Expressions régulières
Les expressions régulières sont un moyen puissant de trouver des séquences de caractères dans le texte. Dans memoQ, elles sont utilisées pour définir des règles de segmentation, des règles d’auto-substitution ou des règles pour le Module de balisage RegEx. Vous pouvez également utiliser des expressions régulières dans Rechercher et remplacer, ainsi que dans les champs Filtrer dans l’éditeur de traduction.
Trouver des séquences de caractères est une tâche familière pour quiconque a déjà utilisé un traitement de texte ou un éditeur de texte. La boîte de dialogue Rechercher ou rechercher sert à cet effet – si vous recherchez 'cat', votre éditeur mettra en surbrillance les mots (ou parties de mots) tels que 'cat', 'cats' ou même 'sophistiques'.
Les expressions régulières, cependant, offrent beaucoup plus de liberté pour indiquer à l’ordinateur ce que vous recherchez. Vous pouvez identifier des séquences telles qu’une lettre 'a', suivie de deux ou trois lettres 'c’ ; un certain nombre de lettres suivies d’un ou plusieurs chiffres; l’un des mots 'chat', 'chien' ou 'souris' ; ou même les occurrences d’un mot lorsqu’il est entre guillemets – et bien plus encore. Après avoir lu cette page et expérimenté les exemples, vous saurez exactement comment. Si vous ne vous sentez pas prêt à apprendre les détails, l’Assistant Regex vous aidera.
Remarque : Le terme expression régulière provient de la théorie mathématique sur laquelle cette méthode de correspondance de motif est basée. Il est souvent abrégé en regex ou regexp – ici nous utiliserons regex, ou au pluriel, regexes.
La syntaxe regex a de nombreuses variantes(saveurs) : memoQ utilise le moteur regex .NET, et donc la saveur .NET. Cet article ne décrit qu’une partie de la syntaxe regex .NET – pour la documentation détaillée, consultez la section correspondante du site Microsoft Learn.
Fonctionnalités regex standard .NET
Dans la fonction de recherche à l’ancienne d’un traitement de texte, chaque caractère est interprété littéralement. Si vous cherchez 'Oui? Non... cela mettra en évidence 'Oui? Non...' – ou rien si ces caractères n’apparaissent pas dans le texte. Dans une regex, cependant, certains caractères ont une signification particulière – ceux-ci sont appelés caractères méta. Les plus importants métacaractères sont:
Confus? Ce tableau est seulement destiné à un court résumé et à une référence – la signification de toutes ces expressions sera clarifiée dans les sections ci-dessous.
Pour l’instant, concentrons-nous sur le premier, le point. Dans une regex, cela signifie 'tout caractère peut se trouver ici'. Donc l’expression No... dans un regex correspond à l’un des éléments suivants:
- Notes
- Notte
- Non...
- Pas& %X
Alors, que devez-vous écrire dans un regex pour correspondre précisément à 'Non...' et aucun autre texte? Pour faire correspondre un caractère qui a une signification spéciale, vous devez le « échapper » : c’est-à-dire ajouter un antislash devant. Ainsi, No\.\.\. correspond exactement à 'Non...' et rien d’autre.
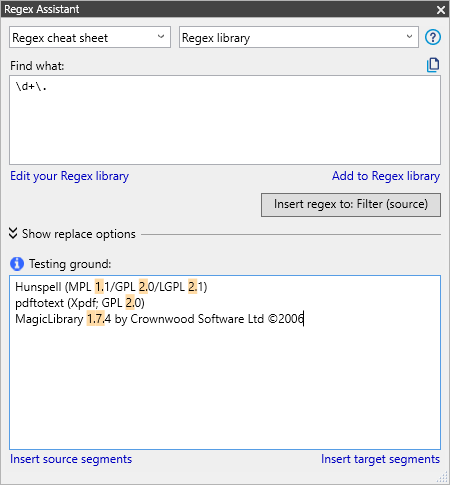
L 'Assistant Regex a un terrain de test pour exactement cela. Copiez et collez du texte dans la zone de Terrain d'essai, puis tapez votre expression régulière dans la zone Rechercher. Cela met en surbrillance memoQ les parties de texte qui correspondent à la regex :
Maintenant que nous avons traité le point et que nous savons comment expérimenter avec de nouveaux regex, passons à des expressions plus sérieuses. Les crochets dans les regex permettent de spécifier un ensemble de caractères – une classe de caractères.[ab][01] correspond à des séquences de deux caractères où le premier caractère est soit un 'a' soit un 'b', et le second est soit un '0' soit un '1'. Cela donne 4 correspondances possibles: « a0 », « b0 », « a1 », « b1 ».
Les classes de caractères peuvent être utilisées pour exprimer des choses comme 'un chiffre suivi d’une virgule ou d’un point d’exclamation' – ce qui pourrait être exprimé comme [0123456789][,!]. Ceci, cependant, serait une chose très incommode à écrire. Les regex savent mieux: vous pouvez spécifier une plage de caractères en écrivant [0-9][,!, ce qui signifie exactement la même chose que la regex précédente.
Peux-tu utiliser une classe de caractères pour faire correspondre une lettre alphabétique? Oui et non: Le regex [a-z] correspond à l’une des lettres entre a et z – l’une des lettres dans l’alphabet latin. Mais memoQ fonctionne avec plusieurs langues qui ont des caractères spéciaux dans leur alphabet. Par exemple, la lettre islandaise 'đ' n’est pas dans la plage 'a-z'. Mais il existe des moyens faciles de traiter de tels caractères - voir la partie sur les raccourcis ci-dessous.
De plus, gardez à l’esprit que toutes les lettres dans les regex memoQ sont interprétées dans une manière respectant la casse. Ainsi, [a-z] correspond donc « f » mais pas « F ».
Vous pouvez également utiliser des classes de caractères pour spécifier ce qui ne doit pas correspondre. La regex [^0a]. correspond à toute séquence de deux caractères où le premier caractère n’est pas '0' ou 'a'.
Comme vous l’avez vu plus tôt, vous devez échapper les caractères méta spéciaux (ajouter un antislash avant eux) pour les utiliser comme des caractères normaux: pour correspondre à un signe '+' réel, vous devez utiliser les caractères \+ dans votre regex. Il existe également d’autres séquences d’échappement pratiques disponibles, par exemple \t correspond à un caractère de tabulation, et \n correspond à un saut de ligne. Et de nombreuses séquences d’échappement sont des raccourcis pour les classes de caractères:
|
Séquence |
Description |
|---|---|
|
\s |
Espaces: espace, tabulation ou saut de ligne |
|
\S |
Tout sauf un espace |
|
\d |
Chiffre |
|
\D |
Autre chose qu’un chiffre |
|
\M |
Caractère alphanumérique et trait de soulignement |
|
\M |
Tout sauf un caractère alphanumérique |
Ces raccourcis sont un peu différents des classes de caractères de base dans la section précédente: \d correspond à tous les chiffres décimals Unicode (provenant de nombreux systèmes d’écriture), pas seulement [0-9], et \w correspond à toutes les lettres Unicode (minuscules et majuscules), les nombres, et le tiret ('_'), pas seulement [a-z].
Maintenant que vous avez appris à faire correspondre des caractères à une position donnée, il est temps de dire memoQ combien de caractères à faire correspondre. Les caractères spéciaux '*', '+', et ' ?', ainsi que l’expression '{num}' sont utilisés à cette fin.
|
Expression |
Description |
|---|---|
|
* |
Le caractère à gauche de l’astérisque dans l’expression doit correspondre 0 ou plus de fois. Par exemple, |
|
+ |
Le caractère à gauche du signe plus dans l’expression doit correspondre 1 ou plus de fois. Par exemple, |
|
? |
Le caractère à gauche du point d’interrogation dans l’expression doit correspondre 0 ou 1 fois. Par exemple, |
|
{Num} |
Le caractère à gauche du nombre joint devrait correspondre au num fois. Par exemple, |
-
Le regex
x+correspond à une séquence d’un ou plusieurs 'x' – donc, 'x', 'xx', 'xxx' et ainsi de suite. -
Le regex
x{3}correspond à une séquence de exactement 3 'x' – donc, 'xxx', mais pas 'x' ou 'xx'. Si le texte est 'xxxx', le regex correspond aux 3 premiers 'x' et ignore le quatrième: 'xxxx'. Tout comme la boîte de dialogue Rechercher traditionnelle trouvera le mot « cat » dans « cats ». -
Vous pouvez également utiliser le quantificateur '{num}' pour spécifier une valeur minimale (et si nécessaire, une valeur maximale). Ainsi,
x{3,5}correspond entre 3 et 5 'x's;x{3,}correspond au moins 3 'x's.x{,5}ne fonctionnera pas cette façon : Pour correspondre à un maximum de 5 'x's, utilisezx{0,5}. -
Le regex
x*ycorrespond à un 'y' précédé d’un nombre quelconque de 'x' (même zéro) - donc, 'y', 'xy', 'xxy' et ainsi de suite, mais pas 'zy'. -
Le regex
zx?ycorrespond à un 'z' suivi de zéro ou un 'x' et d’un 'y' - donc, 'zy' et 'zxy', mais pas 'zxxy'.
Pour une utilisation encore plus puissante, combinez des ensembles de caractères ou des abréviations avec des quantificateurs: [0-9]+% ou \d+% correspond à un ou plusieurs chiffres suivis d’un signe de pourcentage; par exemple, '1%' ou '99%', mais pas '10a%'.
Utilisez le symbole de barre verticale ('|') pour joindre plusieurs petites regex afin de dire 'correspondre soit à ceci, soit à cela, soit à l’autre chose'. Le regex EUR|USD|GBP correspond à ces mots, et seulement à ceux-ci.
Lorsqu’on travaille avec des alternatives, il est souvent nécessaire de les regrouper à l’aide de parenthèses pour obtenir les résultats souhaités. Par exemple, vous avez besoin d’un regex qui correspond à l’une de ces expressions: « 15 millions d’EUR », « 37 millions USD » et « 5 millions GBP ». Comme premier essai, vous pourriez être enclin à d’écrire EUR|USD|GBP \d+ million. Cela, cependant, ne suffira pas, car cela ne correspond qu’aux chaînes suivantes: 'EUR', 'USD' et 'GBP [n’importe quel nombre de chiffres] millions'. Vous devez regrouper vos alternatives dans le regex: (EUR|USD|GBP) \d+ million, où EUR|USD|GBP peut être soit 'EUR' soit 'USD' soit 'GBP', et \d+ peut être n’importe quel nombre entier à partir de zéro.
Dans les règles de segmentation, memoQ utilise des regex pour faire correspondre des modèles dans le texte du document de traduction. Pour les règles d’auto-substitution, elle utilise une autre fonctionnalité puissante de regex qui concerne les groupes: remplacement et réorganisation des parties du texte correspondant.
|
Élément à rechercher |
Remplacer par |
Description |
|---|---|---|
|
no |
xx |
Trouve les caractères « non » et les remplace par « xx ». (Il n’y a pas d’éléments spécifiques aux Regex dans cet exemple.) |
|
non... |
xx |
Trouve 'Non' et les 3 caractères suivants, et les remplace par 'xx'. Par exemple, remplace 'notes' par 'xx', ou'monotone' par 'moxxe'. |
| (un) deux | 1 trois |
Trouve 'un deux' et le remplace par 'trois'. |
|
(un) (deux) |
$2 $1 $1 |
Trouve 'un deux' et le remplace par 'deux un un'. |
|
(EUR|USD|GBP) (\d+) million |
$2 Millionen $1 |
Trouve 'EUR', 'USD' ou 'GBP', suivi d’un nombre et du mot 'million', et le remplace par le nombre, le mot 'Millionen' et le code de la devise. Voici comment convertir un montant financier du format anglais au format allemand. |
-
Remplacer un texte correspondant par une seule chaîne:
Dans les Rechercher et remplacer les fenêtres, vous pouvez entrer un regex dans la zone Rechercher dans, et une expression de remplacement dans la zone Remplacer par. Les deux premiers segments du tableau ci-dessus montrent des exemples simples de remplacement d’une chaîne par une autre.
-
Commande et/ou remplacement de parties d’un texte correspondant:
Ici, vous devez regrouper toutes ces parties du regex par paires de parenthèses que vous souhaitez référencer. La correspondance enfermée dans chaque paire de parenthèses est mémorisée par memoQ et attribuée un nombre commençant par 1. Lors de l’écriture de l’expression de remplacement, vous pouvez faire référence à ces sous-chaînes mémorisées par
$1,$2etc. :$1fait référence au premier groupe entre parenthèses,$2à la seconde, et ainsi de suite.Regardez à nouveau l’exemple de regex précédent. Pour réorganiser les devises et les valeurs, vous devez également mettre
\d+entre parenthèses:(EUR|USD|GBP) (\d+) million. Dans l’expression de remplacement, vous pouvez référencerEUR|USD|GBPpar$1, et\d+par$2. Pour changer leur ordre en allemand, utilisez l’expression de remplacement$2 Millionen $1.
extensions memoQ
|
Séquence |
Description |
|---|---|
|
\tAG |
Interne ou memoQ balise |
|
\Ag |
Balise interne |
|
\MTAG |
memoQ balise |
Pour trouver des balises à l’aide d’expressions régulières, vous pouvez utiliser trois séquences d’échappement spéciales pour les faire correspondre:
\tagcorrespond à n’importe quelle balise\itagcorrespond à une balise interne (celle qui apparaît dans le texte comme ceci: )
)\mtagcorrespond à une balise memoQ (celle qui apparaît dans le texte entre {accolades})
Les balises sont généralement juste à côté du texte avant ou après elles (sans espace). Pour rendre les regex plus lisibles, placez les séquences ci-dessus entre parenthèses '()' lorsque vous recherchez une combinaison de balises et de texte. Exemple: '(\itag)int' correspond à des balises internes (ouvertes, fermées ou vides) qui sont suivies de mots comme 'intégré', 'intéressant', 'intentionnel'.
Pour créer des règles de segmentation et des règles d’auto-substitution, il est souvent utile de travailler avec des listes de mots - d’abréviations, de noms de mois, de devises, etc. En théorie, il est possible de lister ces mots regroupés comme alternatives dans des expressions régulières (voir la partie sur les alternatives ci-dessus). Cependant, ces regex seraient très compliqués et difficiles à maintenir. Pour faciliter cela, memoQ il y a une extension spéciale aux expressions régulières: listes personnalisées.
Les listes de mots utilisées dans les expressions régulières peuvent être définies dans l’onglet des listes personnalisées de la boîte de dialogue des règles de segmentation ou de la boîte de dialogue des règles d’auto-substitution, ou dans l’onglet des paires de traduction de la boîte de dialogue des auto-substituables.
- Utilisez des listes personnalisées dans l’onglet Modifier les règles de segmentation pour collecter des caractères, des abréviations qui sont importantes pour la segmentation (par exemple, '.', ' !', 'par exemple').
- Utilisez des listes personnalisées dans l 'onglet Listes personnalisées de la fenêtre Ensemble de règles d’auto-substitution pour rassembler des mots qui ont la même forme source et cible (par exemple, '€', '$').
- Utilisez des listes personnalisées dans l 'onglet Paires de traduction de la fenêtre Ensemble de règles d’auto- substitutionpour rassembler les mots sources avec leurs équivalents cibles (par exemple, dans les projets anglais-allemand, 'January' devrait être traduit par 'Januar', 'February' par 'Februar', 'March' par 'März', etc.).
Le nom d’une liste personnalisée doit toujours commencer et se terminer par un marqueur de hachage ('#'). memoQ traite toujours les mots dans les listes personnalisées comme du texte brut - jamais comme des méta caractères avec une signification particulière.
Les règles de segmentation peuvent avoir un élément spécial de plus: '# !#'. Cette extension ne fait rien à la correspondance regex. Au lieu de cela, cela indique à memoQ de mettre un saut de segment là où l’expression correspond au texte dans le document importé.
Exemple d’utilisation des listes personnalisées dans l’onglet Listes personnalisées de la fenêtre des règles d’auto-substitution:
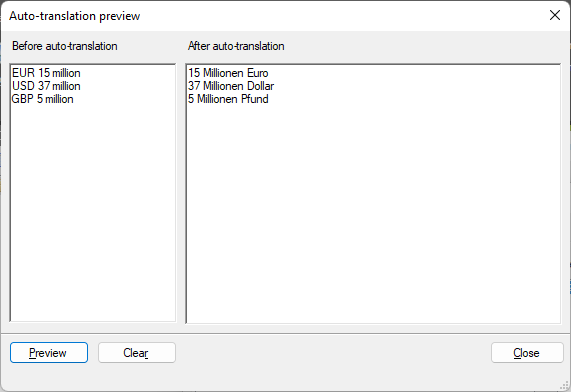
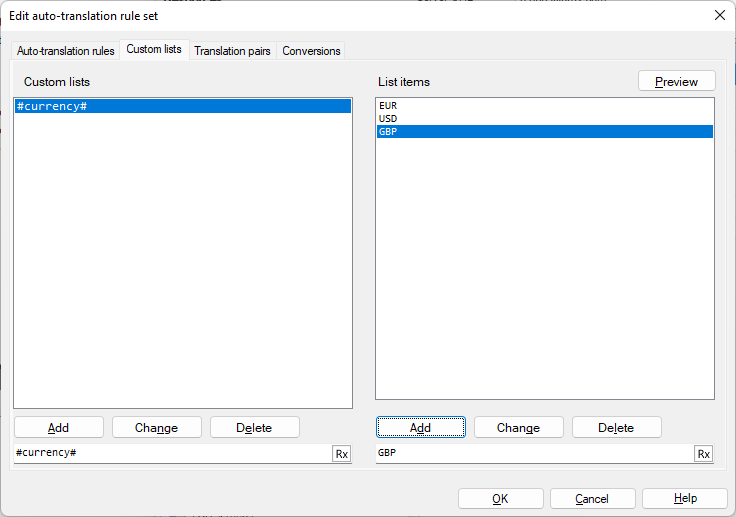
Pour faire en sorte que memoQ vous propose '15 millions EUR' dans le panneau des résultats de traduction pour chaque occurrence de 'EUR 15 million', et '37 millions USD' pour 'USD 37 million' : Sur l’onglet Listes personnalisées, créez la liste personnalisée #currency# et ajoutez les valeurs EUR, USD et GBP à celle-ci.
Maintenant, dans l’onglet des règles d’auto-substitution, créez la regex (#currency#) (\d{1,}) million (la même que (EUR|USD|GBP) (\d{1,}) million), et l’expression de remplacement $2 Millionen $1. L’aperçu de la regex et de l’expression de remplacement ci-dessus ressemblera à ceci :
![]()
Pour memoQ vous offrir '15 millions d’euros' dans le panneau des résultats de traduction pour chaque occurrence de 'EUR 15 million' et '37 millions de dollars' pour 'USD 37 million' : Sur l’onglet paires de traduction, créez une liste personnalisée appelée #currency2# et ajoutez-y ces paires de traduction: 'EUR' – 'Euro', 'USD' – 'Dollar' et 'GBP' – 'Livre'.
Utiliser des noms différents: Les noms pour les listes dans l’onglet paires de traduction doivent être différents de ceux dans l’onglet Listes personnalisées.
![]()
Maintenant, dans l’onglet des règles d’auto-substitution, créez le regex (#currency2#) (\d{1,}) million et l’expression de remplacement $2 Millionen $1. L’aperçu de la regex et de l’expression de remplacement ci-dessus ressemblera à ceci :