memoQ editorの詳細フィルタ
詳細フィルタウィンドウは、翻訳ドキュメント内のコンテンツを迅速に絞り込むのに役立ちます。memoQ editorで行をフィルタリングするための条件を設定できます。これにより、現在のタスクに関連するセグメントやエレメントに集中でき、時間を節約し、効率を向上させることができます。
操作手順
- オンラインプロジェクトを開きます。
- 編集するドキュメントを開きます。
- 翻訳グリッドの上部にあるフィルタをクリアとフィルタを適用の隣にある詳細フィルタをクリックします。
これにより、完全な詳細フィルタダイアログが開きます。
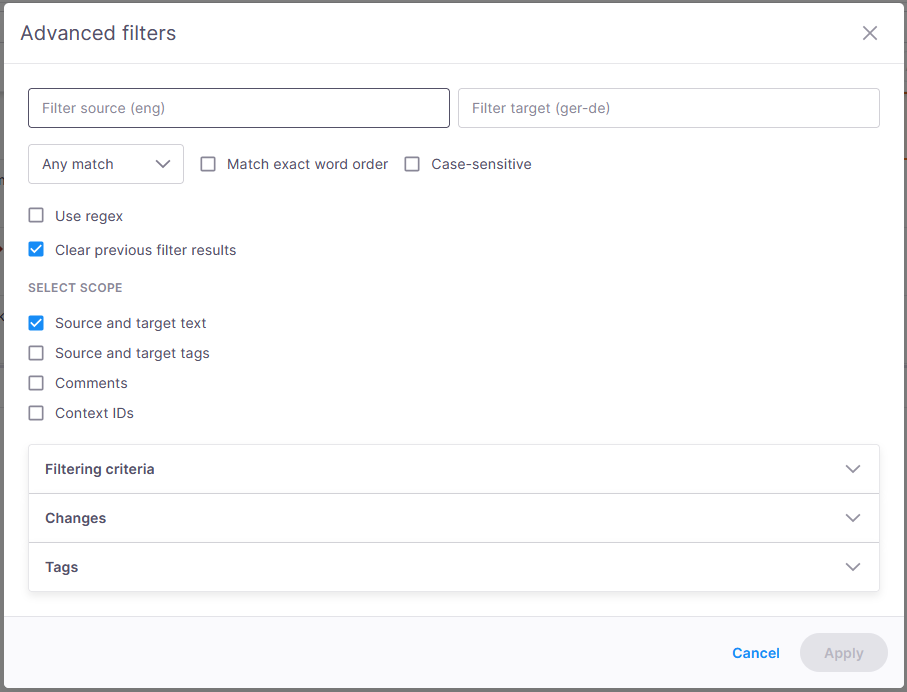
その他のオプション
これらのコントロールは、メインツールバーに表示されているものと一致しており、常に同期しています。
-
ソースとターゲットのフィルタリングの入力フィールド - これらはメイン画面のフィルタリングの入力と同期しています。こちらまたはメイン画面でテキストを変更すると、両方が即座にアップデートされます。
-
一致種類ドロップダウンを使用してmemoQのテキストの検索方法を定義します:
-
すべての一致:テキストの一部に検索用語が含まれています。例:「table」でフィルタリングすると、「tables」を含むセグメントが返されますが、「tabloid」は返されません。
-
語句一致:このオプションは検索用語がテキスト内の単語全体と一致しなければなりません。例:「table」でフィルタリングすると、「table」を含むセグメントが返されますが、「tables」は返されません。
-
セグメント全体:これは、memoQが検索用語と完全に一致するセグメントのみを返すことを意味します。例:「table」でフィルタリングすると、フルテキストが「table」であるセグメントのみが返されます。
-
必要に応じて、単語の順序を完全に一致させるオプションをオンにして、入力したとおりの順序で単語を検索します。
これがオフのとき、memoQはセグメント内の同じ単語を任意の順序で検索します。このオプションは、ドロップダウンからセグメント全体オプションを選択したときには利用できません。
-
大文字と小文字を区別:大文字と小文字は検索語と完全に一致する必要があります。例:「table」でフィルタリングすると、「table」を含むセグメントが返されますが、「Table」は返されません。
-
-
正規表現を使用 - 正規表現を使用したフィルタリングができ、より高度で柔軟な検索パターンを作成できます。
オンにして適用をクリックすると:
-
一致のドロップダウン、単語の順序を完全に一致させる、および大文字と小文字を区別オプションは利用できなくなります。なぜなら、正規表現が一致の動作を制御するためです。
-
両方のフィルタ入力フィールドのフォントが変更され、入力したテキストが正規表現として解釈されることを示します。
-
フィルタ入力フィールドの既存のコンテンツはそのままで、何もクリアされたりリセットされたりしません。
このオプションは、単純なテキスト一致よりも強力で正確なフィルタが必要な場合に使用します。
-
-
これ以前のフィルタ結果をクリア (デフォルトでオン) - memoQ editor はすべての以前のフィルタリング結果を自動的にクリアし、ドキュメント全体にフィルタを再適用します。オフの場合、新しいフィルタリングは既存の結果からの絞り込みとなり、フィルタをクリアをクリックするまで続きます。
ここでは、フィルタリングに含めるべきセグメントの部分を決定します:
-
ソースとターゲットのテキスト(デフォルトでオン)
-
ソースとターゲットのタグ
-
コメント
-
コンテキストID
フィルタリングは、選択した組み合わせの範囲で一致する行のみを表示します。
ここでは、便利なフィルタリングオプションのセットから選択することで、翻訳ドキュメントのどの部分を表示するかを正確に微調整できます。
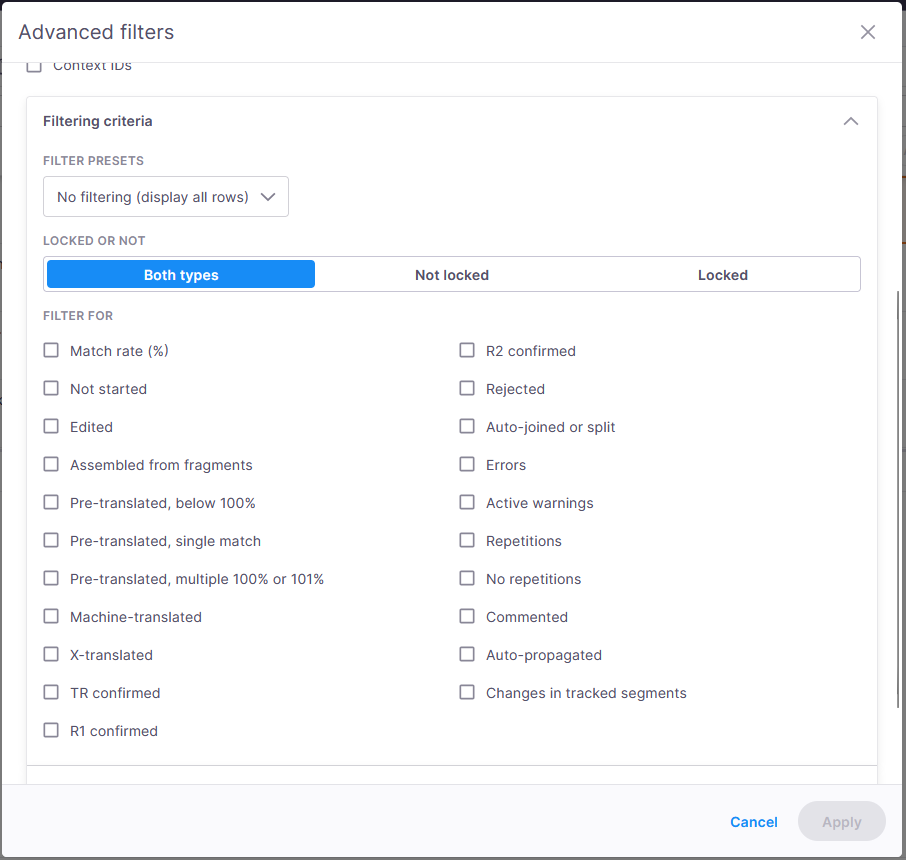
動作は次のとおりです:
-
フィルタのプリセットドロップダウンメニュー - 表示するセグメントの種類をコントロールする定義済みのフィルタセットからすばやく選択できます。
以下のオプションがあります:
-
フィルタなし — すべての行を表示します (これはデフォルトの設定です)。
-
どの役割によっても確定されていない — 誰によっても確定されていないセグメント。
-
TR、R1、またはR2確定済み — これらの役割によって確定されたセグメント。
-
前翻訳済み — 前翻訳状況のセグメント。
-
マッチ率 (%) — マッチ率に基づいてフィルタをかけることができます(詳細は下のプロパティのセクションを参照してください)。
-
エラー — エラーがフラグされたセグメント。
-
繰り返し — ドキュメント内の繰り返しセグメント。
-
ロック済み — ロックされたセグメント。
-
ロック済みでない — ロックされていないセグメント。
-
カスタム — あなた自身のカスタムフィルタ設定。
適用をクリックすると、すべての変更は、カスタムプリセットに対して現在のセッション用に保存されます。
プリセットが選択されている際にフィルタリングオプションを手動で変更し始めると、ドロップダウンは自動的にカスタムに切り替わり、独自の設定を使用していることを示します。
-
ロック済みまたはロックされていないセクション
プリセットのすぐ下に、3つのオプションがあるトグルが表示されます。
-
両方 (デフォルト) — ロック済みセグメントとロック解除セグメントの両方を表示します。
-
ロック済みでない — ロック解除セグメントのみを表示します。
-
ロック済み — ロック済みセグメントのみを表示します。
次でフィルタリングセクション
ここでは、チェックボックスを使用してフィルタリングしたい特定の条件を選択できます。
-
マッチ率 (%) — オンにすると、0%から102%の範囲を選択して、セグメントをその一致スコアでフィルタリングすることができます。
-
開始前 — まだ翻訳を始めていないセグメント。
-
編集済み — 変更したが確定していないセグメント。
-
フラグメント結合済み — フラグメントを組み合わせて作成されたセグメント。
-
前翻訳済み、100% 未満 — TM または資料の良好一致オプションを使用して前翻訳されたセグメント。
-
前翻訳済み、一致1件 — 単一の完全一致で前翻訳されたセグメント。
-
前翻訳済み、100% または101% 一致 (複数) — 複数の完全一致またはコンテキストマッチから前翻訳されたセグメント。
-
機械翻訳済み — MTサービスで翻訳されたセグメント。
-
TR 確定済み, R1確定済み, R2確定済み — 特定の役割によって確定されたセグメント。
-
拒否済み — 拒否したセグメント。
-
自動結合または分割 — 自動的に結合または分割されたセグメント。
-
エラー — エラーのフラグ付き。
-
アクティブな警告 — 現在警告あり。
-
繰り返し — ドキュメント内の繰り返しセグメント。
-
繰り返しでない — 繰り返しではないセグメント。
-
コメント付き — コメント付きのセグメント。
-
自動伝播済み — 自動伝播によって更新されたセグメント。
-
変更履歴付きセグメントの変更内容 — 変更履歴が残されたセグメント。
このアコーディオンは、編集履歴や状況に基づいてセグメントをフィルタリングするのに役立ちます。
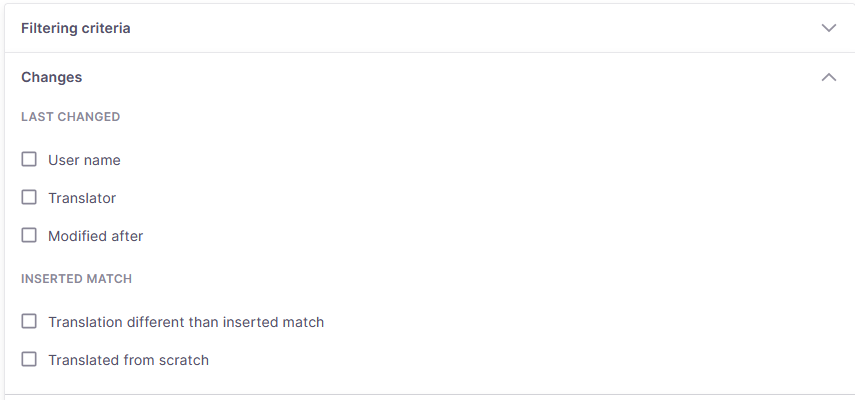
フィルタリングできる項目は以下のとおりです:
-
最終変更日時 -このセクションでは、最後に変更した人や最後に変更された日時に基づいて行をフィルタリングすることができます。
-
ユーザー名 - 最後に行を編集した人物でフィルタリングするのに使用します。変更を加えたユーザーのドロップダウンが表示され、デフォルトの選択は自分以外のすべてのユーザーに設定されます(自分の作業をフィルタリングしないように)。
-
翻訳者 - ユーザー名フィルタに似ていますが、行で作業した翻訳者専用で、デフォルトの選択は「自分以外の全員」に設定されています(自分の作業をフィルタリングしないように)。
上記の両方の場合、ユーザーリストはこのオプションを選択したときのみ読み込まれるため、遅くなることはありません。
-
次の日時以降に修正あり - 日付と時刻を選択し、そのタイミング以降に変更された行のみを表示します。
-
-
挿入された一致テキスト - このセクションでは、挿入された一致の状況に基づいて行をフィルタリングするのに役立ちます。
-
挿入された一致と翻訳が異なる - オンにすると、挿入された一致が変更された行を検索します。
-
新規翻訳済み - オンにすると、翻訳が完全に新規で行われた行(一致が挿入されていない)を表示します。
-
タグアコーディオンは、特定のタグを含む行を見つけるのに役立ち、ドキュメントで最も重要な部分に焦点を当てることができます。
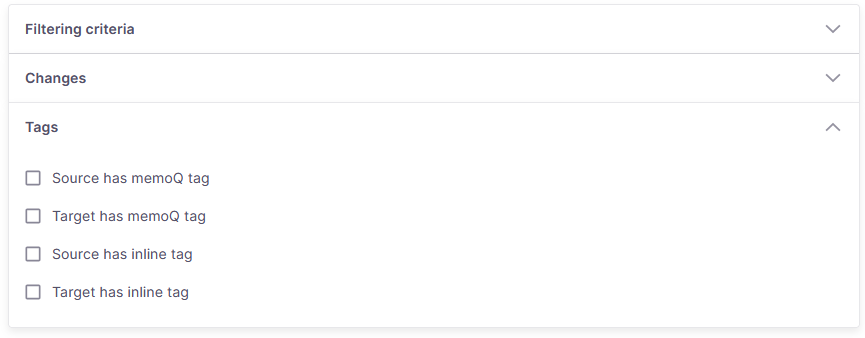
ここでできることは以下のとおりです:
-
ソースにmemoQのタグがある - ソーステキストに特別な書式設定タグが含まれている行を検索し、それがmemoQによってテキストとして解釈されないものを見つけます。
-
ターゲットにmemoQのタグがある - ターゲットテキストに未解釈の書式設定タグが含まれている行を検索します。これは、書式設定の問題を確認または修正する必要がある場合に重要です。
未解釈の書式設定タグは、通常の単語として表示されない特別なコードやマーカーであり、太字、イタリック、ハイパーリンク、またはプレースホルダーのような書式設定や構造を制御します。memoQでは、これらのタグは翻訳データの一部ですが、編集者には可視テキストとして表示されません。システムはこれらを通常の単語ではなく、特別なエレメントとして扱うため、未解釈と呼ばれています。
-
ソースにインラインタグがある - ソーステキストに特定のテキストを含むインラインタグが含まれる行を検索します。
-
ターゲットにインラインタグがある - ターゲットテキストに特定のテキストを含むインラインタグが含まれる行を検索します。
完了したら
フィルタの選択を確定するには、ウィンドウの下で適用をクリックします。
memoQ editorはその後:
-
詳細フィルタ設定のすべての変更を保存し、ダイアログを閉じます。
-
メイン画面をアップデートして、そこにあるフィルタリングの入力(ソースおよびターゲットテキストフィールド、マッチドロップダウン、2つのチェックボックス)が、あなたが設定したのと全く同じ値を表示するようにします。
-
基本フィルタと詳細フィルタオプションの両方を使用してグリッドをフィルタリングし、表示される行が選択したすべての条件に一致するようにします。
上記の動作のおかげで、すべてが同期され、フィルタされたビューは最新の設定を反映します。