Statistiken
Die Statistiken in memoQ helfen Ihnen bei der Einschätzung des Arbeitsaufwands und der Rechnungsstellung, indem sie die Wortzahl, Segment-Treffer und Wiederholungen anhand Ihrer Translation Memories analysieren. In diesem Leitfaden wird erklärt, wie man Statistiken für verschiedene Projektrollen und Szenarien erstellt und interpretiert.
Im Fenster Statistiken können Sie überprüfen, wie viele Wörter, Segmente oder Zeichen in Ihrem Projekt oder den ausgewählten Dokumenten enthalten sind. memoQ vergleicht diese auch mit Ihren Translation Memories und LiveDocs-Korpora, um zu zeigen, wie viele Inhalte bereits übersetzt wurden oder wiederverwendet werden können.
-
Sie können dies automatisieren: In einem Projekt, das aus einer Projektvorlage erstellt wurde, kann memoQ automatisch einen Analysebericht erstellen.
-
Verwenden Sie das Fenster Statistiken, wenn Sie mehr Einstellungen benötigen: In der Übersicht eines lokalen Projekts oder im Fenster Berichte eines Online-Projekts können Sie schnell und mit weniger Einstellungen Analyseberichte für das gesamte Projekt erstellen.
-
Um herauszufinden, wie viel Arbeit nötig ist, basierend auf den Treffern in Ihren Translation Memories und LiveDocs-Korpora.
-
Zur Analyse von lokalen und Online-Projekten mit Benutzerdefinierten Einstellungen.
-
Zur Einschätzung Ihrer Rechnungsstellung basierend auf gewichteten Wortzahlen.
memoQ gruppiert Wörter nach Trefferkategorien (100%-Treffer, 95–99% usw.). Jede Kategorie hat eine Gewichtung, die angibt, wie viel Arbeit erforderlich ist (0% = keine Arbeit, 100% = vollständige Übersetzung).
Beispiel: Ein Segment mit 90% Übereinstimmung, 10 Wörtern und 50% Gewichtung zählt als 5 Wörter Arbeit.
Navigation
-
Oder erstellen Sie ein Projekt und importieren Sie Dokumente.
-
Öffnen Sie ein Dokument zur Übersetzung – wenn Sie einen Teil davon analysieren möchten.
-
Klicken Sie auf der Registerkarte Dokumente des Menübands auf Statistiken.
-
Das Fenster Statistiken wird angezeigt.
Sie können Online-Projekte nur verwalten, wenn Sie Mitglied der Gruppe Projekt-Manager oder Administratoren auf dem memoQ TMS sind oder wenn Ihnen die Rolle Projekt-Manager im Projekt zugewiesen wurde.
-
Öffnen Sie ein Online-Projekt zur Verwaltung.
Oder erstellen Sie ein Online-Projekt und importieren Sie Dokumente.
-
Klicken Sie im Fenster memoQ-Online-Projekt auf Übersetzungen.
-
Klicken Sie in der Registerkarte Vorbereitung des Menübands auf Statistiken.
Das Fenster Statistiken wird angezeigt.
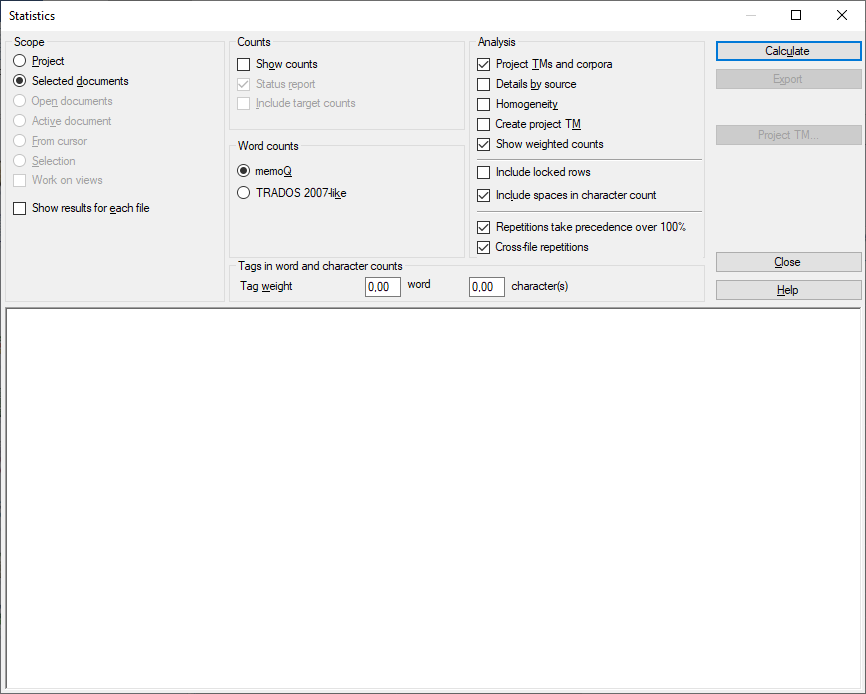
Möglichkeiten
Mit einem Bereich wird festgelegt, welche Dokumente memoQ einbeziehen soll.
-
Projekt: Alle Segmente in allen Dokumenten des aktuellen Projekts. Wenn das Projekt zwei oder mehr Zielsprachen aufweist, werden die Segmente in jeder Zielsprache überprüft.
-
Aktives Dokument: Alle Segmente im aktiven Dokument. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
-
Ausgewählte Dokumente: Alle Segmente in den ausgewählten Dokumenten. Diese Einstellung können Sie nur auswählen, wenn Sie mehrere Dokumente im Bereich Übersetzungen der Projektzentrale markieren.
-
Ab Cursorposition: Segmente unterhalb der aktuellen Position im aktiven Dokument. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
-
Geöffnete Dokumente: Alle Segmente in allen als Registerkarten des Übersetzungseditors geöffneten Dokumenten.
-
Auswahl: Ausgewählte Segmente im aktiven Dokument. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
-
An Ansichten arbeiten: Segmente in den Ansichten im aktuellen Projekt. Diese Option können Sie nur auswählen, wenn mindestens eine Ansicht im Projekt vorhanden ist.
Sie möchten Segmente in nur einer Zielsprache analysieren? Wählen Sie vor dem Öffnen des Fensters Statistiken eine Sprache im Bereich Übersetzungen aus. Wählen Sie alle Dokumente aus, öffnen Sie dann Statistiken und wählen Sie Ausgewählte Dokumente aus.
Diese Einstellungen gelten für ein lokales Projekt.
Wenn Sie selbst Statistiken ausführen, verwenden Sie diese Einstellungen im Fenster Analysebericht erstellen:
-
Verwenden Sie Projekt-TMs und Korpora, um Treffer zu finden. memoQ überprüft die Segmente in jedem Translation Memory und LiveDocs-Korpus in Ihrem Projekt.
-
Verwenden Sie Homogenität, um wiederholte Segmente korrekt zu zählen. memoQ berechnet voraus, welche Treffer Sie aus dem Translation Memory erhalten werden, das sich während der Übersetzung füllt. Diese Option ist nur sinnvoll, wenn Sie allein an der Übersetzung arbeiten.
-
Deaktivieren Sie Gesperrte Zeilen einschließen, wenn es welche gibt (das sind Segmente, die Sie nicht übersetzen sollten).
-
Wählen Sie Wiederholungen haben Vorrang vor 100% Treffern, damit wiederholte Segmente nicht doppelt gezählt werden. Verwenden Sie diese Option nur, wenn eine konsistente Übersetzung wichtiger ist als die Verwendung aller möglichen Treffer aus dem Translation Memory.
-
Verwenden Sie Dateiübergreifende Wiederholungen, wenn Ihr Projekt mehrere Dokumente enthält, damit Wiederholungen in verschiedenen Dateien erkannt werden.
-
Wählen Sie Gewichtete Anzahl anzeigen, um die tatsächliche Aufwandsschätzung zu sehen.
Verwalten Sie ein Online-Projekt?
Wenn Sie den Befehl Statistiken für ein Online-Projekt ausführen, verwendet memoQ die Gewichtungen des memoQ TMS.
Das Einrichten der Gewichtungen auf einem memoQ TMS erfolgt über den Server-Administrator. Wählen Sie Gewichtete Anzahl und prüfen Sie die Gewichtungen oder legen Sie sie fest.
Diese Einstellungen gelten für ein Online-Projekt. Sie können sie auch in einem lokalen Projekt anwenden, wenn Sie Projekt-Manager sind und das Projekt auf einem Server veröffentlichen oder mit Paketen verteilen möchten.
Wenn mehrere Übersetzer an dem Projekt arbeiten sollen, verwenden Sie diese Einstellungen im Fenster Analysebericht erstellen:
-
Verwenden Sie Projekt-TMs und Korpora, um Treffer zu finden. memoQ überprüft die Segmente in jedem Translation Memory und LiveDocs-Korpus im Projekt.
-
Berechnen Sie nicht die Homogeneity. Sie können keine internen Fuzzy-Treffer vorhersagen, weil Sie nicht wissen, wer ein Segment zuerst übersetzt.
-
Wählen Sie nicht Gesperrte Zeilen einschließen, es sei denn, die Übersetzer arbeiten an gesperrten Inhalten.
-
Wählen Sie Wiederholungen haben Vorrang vor 100% Treffern, damit wiederholte Segmente nicht doppelt gezählt werden. Verwenden Sie diese Option nur, wenn eine konsistente Übersetzung wichtiger ist als die Verwendung aller möglichen Treffer aus dem Translation Memory.
-
Deaktivieren Sie Dateiübergreifende Wiederholungen, da nicht bekannt ist, wer zuerst ein Segment übersetzen wird, und der entsprechende Benutzer für die Übersetzung eine volle Vergütung erhalten soll.
-
Wählen Sie Gewichtete Anzahl anzeigen, um realistische Einschätzungen des Arbeitsaufwands zu erhalten.
Um herauszufinden, wie viel Arbeit ein Team von Übersetzern geleistet hat, verwenden Sie die Nach-Übersetzungsanalyse, nachdem die Übersetzung abgeschlossen ist.
Wenn Sie den Befehl Statistiken für ein Online-Projekt ausführen, verwendet memoQ die Gewichtungen vom memoQ TMS.
Das Einrichten der Gewichtungen auf einem memoQ TMS erfolgt über den Server-Administrator. Wählen Sie Gewichtete Anzahl und prüfen Sie die Gewichtungen oder legen Sie sie fest.
So erhalten Sie eine einfache Zählung des gesamten Textumfangs ohne Trefferanalyse:
-
Deaktivieren Sie die Kontrollkästchen Projekt-TMs und Korpora, Homogenität und Dateiübergreifende Wiederholungen.
-
Wählen Sie Gesperrte Zeilen einschließen und Wiederholungen haben Vorrang vor 100% Treffern aus.
Überprüfer (Korrekturleser) arbeiten an bereits übersetzten Inhalten, unabhängig von Treffern, weshalb es keinen Sinn macht, die Arbeit anhand von Translation Memories zu analysieren.
-
Deaktivieren Sie die Kontrollkästchen Projekt-TMs und Korpora, Homogenität und Dateiübergreifende Wiederholungen.
-
Aktivieren Sie Wiederholungen haben Vorrang vor 100% Treffern, und wenn der Überprüfer gesperrte Inhalte überprüft, aktivieren Sie Gesperrte Zeilen einschließen.
Auf einigen Märkten wird das Übersetzungsvolumen nach Zeichen statt nach Wörtern gemessen. memoQ zeigt neben der Anzahl der Wörter auch immer die Anzahl der Zeichen an.
Um Leerzeichen zu zählen, stellen Sie sicher, dass Leerzeichen in Zeichenzählung einschließen ausgewählt ist. memoQ zählt jedes Leerzeichen separat, z. B. zwei Leerzeichen direkt hintereinander zählen als zwei, nicht als eines.
Formate wie XML, HTML, PDF, InDesign oder Microsoft Word enthalten oft viele Inline-Tags, die die Bearbeitung komplizierter machen. Dies muss sich im Analysebericht widerspiegeln.
Sie können den Tags Gewichtungen zuweisen:
-
Tag-Gewichtung in Wörtern oder Zeichen festlegen
Geben Sie unter Tag-Gewichtung eine Zahl in das Feld Wort/Wörter oder Zeichen ein (z. B. 0,25 Wörter pro Tag oder 2 Zeichen pro Tag).
Wenn Sie 0.25 eingeben, zählt memoQ nach jeweils vier Inline-Tags ein Wort, oder, wenn Sie 2 eintippen, zählt memoQ nach jedem Tag zwei Zeichen.
-
memoQ addiert dann diese gewichteten Zählungen zu Ihrer Gesamteinschätzung des Arbeitsaufwands.
Im Fenster Statistiken gibt es mehrere Optionen, über die memoQ die im Bericht zu berücksichtigenden Details festlegen kann.
-
Ergebnisse für jede Datei anzeigen erstellt für jedes Dokument einen eigenen Bericht.
-
Wortzahl anzeigen zeigt die Gesamtzahl der Segmente, Wörter und Zeichen an.
-
Statusbericht zeigt den Status der Segmente an (bestätigt, bearbeitet, vorübersetzt, nicht begonnen).
-
Wortzahl des Zieltextes einschließen ist erforderlich, wenn Sie nach der Zieltextgröße abrechnen.
Nachdem Sie Ihre Optionen eingestellt haben, klicken Sie auf Ermitteln. Der Vorgang kann je nach Projektgröße einige Minuten dauern.
Wenn die Analyse abgeschlossen ist, zeigt memoQ dies am unteren Rand des Fensters Statistiken an:
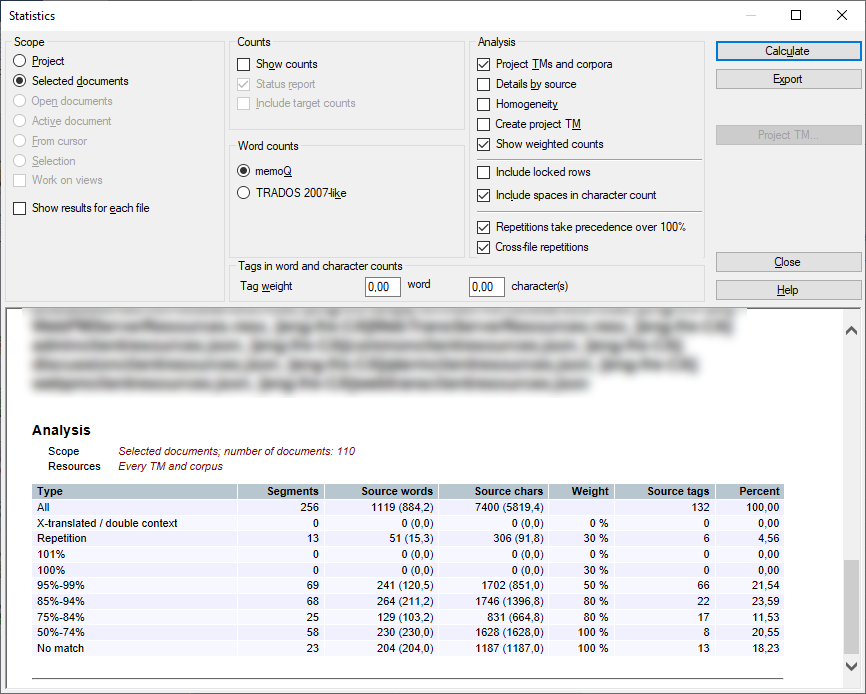
Sie können ihn hier einsehen oder Berichte in verschiedenen Formaten exportieren.
So exportieren und speichern Sie den Analysebericht:
-
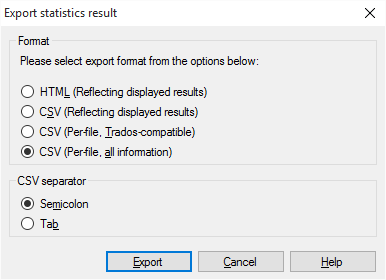
Klicken Sie auf Exportieren. Das Fenster Statistikergebnisse exportieren wird angezeigt.
-
Wählen Sie eines der folgenden Formate aus:
- HTML (Ergebnisse, wie angezeigt): Speichert die angezeigten Statistiken als HTML-Datei
- CSV (Ergebnisse, wie angezeigt): Speichert die Ergebnisse in einer CSV-Datei (die in Excel geöffnet werden kann)
- CSV (pro Datei, TRADOS-kompatibel): Speichert die Ergebnisse in einer CSV-Datei, wobei die Details zu jedem Dokument genau eine Zeile einnehmen. Dies ist der alte Trados-Stil.
- CSV (pro Datei, alle Informationen): Speichert die Ergebnisse in einer CSV-Datei, wobei das Layout der Ergebnisse genau dem im Fenster Statistiken entspricht
-
Wenn Sie eines der CSV-Formate auswählen, können Sie das Trennzeichen auswählen, mit dem die Spalten in der Tabelle getrennt werden. Es gibt keinen Grund, ein anderes als das Tabulatorzeichen zu verwenden: Klicken Sie unter CSV-Trennzeichen auf Tab.
-
Klicken Sie auf Exportieren. Das Fenster Speichern unter wird angezeigt. Geben Sie einen Speicherort und einen Namen für die Berichtsdatei an und klicken Sie auf Speichern. Der Bericht wird exportiert und Sie kehren zum Fenster Statistiken zurück.
memoQ kann alle Segmente aus den Translation Memories und den LiveDocs-Korpora, die während der Analyse gefunden wurden, in einem speziellen Projekt-TM sammeln, um die Wiederverwendung zu erleichtern.
Gehen Sie dazu wie folgt vor:
-
Aktivieren Sie vor Ausführen der Analyse das Kontrollkästchen Projekt-TM erstellen.
-
Führen Sie die Analyse aus: Klicken Sie auf Ermitteln.
-
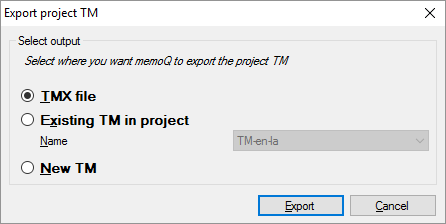
Speichern Sie das Translation Memory: Klicken Sie auf Projekt-TM. Das Fenster Projekt-TM exportieren wird angezeigt:
-
Wählen Sie, wo memoQ die Segmente ablegen soll:
- Sie können sie in einer TMX-Datei speichern, sodass sie auf einem anderen Computer und in ein anderes Übersetzungstool importiert werden können.
- Sie können sie in einem Translation Memory speichern, das bereits Teil Ihres Projekts ist. Wählen Sie in der Dropdown-Liste Name das Translation Memory aus.
- Oder Sie können ein neues Translation Memory im Projekt erstellen und die Segmente dort speichern.
-
Klicken Sie auf Exportieren. memoQ speichert die Segmente.
Die Ergebnisse sind in zwei Hauptabschnitte unterteilt:
-
Wortzahl – zeigt die Gesamtzahl der Segmente, Wörter und Zeichen an.
-
Analyse – detaillierte Aufschlüsselung nach Treffertyp und Ressource (TMs, Homogenität usw.).
Sie können mehr als einen Analyse-Abschnitt haben. Es hängt von der Anzahl der Translation Memories im Projekt und den Einstellungen für die Kontrollkästchen Ergebnisse für jede Datei anzeigen und Details pro Quelle ab.
Bereich – zeigt den Umfang der im Abschnitt Bereich auswählen ausgewählten Analyse an.
Ressourcen – die Mittel, auf deren Grundlage die Ergebnisse gewonnen wurden. Hier finden Sie den Namen eines Translation Memory oder Homogenität für Homogenitätsprüfungen. Wenn es sich um aggregierte Ergebnisse handelt, wird die Beschriftung Jedes TM und Korpus bzw. Jedes TM und Korpus, Homogenität angezeigt.
Sie sehen Zeilen für folgende Optionen:
-
Alle – gesamter Umfang (alle Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern).
-
Dokumentenbasiert vorübersetzt – übersetzte Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern.
-
Wiederholung – wiederholte Segmente (alle Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern).
-
Bereiche nach Prozentsatz abgleichen (z. B. 95–99%).
-
Anzahl der Segmente, Anzahl der Wörter und Zeichen in Ausgangs- und Zieltext.
Analyse für ausgewählten Bereich. Wenn ein Projekt beispielsweise zwei Dokumente enthält, in denen das gleiche Segments jeweils genau einmal vorkommt, wird in der für den Projektbereich ermittelten Statistik ein Segment als Wiederholung angezeigt. Wenn Sie die Statistik für die zwei Dokumente separat ermitteln, werden keine Wiederholungen angezeigt.
Wenn Sie ein großes Projekt auf verschiedene Übersetzer aufteilen möchten, kann dieser Unterschied erheblich sein, da die Gesamtstatistik für das gesamte Projekt unter Umständen eine deutlich höhere Anzahl an Wiederholungen enthält als die Statistiken für die verschiedenen Mengen von Dokumenten zusammen.
-
Nicht begonnen: Anzahl der unberührten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Vorübersetzt: Anzahl der vorübersetzten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Fragmente: Anzahl der Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis, einschließlich aus Fragmenten zusammengefügten Treffern.
-
Bearbeitet: Anzahl der bearbeiteten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Durch Übersetzer bestätigt: Anzahl der bestätigten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Durch Überprüfer 1 bestätigt: Anzahl der durch Überprüfer 1 bestätigten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Durch Überprüfer 2 bestätigt (Korrektur gelesen): Anzahl der durch Überprüfer 2 bestätigten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Gesperrt: Anzahl der gesperrten Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
-
Prozentbereiche: Diese Zeilen zeigen die Anzahl der Ausgangssegmente, Ausgangswörter und -zeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis für Segmente mit einem Treffer aus derselben Kategorie.
Wenn hinter 75–84% die Angabe 5 steht, als Ressource Jedes TM und Korpus und als Bereich Projekt angegeben ist, bedeutet dies, dass Sie bei Kombination aller Translation Memories für fünf Segmente einen 75–84%-Treffer erhalten.
Spalten im Analysebericht:
Jede Zeile (jeder Typ) hat einen Wert in diesen Zeilen:
-
Segmente: Anzahl der Ausgangssegmente dieses Typs innerhalb des ausgewählten Bereichs.
-
Ausgangswörter: Anzahl der Ausgangswörter dieses Typs innerhalb des ausgewählten Bereichs. Wenn die Tag-Gewichtung ungleich 0 ist, ist diese Anzahl unter Umständen größer als die eigentliche Wortzahl.
-
Ausgangszeichen: Anzahl der Ausgangstextzeichen dieses Typs innerhalb des ausgewählten Bereichs. Die Zeichenanzahl umfasst Leerzeichen, aber keine nicht übersetzten Format-Tags. Wenn die Tag-Gewichtung ungleich 0 ist, ist diese Anzahl unter Umständen größer als die eigentliche Zeichenanzahl.
-
Ausgangstext-Tags: Anzahl der Tags im ausgewählten Bereich, die in den Segmenten der Spalte Typ enthalten sind
-
Prozent: Prozentsatz der Quellwörter in dieser Kategorie in Bezug auf die Gesamtwortzahl im ausgewählten Bereich Die Summe aller Prozentangaben ergibt aufgrund der Rundung möglicherweise nicht genau 100 %.
-
Zieltextwörter: Anzahl der Zielwörter dieses Typs innerhalb des ausgewählten Bereichs. Diese Spalte wird nur angezeigt, wenn das Kontrollkästchen Wortzahl des Zieltextes einschließen aktiviert ist.
-
Zielzeichen: Anzahl der Zieltextzeichen dieses Typs innerhalb des ausgewählten Bereichs. Diese Spalte wird nur angezeigt, wenn das Kontrollkästchen Wortzahl des Zieltextes einschließen aktiviert ist.
Wenn Sie Statistiken für alle Zielsprachen des Projekts ausführen, erhalten Sie zusätzliche Details:
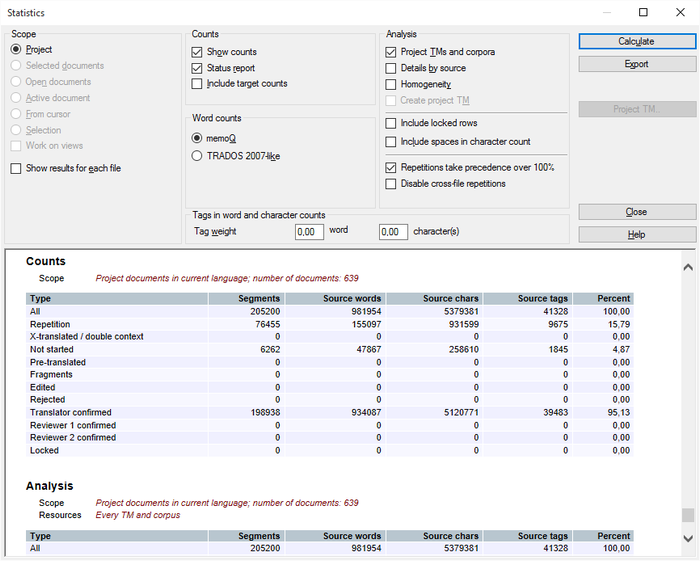
Wenn Sie die Analyse exportieren, fügt memoQ nun für jedes zielsprachliche Dokument für die Optionen HTML und CSV (Ergebnisse, wie angezeigt) eine separate Zeile hinzu. Wenn Sie die Analyse als CSV (pro Datei, TRADOS-kompatibel) oder als CSV (pro Datei, alle Informationen) exportieren, wird in der CSV-Datei für jede Zielsprache ein Präfix hinzugefügt, z. B. [ger] Beispiel.txt:
Für Ausgangssprachen wie Japanisch oder Chinesisch (keine Leerzeichen zwischen den Wörtern) fügt memoQ die Spalten Nicht-asiatische Ausgangstextwörter und Asiatische Ausgangstextzeichen zu den Statistikergebnissen hinzu.
memoQ zeigt:
-
Anzahl Nicht-asiatische Ausgangstextwörter anstatt Wortzahl.
-
Die kombinierte Ausgangswörter-Spalte enthält asiatische Zeichen und alle nicht-asiatischen Wörter.
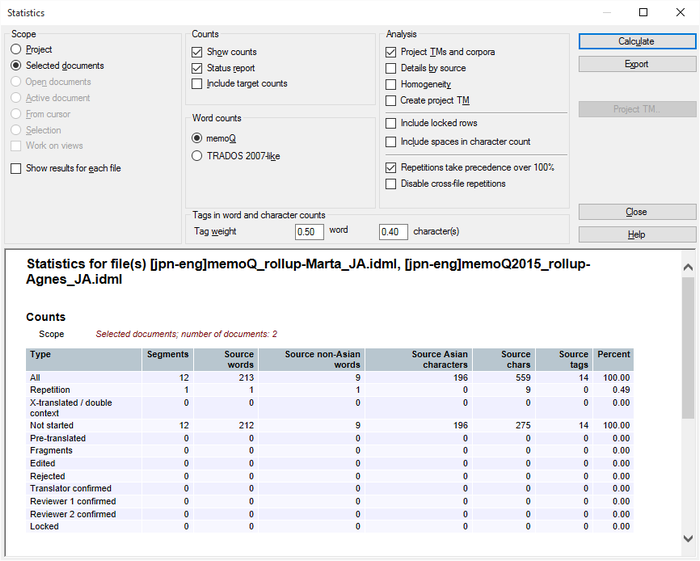
Koreanisch verwendet Leerzeichen, weshalb die Wortzählung ähnlich wie in europäischen Sprachen funktioniert.