Filtrer les doublons MT
Vous pouvez nettoyer la mémoire de traduction des doublons.
Vous pourriez vous retrouver avec un grand nombre de doublons si vous effectuez l’une des opérations suivantes:
- Confirmer un grand nombre de traductions identiques à cela, en utilisant différents contextes.
- Utilisez une mémoire de traduction qui permet plusieurs traductions pour le même segment source et le même contexte.
- Utiliser une mémoire de traduction sans informations de contexte.
- Importer des fichiers TMX dans la mémoire de traduction avec de nombreux segments source identiques.
- Confirmer beaucoup de segments non textuels (segments tous nombres, ou segments composés de tirets, etc.).
Dans la fenêtre Filtrer les doublons, vous pouvez commencer à chercher les doublons dans votre mémoire de traduction. Vous pouvez exécuter cela sur une mémoire de traduction à la fois.
En fin de compte, memoQ vous donne des groupes d’entrées. Les entrées d’un même groupe sont des doublons l’une de l’autre d’une manière ou d’une autre - selon la condition que vous avez établie dans la fenêtre Filtrer les doublons.
Comment se rendre ici
- Commencer à modifier une mémoire de traduction.
-
Sur l’ éditeur de mémoire de traduction du ruban, cliquez sur Supprimer les doublons. La fenêtre Filtrer les doublons apparaît.
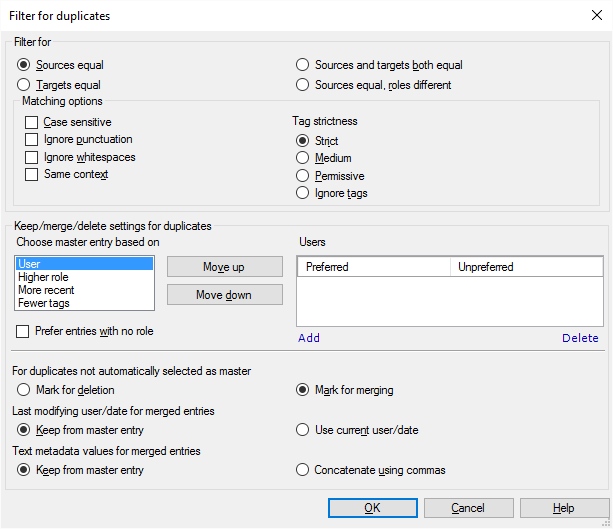
Que pouvez-vous faire?
Deux entrées sont généralement des doublons l’une de l’autre si le texte source est le même dans les deux.
- Sous Filtre pour, vous pouvez peaufiner ceci. Vous avez des boutons radio pour faire votre choix.
Pour nettoyer votre mémoire de traduction des traductions non éditées et des traductions non approuvées: Cliquez sur Sources identiques, rôles différents. Cela vous donnera les entrées où le même segment a été confirmé par un traducteur et également par un relecteur. Dans ce cas, vous voudrez garder celui confirmé par un relecteur.
- Les sources sont égales: les entrées sont des doublons si le texte source est le même dans les deux
- Cibles égales: les entrées sont des doublons si le texte cible est le même dans les deux
- Les sources et les cibles sont égales: les entrées sont des doublons si le texte source et le texte cible sont identiques.
- Les sources sont égales, les rôles sont différents: les entrées sont des doublons si le texte source est le même dans celles-ci, mais le rôle dans lequel elles ont été confirmées est différent. Par exemple, l’un peut avoir été confirmé par un Traducteur, et l’autre par un relecteur 2. Utilisez ceci pour vous débarrasser des traductions non éditées dans la mémoire de traduction.
- Ensuite, choisissez comment les segments sont comparés; ce qui compte comme 'identique'. Décidez à quel point vous voulez être strict à ce sujet. Pour configurer cela, utilisez les cases à cocher et les boutons radio sous les options de Correspondance. Normalement, toutes ces cases à cocher sont décochées, ce qui signifie que deux segments sont identiques s’ils contiennent exactement les mêmes mots, balises, espaces et ponctuation. Le contexte du segment source, et les minuscules et les majuscules peuvent être différents.
- Pour rendre la vérification sensible à la casse, de sorte que les majuscules et les minuscules doivent également être identiques: Cochez la case respect de la casse.
- Accepter deux segments comme identiques même si la ponctuation est différente: Cochez la case Ignorer la ponctuation.
- Accepter deux segments comme identiques même si les espaces sont différents: Cochez la case Ignorer les espaces.
- Accepter deux segments sources comme identiques seulement si les contextes sont les mêmes: Cochez la case Même contexte.
- Permissif signifie que seul le nombre de balises doit être le même.
- Le moyen signifie que les balises doivent avoir le même type (ouvert/fermé/vide), mais les noms de balises et les attributs peuvent être différents. Au départ, memoQ utilise ce paramètre.
- La stricte signification signifie que les balises doivent être exactement les mêmes.
Vous pouvez modifier cela dans les Paramètres de conservation/fusion/suppression des doublons.
Dans un groupe d’entrées dupliquées, une deviendra toujours l’entrée « Master». Vous pouvez décider ce qui arrive aux autres entrées dans le groupe :
- Supprimer les
- Fusionner des détails supplémentaires provenant d’eux dans l’entrée principale
- Gardez-les, donc le doublon reste
Vous pouvez faire votre choix pour chaque groupe lorsque vous serez de retour dans l’éditeur de mémoires de traduction.
Tout d’abord, memoQ doit décider quelle entrée est la principale dans le groupe. Choisissez-en un parmi l’entrée principale choisie en fonction de la liste: Utilisateur,rôle supérieur,plus récent,moins d’étiquettes. Par exemple, votre entrée principale sera celle qui a été ajoutée par un certain utilisateur. Normalement, memoQ suit cette logique:
- L’entrée principale sera celle qui provient d’un utilisateur favori.
- S’il n’y a pas une entrée avec un utilisateur favori: Choisissez celui qui a été confirmé dans le rôle supérieur. Par exemple, le relecteur 2 est supérieur au traducteur, et le traducteur est supérieur à une entrée sans rôle. En fait, vous pouvez faire en sorte que les entrées sans rôle soient les plus élevées: Pour cela, cochez les entrées Préfer sans rôle.
- S’il n’y a pas une entrée qui a le rôle le plus élevé: Choisissez la plus récente.
- S’il y a plusieurs entrées du même temps: Choisissez la balise qui a moins de balises dans le segment source et le segment cible.
Vous pouvez modifier l’ordre de ceux-ci. Cliquez sur une condition, puis cliquez sur le bouton Déplacer vers le haut ou le bouton Déplacez vers le bas.
Dans la liste des utilisateurs, vous pouvez lister les utilisateurs préférés. Ceux-ci seront des personnes expérimentées - relecteurs -, qui confirment régulièrement des segments dans le rôle de relecteur 1 ou de relecteur 2. Pour ajouter un utilisateur favori, cliquez sur Ajouter. Pour retirer un utilisateur de la liste: Cliquez sur le nom de l’utilisateur. Cliquez sur Supprimer.
Vous pouvez également ajouter des utilisateurs non préférés. Si vous avez une liste d’utilisateurs non préférés, d’autres utilisateurs seront préférés à eux. Par exemple, si le groupe de doublons a quatre entrées provenant d’utilisateurs non préférés, et une d’un utilisateur qui n’est pas sur la liste, memoQ choisira cette cinquième comme entrée principale.
Ensuite, choisissez ce qui arrive à ces entrées qui sont fusionnées dans l’entrée principale.
Vous pouvez ajouter plus d’un utilisateur à ces listes, si leurs noms d’utilisateur commencent par les mêmes caractères. Par exemple, si tous les traducteurs ont des noms d’utilisateur comme tr-jp1, tr-fr3, tr-de1, vous pouvez tous les ajouter à la liste des non préférés. Cliquez sur le lien Ajouter: Dans la fenêtre Ajouter un utilisateur préféré/non préféré, cochez la case Ceci est un préfixe de nom d’utilisateur. Entrez tr- dans la zone Nom d’utilisateur, et cliquez sur OK. La colonne « tr-* » a maintenant une ligne «tr-*». Cela signifie que memoQ considère tous les utilisateurs dont le nom d’utilisateur commence par "tr-" comme des utilisateurs non préférés.
- Action sur les doublons non retenus comme entrées principales: Soit cliquez sur Marquer pour suppression ou Marquer pour fusion. Normalement, memoQ marque les entrées non principales pour les fusionner dans l’entrée principale.
Ne choisissez pas Marquer pour suppression à moins d’être absolument certain que les doublons sont complètement identiques, mêmes segments, mêmes balises, même contexte, mêmes champs. Dans tous les autres cas, vous devriez choisir Mark pour la fusion. Sinon vous perdrez des informations de la mémoire de traduction.
- Nom d’utilisateur/date de modification des entrées fusionnées: Choisissez si la date de modification et la dernière modification doivent provenir de l’entrée principale - ou de la session d’édition actuelle. Soit cliquez sur Conserver infos de l'entrée principale ou Utiliser date/utilisateur au moment de la fusion. Vous ne pouvez pas conserver les dates et les utilisateurs des entrées non-masters (fusées).
- Métadonnées texte des valeurs pour les entrées fusionnées: Si les champs de métadonnées contiennent des informations contradictoires dans l’entrée principale et dans les entrées non principales (entrées fusionnées), choisissez ce qui doit se passer. Vous pouvez utiliser la valeur de l’entrée principale, ou vous pouvez utiliser toutes, ajoutées ensemble avec des virgules. Pour la première, cliquez sur Conserver à partir de l’entrée principale. Pour ce dernier, cliquez sur Concaténer en utilisant des virgules.
Lorsque vous avez terminé
Chercher tous les doublons et revenir à l’éditeur de mémoires de traduction: Cliquez sur OK.
Retourner à l’éditeur de mémoires de traduction et ne pas chercher les doublons: Cliquez sur Annuler.
Après que memoQ a trouvé les doublons, il affiche une liste spéciale qui contient les groupes de doublons, et non les entrées individuelles.
Pour en savoir plus : Consultez la documentation sur l’éditeur de mémoires de traduction.