertiert.