Regular expressions
Regular expressions are a powerful means for finding character sequences in text. In memoQ, they are used to define segmentation rules, auto-translation rules, or rules for the Regex tagger. You can also use regular expressions in Find and replace, and in the Filter fields in the translation editor.
Finding character sequences is a familiar task to everyone who has used a word processor or text editor before. The Find or Search dialog serves this purpose – if you search for 'cat', your editor will highlight words (or parts of words) such as 'cat', 'cats', or even 'sophisticated'.
Regular expressions, however, provide a lot more freedom to tell the computer what you are looking for. You can identify sequences such as a letter 'a', followed by two or three letters 'c'; a number of letters followed by one or more digits; either of the words 'cat', 'dog' or 'mouse'; or even the occurrences of a word where it is between quotation marks – and much more. After reading through this page and experimenting with the examples, you'll know exactly how. If you do not feel ready to learn the details, the Regex Assistant will help you.
Note: The term regular expression comes from the mathematical theory on which this pattern matching method is based. It is often abbreviated as regexp or regex – here we'll use regex, or in the plural, regexes.
Regex syntax has many variants (flavors): memoQ uses the .NET regex engine, and thus the .NET flavor. This article only describes a part of the .NET regex syntax – for the detailed documentation, see the related part of the Microsoft Learn website.
Standard .NET regex features
In a word processor's old-school Find function every character is interpreted literally. If you search for 'Yes? No...' it will highlight 'Yes? No...' – or nothing if these characters do not appear in the text. In a regex, however, some characters have special meaning – these are called meta characters. The most important meta characters are:
Confusing? This table is only meant as a short summary and reference – the meaning of all of these expressions will be clarified in the sections below.
For now, let's focus on the first one, the dot. In a regex it means 'any character may stand here'. So the expression No... in a regex matches any of the following:
- Notes
- Notte
- No...
- No&%X
So what do you need to write in a regex to match precisely 'No...' and no other text? To match a character that has a special meaning, you must 'escape' it: that is, add a backslash before it. Thus, No\.\.\. matches exactly 'No...' and nothing else.
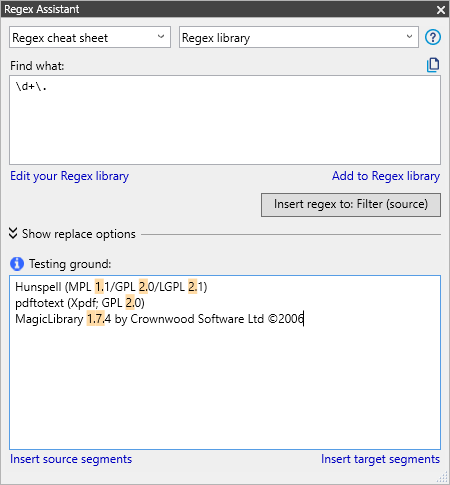
The Regex Assistant has a testing ground for exactly that. Copy and paste some text into the Testing ground text box, then type your regular expression in the Find what box. memoQ highlights the text parts that match the regex:
Now that we've covered the dot and know how to experiment with new regexes, let's move on to some more serious expressions. Brackets in regexes allow you to specify a set of characters – a character class. [ab][01] matches two-character-long sequences where the first character is either an 'a' or a 'b', and the second is either a '0' or a '1'. This yields 4 possible matches: 'a0', 'b0', 'a1', 'b1'.
Character classes can be used to express things like 'a digit followed by a comma or an exclamation mark' – which could be expressed as [0123456789][,!]. This, however, would be a very inconvenient thing to write. Regexes know better: you can specify a range of characters by writing [0-9][,!, which means exactly the same as the previous regex.
Can you use a character class to match an alphabetical letter? Yes and no: The regex [a-z] matches any of the letters between a and z – the letters in the English alphabet. But memoQ works with many languages that have special characters in their alphabet. For example, the Icelandic letter 'đ' is not in the range 'a-z'. But there are easy ways to deal with such characters - see the part about shorthands below.
Also, keep in mind that all letters in memoQ regexes are interpreted in a case-sensitive way. Thus, [a-z] matches 'f' but not 'F'.
You can also use character classes to specify what not to match. The regex [^0a]. matches any two-character sequence where the first character is not '0' or 'a'.
As you saw earlier, you need to escape the special meta characters (add a backslash before them) to use them as normal characters: to match an actual '+' sign, you need to use the \+ characters in your regex. There are also other practical escape sequences available, for example \t matches a tab character, and \n matches a line break. And many escape sequences are shorthands for character classes:
|
Sequence |
Description |
|---|---|
|
\s |
Whitespace: space, tab or newline |
|
\S |
Anything but a whitespace |
|
\d |
Digit |
|
\D |
Anything but a digit |
|
\w |
Alphanumeric character and underscore |
|
\W |
Anything but an alphanumeric character |
These shorthands are a bit different than the basic character classes in the previous section: \d matches all Unicode decimal digits (from many writing systems), not only [0-9], and \w matches all Unicode letters (lowercase and uppercase), numbers, and the underscore ('_'), not only [a-z].
Now that you've learned how to match characters at a given position, it's time tell memoQ how many characters to match. The special characters '*', '+', and '?', and the expression '{num}' are used for this purpose.
|
Expression |
Description |
|---|---|
|
* |
Character to the left of the asterisk in the expression should match 0 or more times. For example, |
|
+ |
Character to the left of the plus sign in the expression should match 1 or more times. For example, |
|
? |
Character to the left of the question mark in the expression should match 0 or 1 time. For example, |
|
{num} |
Character to the left of the enclosed number should match num times. For example, |
-
The regex
x+matches a sequence of one or more 'x's – thus, 'x', 'xx', 'xxx' and so on. -
The regex
x{3}matches a sequence of exactly 3 'x's – thus, 'xxx', but not 'x' or 'xx'. If the text is 'xxxx', the regex matches the first 3 'x's and ignore the fourth: 'xxxx'. Just like the traditional Find dialog will find the word 'cat' in 'cats'. -
You can also use the '{num}' quantifier to specify a minimum (and if needed, a maximum) value. Thus,
x{3,5}matches between 3 and 5 'x's;x{3,}matches at least 3 'x's.x{,5}will not work this way: To match at most 5 'x's, usex{0,5}. -
The regex
x*ymatches an 'y' preceded by any number of 'x's (even zero) - thus, 'y', 'xy', 'xxy' and so on, but not 'zy'. -
The regex
zx?ymatches a 'z' followed by zero or one 'x's and a 'y' - thus, 'zy' and 'zxy', but not 'zxxy'.
For even more powerful use, combine character sets or shorthands with quantifiers: [0-9]+% or \d+% matches one or more of digits followed by a percentage sign; for example, '1%' or '99%', but not '10a%'.
Use the pipe ('|') symbol to join several smaller regexes to say 'match either this, that or the other thing'. The regex EUR|USD|GBP matches any of these words, and only these.
When working with alternatives, you often need to group them together using parentheses to get the results you want. For example, you need a regex that matches any of these expressions: 'EUR 15 million', 'USD 37 million' and 'GBP 5 million'. As a first try, you might be inclined to write EUR|USD|GBP \d+ million. This, however, will not do, as it only matches the following strings: 'EUR', 'USD' and 'GBP [any number of digits] million'. You need to group your alternatives together in the regex: (EUR|USD|GBP) \d+ million, where EUR|USD|GBP can be either 'EUR' or 'USD' or 'GBP', and \d+ can be any whole number starting from zero.
In segmentation rules, memoQ uses regexes to match patterns in the translation document's text. For auto-translation rules, it uses another powerful regex feature that has to do with groups: replacing and reordering parts of the matched text.
|
Find what |
Replace with |
Description |
|---|---|---|
|
no |
xx |
Finds the characters 'no' and replaces them with 'xx'. (There are no regex-specific elements in this example.) |
|
no... |
xx |
Finds 'no' and the next 3 characters, and replaces them with 'xx'. For example, replaces 'notes' with 'xx', or 'monotone' with 'moxxe'. |
| (one) two | $1 three |
Finds 'one two' and replaces it with 'one three'. |
|
(one) (two) |
$2 $1 $1 |
Finds 'one two' and replaces it with 'two one one'. |
|
(EUR|USD|GBP) (\d+) million |
$2 Millionen $1 |
Finds 'EUR', 'USD', or 'GBP', followed by a number and the word 'million', and replaces it with the number, the word 'Millionen', and the currency code. This is how to convert a financial amount from English to German format. |
-
Replacing a matched text with a single string:
In Find and replace windows, you can enter a regex in the Find what box, and a replacement expression in the Replace with box. The first two rows of the table above show simple examples of replacing a string with another.
-
Reordering and/or replacing parts of a matched text:
Here you need to group all those parts of the regex in pairs of parentheses that you want to reference. The match enclosed in every pair of parentheses is remembered by memoQ and assigned a number starting with 1. When writing the replacement expression you can reference these remembered substrings by
$1,$2etc.:$1refers to the first group in parentheses,$2to the second, and so on.Look at the previous regex example again. To reorder currencies and values, you need to put also
\d+in parentheses:(EUR|USD|GBP) (\d+) million. In the replacement expression you can referenceEUR|USD|GBPby$1, and\d+by$2. To change their order in German, use the replacement expression$2 Millionen $1.
memoQ extensions
|
Sequence |
Description |
|---|---|
|
\tag |
|
|
\itag |
|
|
\mtag |
memoQ tag |
To find tags using regular expressions, you can use three special escape sequences to match them:
\tagmatches any tag\itagmatches an inline tag (one that appears in the text like this: )
)\mtagmatches a memoQ tag (one that appears in the text in {curly brackets})
Tags are usually right next to the text before or after them (without a space). To make regexes more readable, put the above sequences in parentheses '()' when you are looking for a combination of tags and text. Example: '(\itag)int' matches inline tags (opening, closing, or empty) that are followed by words like 'integrated', 'interesting', 'intentional'.
To create segmentation rules and auto-translation rules, it is often useful to work with word lists - of abbreviations, month names, currencies etc. In theory, it is possible to list these words grouped together as alternatives in regular expressions (see the part about alternatives above). However, those regexes would be very complicated and hard to maintain. To make this easier, memoQ has a special extension to regular expressions: custom lists.
Lists of words used in regular expressions can be defined in the Custom lists tab of the segmentation rules dialog or of the auto-translation rules dialog, or in the Translation pairs tab of the auto-translatables dialog.
- Use custom lists on the Edit segmentation rule set window's Custom lists tab to collect characters, abbreviations that are important for segmentation (e.g. '.', '!', 'e.g.').
- Use custom lists on the Edit auto-translation rule set window's Custom lists tab to collect words that have the same source and target form (e.g. '€', '$').
- Use custom lists on the Edit auto-translation rule set window's Translation pairs tab to collect source words with their target equivalents (for example, in English-German projects 'January' should be translated as 'Januar', 'February' as 'Februar', 'March' as "März" etc.).
The name of a custom list must always start and end with a hash mark ('#'). memoQ always treats words in custom lists as plain text - never as meta characters with a special meaning.
Segmentation rules can have one more special item: '#!#'. This extension does nothing to regex matching. Instead, it tells memoQ to put a segment break where the expression matches text in the imported document.
Example for using custom lists on the Auto-translation rules window's Custom lists tab:
To make memoQ offer you '15 Millionen EUR' in the Translation results pane for every occurrence of 'EUR 15 million', and '37 Millionen USD' for 'USD 37 million': On the Custom lists tab, create the custom list #currency# and add the values EUR, USD, and GBP to it.
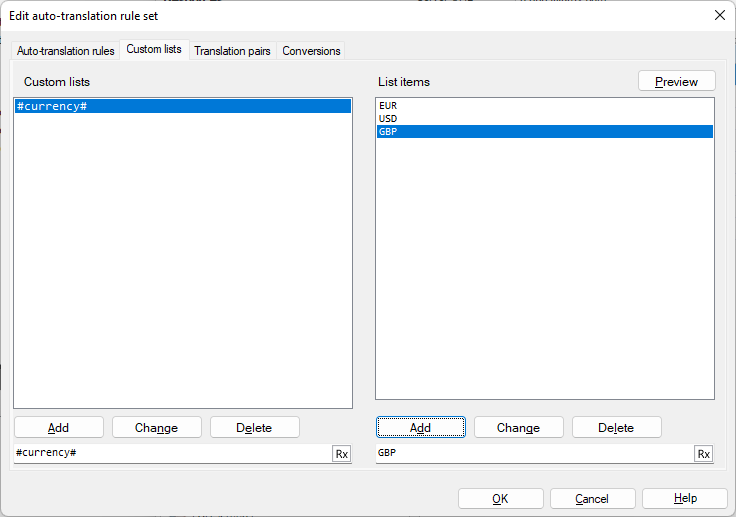
Now, on the Auto-translation rules tab, create the regex (#currency#) (\d{1,}) million (the same as (EUR|USD|GBP) (\d{1,}) million), and the replacement expression $2 Millionen $1. The preview of the above regex and replacement expression will look like this:
![]()
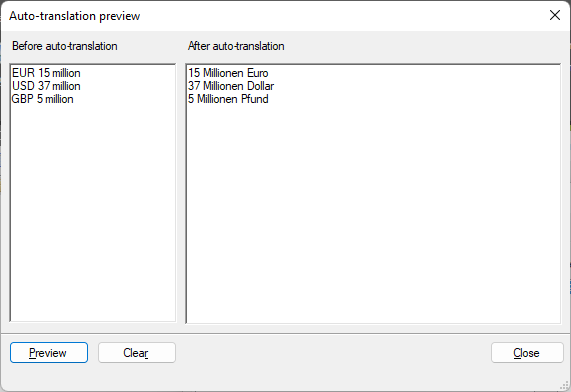
To make memoQ offer you '15 Millionen Euro' in the Translation results pane for every occurrence of 'EUR 15 million' and '37 Millionen Dollar' for 'USD 37 million': On the Translation pairs tab, create a custom list named #currency2#, and add these translation pairs to it: 'EUR' – 'Euro', 'USD' – 'Dollar' and 'GBP' – 'Pfund'.
Use different names: Names for lists on the Translation pairs tab must be different than those on the Custom lists tab.
![]()
Now, on the Auto-translation rules tab, create the regex (#currency2#) (\d{1,}) million and the replacement expression $2 Millionen $1. The preview of the above regex and replacement expression will look like this: