PO Gettext files
PO files are localization files, mostly used for writing multilingual programs on Unix computers. PO Gettext files are bilingual and can contain a single source and target language.
memoQ can directly work with PO Gettext files. The exported file is bilingual.
How to get here
-
In the Document import options window, select the PO Gettext files, and click Change filter and configuration.
-
The Document import settings window appears. From the Filter drop-down list, choose PO Gettext filter.
What can you do?
-
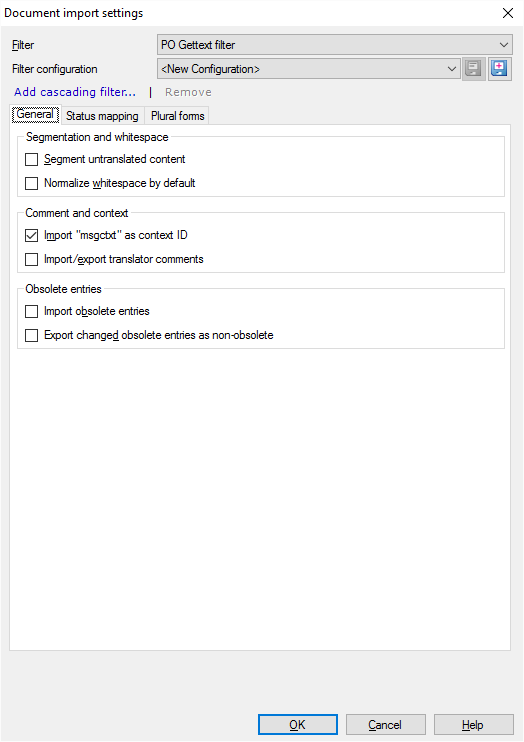
Normally, memoQ doesn't split the untranslated text into segments. A PO file is made up from entries. Each entry becomes exactly one segment, no matter how many sentences it contains. To split the entries into segments: Under Segmentation and whitespace, select the Segment untranslated content checkbox.
-
Normally, memoQ does not change the space (breaking and non-breaking), tab, and newline characters when it imports PO Gettext files. But memoQ can normalize them: It can convert sequences of tab, space, non-breaking space, and newline characters into a single space character. When it normalizes white space, memoQ also deletes any white space at the beginning and the end of entries. To normalize spaces: Select the Normalize whitespace by default checkbox.
Example:
Before normalization:
This is a
test, with a lot of spaces.
After normalization:
This is a test, with a lot of spaces.
-
In a PO Gettext file, each entry has an attribute called 'msgctxt'. Normally, memoQ imports this attribute as the context of the segment. If you don't need the context, clear the Import msgctxt as context ID checkbox.
-
Normally, memoQ doesn't import comments from PO Gettext files. To import comments: Select the Import/export translator comments checkbox.
If comments aren't imported, they aren't exported, either: If you don't choose to import comments from the PO Gettext file, memoQ won't export comments that translators make. If you want the translators' or reviewers' comments to appear in the exported files, select this checkbox, even when there are no comments in the source files.
-
In PO Gettext files, obsolete entries are those that don't appear in the program being localized, or those that shouldn't be translated. Normally, memoQ doesn't import these.
- To import obsolete entries: Select the Import obsolete entries checkbox.
- Normally, if you import obsolete entries, their translations go back as obsolete. But you can make them active again. To do that, select the Export changed obsolete entries as non-obsolete checkbox.
The structure of an entry of a PO file is as follows:
white-space
# translator-comments
#. extracted-comments
#: reference...
#, flag...
#| msgid previous-untranslated-string
msgid untranslated-string
msgstr translated-string
-
The msgid untranslated-string is imported as source, and the msgstr translated-string is imported as target. The msgid and msgstr fields contain the source and target string of a translation unit. The msgid elements are unique within a PO domain.
For example:
.
msgid " "
"memoQ Zrt. is "
" "
"%s. \n"
"What is"
" "
"the company about?"
is the same as:
msgid "memoQ Zrt. is %s. \n What is the company about?" - The msgctxt element is imported as context ID. The #| msgid element is marked as obsolete.
- The #, flag element is retained. Flags are used to indicate the status of a translation unit (e.g. finished or fuzzy). A fuzzy flag can be mapped to a memoQ segment status (on the Status mapping tab). Multiple flags are separated by commas.
- The # translator-comments can be imported and exported as memoQ comments, if you choose to do that when importing the file. These comments are added by translators and are not present in PO files. Comments are inserted before the extracted-comments and the reference comments.
- The #. extracted-comments and #: reference comments fields are retained in the structure. These are not modified by memoQ. The Extracted comments elements are extracted from the source code if they are in the same line as the source string or in the preceding line. The Reference comments elements are space separated lists of locations, specifying where the translation unit is found in a source file. A single translation unit can contain multiple references (one for each location).
- Obsolete entries are entries that are commented out when a PO file is updated. For example, text that is not for translation becomes obsolete. Usually, the msgmerge element is used to comment out entries (make them obsolete). Obsolete entries are marked with #~.
You can find a comprehensive specification of this file format here or here.
Entries in a PO Gettext file have two status values: fuzzy and non-fuzzy. To import these into memoQ, or export them back to the PO Gettext files, click the Status mapping tab.
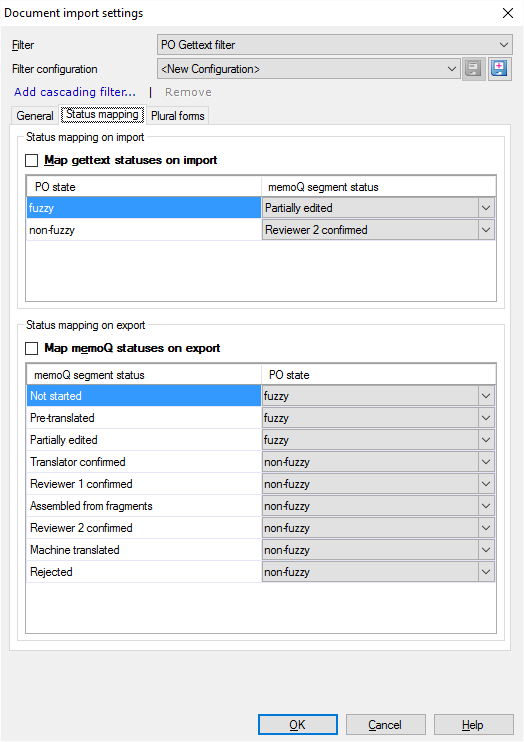
- Normally, memoQ does not import the Gettext statuses when it imports a file. To do that, select the Map gettext statuses on import checkbox.
- Again, at first memoQ does not export the memoQ statuses when it exports a PO Gettext file. To do that, select the Map memoQ statuses on export checkbox.
When memoQ imports a PO Gettext file, it makes sense of the status it reads from the file.
- Normally, 'fuzzy' entries are imported as Partially edited (Edited). To change that, choose a different status from the drop-down box next to 'fuzzy'.
- Normally, 'non-fuzzy' entries are imported as Reviewer 2 confirmed. To change that, choose a different status from the drop-down box next to 'non-fuzzy'.
When memoQ exports a PO Gettext file, the status of each segment is exported either as 'fuzzy' or 'non-fuzzy'.
Normally, Not started, Pre-translated, and Partially edited (Edited) segments are exported as 'fuzzy'. Everything else is exported as 'non-fuzzy'. To change that, choose a different status from one or more of the drop-down boxes in the list at the bottom.
If an entry contains numeric placeholders, the PO Gettext files can contain variants for the text - if the plural forms are different in the source or the target language.
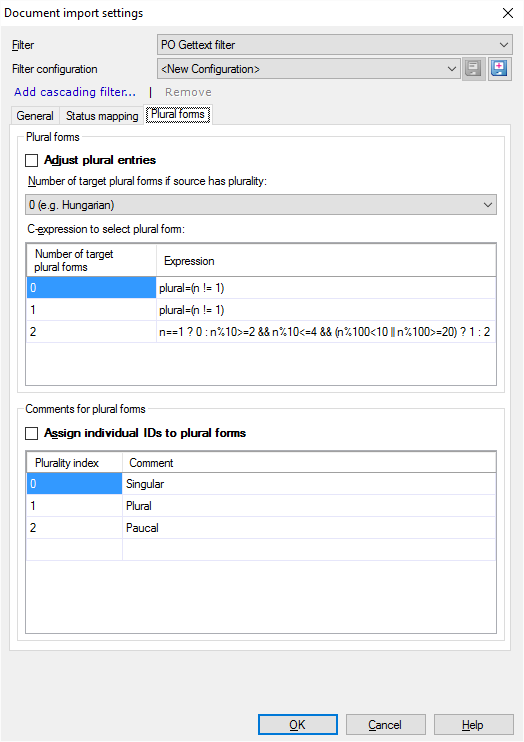
You can set this up on the Plural forms tab. To allow the variants: Select the Adjust plural entries checkbox.
In the actual entries, the singular and plural variants look like this:
#: src/msgcmp.c:338 src/po-lex.c:699
#, c-format
msgid "found %d fatal error"
msgid_plural "found %d fatal errors"
msgstr[0] "s'ha trobat %d error fatal"
msgstr[1] "s'han trobat %d errors fatals"
Choose how many plural forms the source language has. In the Number of target plural forms if source has plurality drop-down list, you can choose 0 (E.g. Hungarian), 1 (E.g. Latin languages), or 2 (E.g. Slavic languages).
The expression next to each form tells when to use which plural form. You can set this using C-expressions. C-expressions are conditional formulae the follow the syntax of the C programming language (not detailed here).
Each plurality type can have a name. To use these names: Select the Assign individual IDs to plural forms checkbox. The names you see in the screenshot are there automatically. Click each name to change it.
When the Assign individual IDs to plural forms checkbox is selected, this information is appended to the msgctxt (context) attribute. If you don't do this, and there are two target plural forms, the source and the context ID may be the same for both. In this case, the context would not provide enough information to store them in the translation memory as two different units - unless the plurality information is there.
When you finish
-
To confirm the settings, and return to the Document import options window: Click OK.
In the Document import options window: Click OK again to start importing the documents.
-
To return to the Document import options window, and not change the filter settings: Click Cancel.
-
If this is a cascading filter, you can change the settings of another filter in the chain: Click the name of the filter at the top of the window.
It is possible to cascade filters after the bilingual and multilingual filters. For example, Multilingual Excel and delimited text can be the first filter in a filter chain, but remember that regex tagger should always be the last filter applied.