翻訳結果ペイン
あなたが翻訳するとき、memoQはバックグラウンドであなたを支援します。翻訳メモリ、ライブ文書資料、用語ベース、フラグメント検索、自動翻訳ルール、サブセグメント一致など、いくつかのローカルおよびオンライン翻訳リソースの能力を統合します。すべてのクエリの結果が収集され、
別の行に進むと、memoQは翻訳リソースのクエリを開始します。さまざまなタイプのリソースについては、以下のセクションで詳しく説明します。
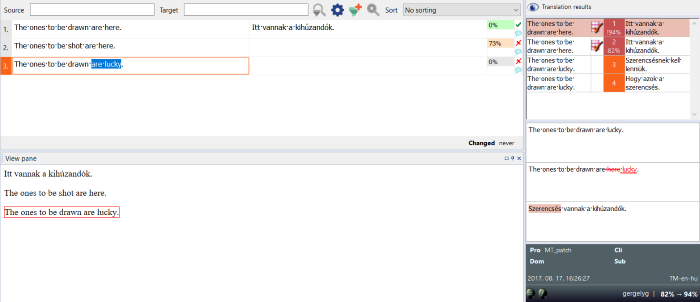
翻訳結果ペインには、3つの部分があります:
上部:
翻訳結果ペインの上部には、すべての翻訳リソースからの翻訳結果 (ヒット) のリストが表示されます。
- 左側の列には、リソースからのソース言語のエントリーが表示されます。
- 中央の列には識別番号が表示されます。
- 右側の列には、ターゲット言語に相当するものがあります (ある場合)。
リストに複数の結果が含まれている場合は、Ctrl+上キーとCtrl+下キーを使用して、リスト内でハイライトを上下に移動できます。
テンキーを使いますか?Page Up、Page Down、ホーム、末尾、上へ(U)または下へ(D)キーを使用するショートカットの場合は、NumLockをオフにする必要があります。
各結果の背景色は、検索先のリソースを示します:
翻訳メモリやライブ文書資料からの候補は赤色で表示されます。memoQは、現在のソースセグメントと、プロジェクトに追加されたさまざまな翻訳メモリに保存されているソースセグメントを比較します。
比較アルゴリズムでは文字と単語を使用しますが、それらの意味は使用しません。memoQが類似していると考えるセグメントの中に、実際にはまったく異なる意味を持つものがあっても驚かないでください。
「赤色」(TMのような) 一致には、次の3種類があります:
-
 - この一致は、ライブ文書資料にあるバイリンガル文書からのものです。
- この一致は、ライブ文書資料にあるバイリンガル文書からのものです。 -
 - この一致は、ライブ文書資料の整合ペアからのものです。
- この一致は、ライブ文書資料の整合ペアからのものです。 -
 - この一致は、翻訳メモリ (TM) からのものです。
- この一致は、翻訳メモリ (TM) からのものです。
翻訳メモリから一致が見つかった場合は、エントリを編集できます:翻訳結果リスト内の項目を右クリックし、メニューで
TM一致には、マッチ率 (%) があります:この数値は、一致するソーステキストと現在のセグメントのソーステキスト間の類似性を示します。
翻訳メモリまたはライブ文書資料から一致を受け取ると、memoQはその一致にスコアを付けます。このスコアは、現在のソースセグメントが、memoQがリソース内で検出したセグメントどの程度類似しているかを示します。コンテキストマッチ、完全一致、またはファジーマッチを受け取れます。それぞれの意味は次のとおりです:
-
コンテキストマッチ:ランニングテキストで、ソースセグメントはリソースと完全に同じです。さらに、前のセグメントと次のセグメントが同じです (ソーステキスト)。構造化 (XML) 文書または表では、ソースセグメントといわゆるコンテキスト識別子は、リソースと同じです。文書にランニングテキストとコンテキスト識別子があり、両方が同じ一致がある場合は、二重コンテキストマッチと呼びます。シンプルコンテキストマッチのマッチ率は101%です。二重コンテキストマッチのマッチ率は102%です。
-
完全一致:ソースセグメントはドキュメントとリソースでまったく同じですが、コンテキストが異なります。マッチ率は100%です。
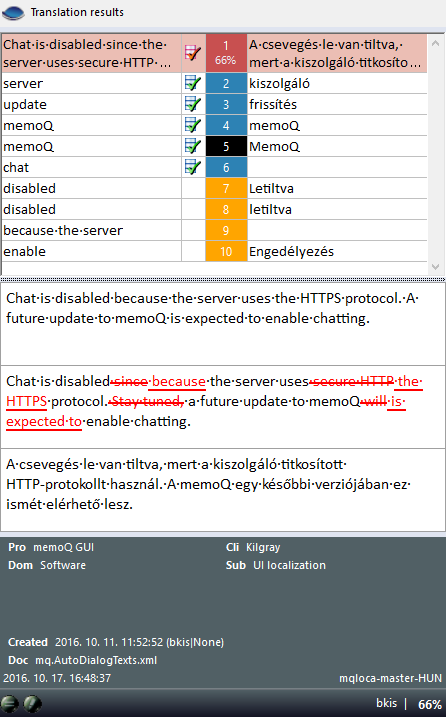
TC (変更履歴) 一致は、特殊な完全一致またはコンテキストマッチです:これらは、ソースドキュメントに変更履歴が含まれている場合に表示されます。これは、以前にドキュメントを翻訳したことがあり、同じドキュメントの編集済みバージョンを翻訳する必要がある場合に使用できます。変更はすべてマークされているので、memoQは編集前のテキストを知っています。memoQは編集前に、すべての変更が拒否されたかのようにテキストを検索し、一致するものがあればそれを返します。TC一致は、ソースセグメントの未編集バージョンに対する完全一致です。
変更履歴 (TC) 一致
- 高ファジーマッチ:マッチ率は95~99%です。テキストはドキュメントとリソースで同じですが、数字、句読点、タグ、またはスペースに違いがあります。
- 中ファジーマッチ 1:マッチ率は85~94%です。平均長セグメント (約10ワード) では、通常、ドキュメントとリソースで1ワード程度の違いがあります。
- 中ファジーマッチ 2:マッチ率は75~84%です。平均長セグメント (約10ワード) では、通常、ドキュメントとリソースで2ワード程度の違いがあります。
- 低ファジーマッチ:マッチ率は50~74%です。通常、この差異は大きすぎます。ソースセグメントが非常に短い (6ワード未満) 場合を除き、このマッチは役に立ちません。短いセグメントでは、程よいマッチがが低いマッチ率になることがあります。
用語ベースからの候補は青色で表示されます。memoQはソースセル内の各単語およびフレーズをチェックし、プロジェクトの用語ベースで見つかった各単語とフレーズに対して提案を行います。
「青色」(用語ベースのような) マッチには、次の3種類があります:
-
 - この一致は、通常の用語ベースからのものです。多くの環境では、これが信頼できるソースと見なされます。
- この一致は、通常の用語ベースからのものです。多くの環境では、これが信頼できるソースと見なされます。 -
 - この一致は、用語抽出セッションで承諾されたエントリからのものです。
- この一致は、用語抽出セッションで承諾されたエントリからのものです。 -
 - この一致は、外部用語サービスからのものです。詳細については、オプションの用語集プラグインペインのセクションを参照してください。
- この一致は、外部用語サービスからのものです。詳細については、オプションの用語集プラグインペインのセクションを参照してください。
結果リストで用語ベースエントリを選択するとリストの下にエントリの詳細がフォーマットされたレイアウトで表示されます:
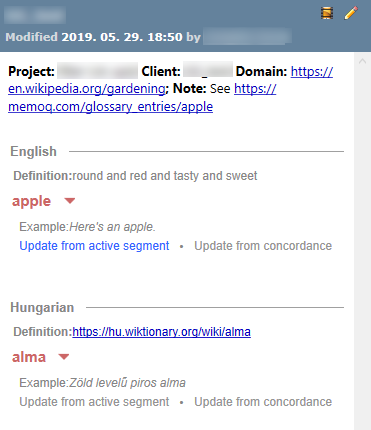
- プロジェクト言語の用語のみが表示され、ソース言語の用語の後にターゲット言語の用語が続きます。
- 翻訳結果リスト内で選択されている用語が展開され (ソースとターゲットの両方)、エントリ内の他のすべての用語は折りたたまれます。
用語の情報を展開または折りたたむには:用語の右側で、下向きまたは右向きの三角形をクリックします。
用語ベースエントリを編集するには:![]() アイコンをクリックします。用語ベースエントリの編集ウィンドウが開きます。
アイコンをクリックします。用語ベースエントリの編集ウィンドウが開きます。
用例として、現在のセグメントを用語エントリに追加するには:更新する言語で、アクティブなセグメントから更新をクリックします。
用例として、訳語検索ヒットを用語エントリに追加するには:翻訳エディタでフレーズを選択し、Ctrl+Kキーを押して追加する訳語検索ヒットを選択し、更新する言語でアクティブなセグメントから更新をクリックします。
用語情報をコピーするには:マウスを使用して、エントリレベル (上のイメージではプロジェクトおよびクライアント)、言語レベル (定義)、および用語レベル (例) のメタデータを選択します。Ctrl+Cを押すか、この領域の任意の場所を右クリックして、メニューから選択範囲のコピー、用語ペア情報をコピーまたはエントリ情報をコピーを選択します。
作業中のプロジェクトにQterm用語ベースがある場合は、Qterm用語ベースにエントリを追加したり、既存のエントリを編集することもできます (必要な権限がある場合)。
Qterm用語ベースからの一致は次のようになります:
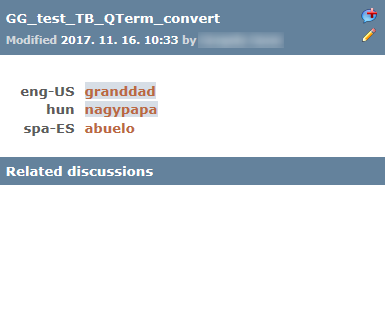

Qterm用語ベースエントリのディスカッションを開始することもできます:
-
ディスカッション
 アイコンをクリックします:ディスカッションを開始ダイアログが表示されます。
アイコンをクリックします:ディスカッションを開始ダイアログが表示されます。 -
概要、問題の説明、および推奨される解決策を入力して、ディスカッションを開始できます。エントリのディスカッションがすでに存在する場合は、用語の下の関連ディスカッションに一覧表示されます。
-
ディスカッションに投稿するには:ディスカッションの見出しをクリックします。トピックウィンドウが開きます。
Qtermのサーバーでディスカッションが無効になっている場合、またはディスカッションから除外されているグループのメンバーである場合は、ディスカッションを追加したり、ディスカッションに参加することはできません。
Qterm用語ベースエントリのディスカッションを開始することもできます。ディスカッション ![]() アイコンをクリックすると、ディスカッションを開始ダイアログが表示されます。このダイアログでは、概要、問題の説明、および推奨される解決策を入力して、ディスカッションを開始できます。エントリのディスカッションがすでに存在する場合は、用語の下の関連ディスカッションに一覧表示されます。ディスカッションに投稿するには、ディスカッションの見出しをクリックします:トピックウィンドウが開きます。
アイコンをクリックすると、ディスカッションを開始ダイアログが表示されます。このダイアログでは、概要、問題の説明、および推奨される解決策を入力して、ディスカッションを開始できます。エントリのディスカッションがすでに存在する場合は、用語の下の関連ディスカッションに一覧表示されます。ディスカッションに投稿するには、ディスカッションの見出しをクリックします:トピックウィンドウが開きます。
注意:Qtermのサーバーでディスカッションが無効になっている場合、またはディスカッションから除外されているグループのメンバーである場合は、ディスカッションを追加したり、ディスカッションに参加することはできません。
用語ベースのヒットが多い場合:memoQはそれらを順列したり、いくつかを非表示たりして、最も関連性のあるリストを表示します。デフォルトでは、ヒットはソーステキストの順番で表示されます。ソーステキストの一部が複数のヒットでカバーされている場合、長い方のマッチで短い方が非表示になります (目 ![]() アイコンをクリックすると、短い方も表示されます)。まったく同じソースの語句に対して複数のヒットがある場合、ヒットは用語ベースの優先順位とその詳細によってランク付けされます:2つの用語ベースのヒットが同じ用語ベースから来ているが、一方の用語ベースのヒットが他方の用語ベースよりもプロジェクトと共通点が多い場合、そのヒットが表示されます。詳細については:
アイコンをクリックすると、短い方も表示されます)。まったく同じソースの語句に対して複数のヒットがある場合、ヒットは用語ベースの優先順位とその詳細によってランク付けされます:2つの用語ベースのヒットが同じ用語ベースから来ているが、一方の用語ベースのヒットが他方の用語ベースよりもプロジェクトと共通点が多い場合、そのヒットが表示されます。詳細については:
使用できない用語は黒色で用語ベースから来ています。これらは、ソース言語のフレーズがどのように翻訳されてはならないかを示しています。これらの一致は翻訳に挿入できませんが、翻訳者に警告するために表示されます。使用できない用語を使用すると、QA警告が表示されます。
フラグメント検索候補は紫色です。memoQは、プロジェクトの翻訳メモリまたは用語ベースにある小さな部分から、ソースセグメントの翻訳をまとめようとします。
詳細については:フラグメント結合のトピックを参照してください。
フラグメント結合マッチのオン/オフを切り替えるには:オプションウィンドウの左側で、詳細ルックアップ設定をクリックします。フラグメントの結合設定タブをクリックします。
自動訳語検索 (または最長サブストリング訳語検索 - Longest Substring Concordance、LSC) の候補は明るいオレンジ色です。memoQは、訳語検索が見つけることのできる最も長い語句を検索しようとし、それに相当する語句を提供しようとします。memoQが翻訳を見つけた場合は、リストに表示されます。TMマッチと同様に、この翻訳をターゲットセルに挿入することができます。
翻訳がない場合:候補をダブルクリックすると訳語検索ウィンドウが開き、翻訳を検索して挿入できます。
自動訳語検索のオン/オフを切り替えるには:オプションウィンドウの左側で、詳細ルックアップ設定をクリックします。
MT 訳語検索候補 (選択したフレーズの機械翻訳バージョン) は黄色です。これらの翻訳は、用語ベースの一致と同様にターゲットセルに挿入できます。つまり、既にそこにあるコンテンツを上書きすることはありません。
翻訳対象外アイテムは灰色で表示されます。これらは翻訳してはなりません。これらの候補を使用すると、ターゲットセルにまったく同じ単語または語句を挿入できます。
自動翻訳ルールの結果は緑色です。自動翻訳ルールは、ソースセグメントでmemoQが検索するパターンです。言語要素の中には、さまざまに組み合わせがあるために単純に一覧化できないけれども、特別なルールを使用して記述可能なものがあります。これらの要素には、日付、測定単位、通貨の換算などが含まれています。
中央部分:
翻訳結果ペインでライブ文書マッチまたは翻訳メモリマッチを選択すると、リストのすぐ下にある3つのボックスに詳細が表示されます。
これらの比較ボックスが表示されます:
- 1番目は、現在のソースセグメント;
- 2番目は、選択した候補のソーステキスト;
- 3番目は、選択した提案のターゲットテキストです。
2つの表示から選択できます。最初のTM結果を受信すると、通知が表示されます:
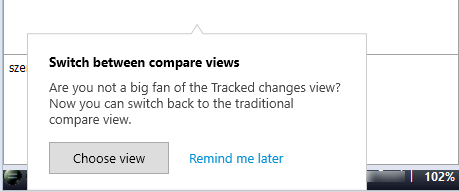
後で選択するには:後で通知するをクリックします。memoQは、変更履歴ビューを使用し続けます。同じ通知が後で表示されます。
ここで選択するには:ビューの選択をクリックします。異なるビューを比較するウィンドウが開きます (以下を参照)。
選択した内容を変更する場合:
または:
-
memoQの左上のクイックアクセスツールバーで、オプション
 アイコンをクリックします。
アイコンをクリックします。 -
検索結果タブの比較ボックスで、変更履歴ビューまたは従来の比較ビューを選択します。
違いを確認するには:異なるビューを比較するリンクをクリックします。
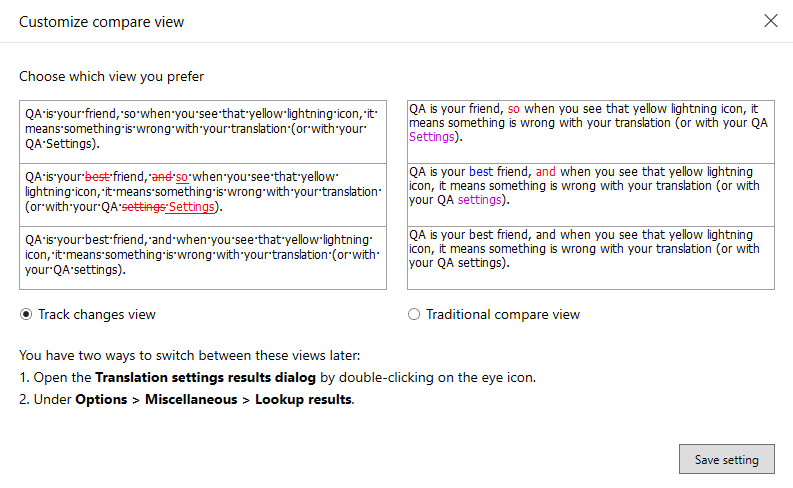
変更履歴ビュー:
2つのソースセグメントの差が変更履歴として、テキストに表示される変更履歴と同じ方法で表示されます。
翻訳メモリの一致が現在のソースセグメントで修正されたかのような形で、変更が2番目のボックスでハイライト表示されます。これは次のことを意味します:
- 現在のソースセグメントにある新しい部分が挿入された状態で表示されます;
- 一致に表示される古い部分は、削除されたものとして表示されます。
従来の比較ビュー:
memoQでは、色コードを使用して翻訳結果とソーステキストの違いを強調します:
- 黒:ソースセグメントとヒットセグメントの同一部分
- 赤:1番目と2番目の比較ボックスの違いハイライト表示された部分を確認し、ソーステキストへの翻訳候補を調整します。
- 青:その候補では、単語が不足しています。翻訳に追加します。
マークアップの色を変更するには:必要に応じて、オプション - 表示ペインの比較ボックスタブを使用して色を変更します。
フォントやフォントの色を変更するには:オプション - 表示ペインの翻訳グリッドタブを使用して色やフォントを変更します。この記事には、通常の設定に関する情報が記載されています。通常の設定を変更すると、ご使用のmemoQに対してこの説明が合わなくなる場合があります。
下部:
3つの比較ボックスの下で、memoQは選択した候補に関する説明フィールドを表示します。
翻訳メモリエントリの場合は、次のようになります:
- タイトル、またはサブジェクト名
- ドメイン、またはドメイン名
- プロジェクト、またはプロジェクト識別子
- クライアントまたは翻訳メモリに関連するクライアント名
- エントリが格納されている翻訳メモリまたはライブ文書資料の名前。
- エントリを作成または最後に変更したユーザーのユーザー名。
- エントリが作成された日時または最後に変更された日時。
- 候補のマッチ率。
- 翻訳メモリに保存されているユーザーの役割:このエントリは翻訳者、レビュー担当者1、またはレビュー担当者2によって確定されましたか?
上部のリストで翻訳メモリの一致を選択すると、翻訳結果ペインの下部に2組の小さな「ランプ」が表示されます:
![]()
左側の2つのランプは、現在選択されているエントリが自動整合の結果  であるか、翻訳エディタのソーステキストセグメントが編集されて翻訳メモリに再送信されたか
であるか、翻訳エディタのソーステキストセグメントが編集されて翻訳メモリに再送信されたか  を示します。たとえば、ソースセグメントにタイプミスがある場合は、セグメントエントリを右クリックし、ソースの編集を選択します。エントリのソースを修正し、Ctrl+Enterをクリックして変更を保存します。これは、翻訳グリッドでこのセグメントに戻ったときに インジケータが表示される場合です。
を示します。たとえば、ソースセグメントにタイプミスがある場合は、セグメントエントリを右クリックし、ソースの編集を選択します。エントリのソースを修正し、Ctrl+Enterをクリックして変更を保存します。これは、翻訳グリッドでこのセグメントに戻ったときに インジケータが表示される場合です。
選択した翻訳メモリの一致率が95~101%の場合は、他に6つのアイコンが表示されます。これらのアイコンが点灯している場合は、現在のソースセグメントとTMエントリのソーステキストとのわずかな違いを示します (例:以前は太字でフォーマットされていたセグメントが、現在は斜体でフォーマットされています):
-
 - 現在のソースセルのスペースの数がTMエントリのスペースの数より少ない、または多い
- 現在のソースセルのスペースの数がTMエントリのスペースの数より少ない、または多い -
 - 句読点が異なる
- 句読点が異なる -
 - 大文字 / 小文字が異なる
- 大文字 / 小文字が異なる -
 - 太字/斜体/下線の書式が異なる
- 太字/斜体/下線の書式が異なる -
 - タグが異なる
- タグが異なる -
 - 数字やエンティティが異なる
- 数字やエンティティが異なる
ランプがカラーで点灯している場合は、このような違いを手動で修正する必要があります。グレーで点灯している場合は、memoQが違いを検出したことを示していますが、それを修正したことになります。たとえば、memoQでは、ターゲットセグメント全体に太字の書式を適用したり、ソーステキストの番号と一致するように番号を置き換えたりできます。
用語については、整合済みラベルとエントリのマッチ率以外は同じ情報が表示されます。
数字やエンティティの違いを点灯させるには、デフォルトの翻訳メモリ設定を変更する必要があります。プロジェクトホームから、設定を選択し、翻訳メモリ設定タブをクリックします。デフォルト設定のクローンを作成します。次に編集をクリックし、あいまい一致の調整チェックボックスをオフにします。これ以降、memoQは数字を調整せずにこのランプを点灯させます。
詳細情報
翻訳結果ペインの上部にある閉じた目  アイコンは、翻訳メモリ、ライブ文書資料、および用語ベースから隠された候補があることを示しています。通常、memoQはこのように動作します。
アイコンは、翻訳メモリ、ライブ文書資料、および用語ベースから隠された候補があることを示しています。通常、memoQはこのように動作します。
すべての提案を取得するには、このアイコンをクリックします。またはCtrl+Shift+Dを押します。開いた目: になります。
になります。
非表示の候補を確認 (および選択) するには、翻訳結果設定ウィンドウの記事を参照してください。
長いソースセグメントがあり、翻訳メモリから一致するものがない場合、memoQはプロジェクトに割り当てられた翻訳メモリおよび用語ベースでこのセグメントの小さな部分を探すことができます。翻訳メモリまたは用語ベースに短いセグメントが(翻訳と一緒に)保存されている場合には、memoQはより長いソースセグメントの短い部分(フラグメント)を検索し、ターゲットセグメント内にその訳文を挿入することができます。これは自動的に行われます:セグメントに移動し、memoQが翻訳メモリと用語ベースを検索するとき、「パッチワーク」マッチ、あるいはもしあればフラグメントマッチがヒットリストに自動的に現れます。
通常、フラグメント一致は、ヒットリストに紫色で表示されます。Ctrl+下キーを押すと、それらに移動できます。Ctrl+Spaceキーを押して挿入します。または、リスト内の紫色の部分をダブルクリックするか、Ctrlキーを押しながら数字キーを押します(ヒットが複数ある場合には最初の9ヒット目までに数字が付いています)。
以下のセグメントを以前に翻訳したことがあるとします。

... そして、用語ベースに以下のエントリがあるとします。
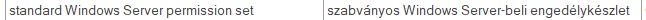
そして、別の文書で以下のセグメントを翻訳する必要があるとします。

上のセグメントに対する翻訳を入力するには、ターゲットセグメントにカーソルを置くだけです。memoQは翻訳メモリ内の2つの小さいセグメントおよびセグメントの最後の用語に対する用語ベースエントリを自動で検知します。結合された翻訳がヒットリストに自動で表示されます。
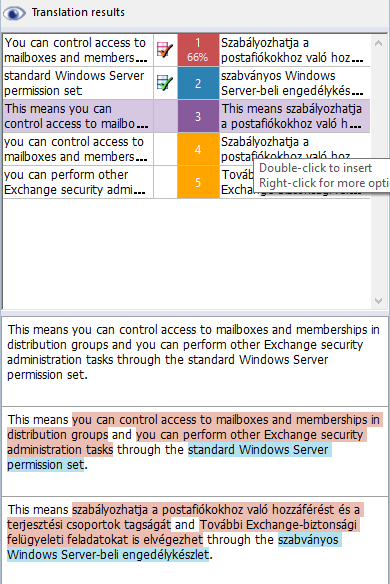
提案された翻訳を挿入するには、Ctrl+3を押すか、Ctrl+矢印キーを使用して候補まで移動し、Ctrl+空白を押します。
memoQがフラグメントから翻訳を結合する際、セグメントの最初からできるだけ長いフラグメントを常に検索します。フラグメントが見つかると、memoQは前のフラグメントの終了位置から再度できるだけ長いフラグメントを検索していきます。セグメントの最初(または検索位置)からフラグメントが見つからない場合には、次の単語の最初からフラグメントを検索します。次の検索でも見つからない場合には、memoQはフラグメントが見つかるまで、もしくはセグメントの最後に到達するまで、1単語ずつ移動していきます。
フラグメント検索中、memoQはプロジェクトに含まれている翻訳メモリと用語ベースを検索します。翻訳メモリを検索する際には、memoQは翻訳メモリと完全一致するもののみを使用します。翻訳メモリ内であいまい(ファジー)一致のフラグメントは検索されません。用語ベースを検索する際には、memoQは接頭辞の一致を使用しません。
フラグメントから翻訳を結合する際には、memoQは常にソースセグメント全体をカバーします。フラグメント検索の際には、memoQは一語ずつ行います。フラグメントマッチで単語が見つからない(つまり、memoQは単語をスキップし次の単語の検索に移動した)場合には、ソース言語の単語が代わりに挿入されます。上の例を参照:いくつかの英文テキストがまだ提案に残っています。これは、memoQがこれらの単語全体を含むエントリを用語ベースや翻訳メモリで検知できなかったという意味です。
ほとんどの場合、フラグメント結合はソーステキスト内の用語を置き換えます。同じソース言語の単語に対して2つ以上の用語ベースヒットがある場合、memoQは1つを選択する必要があります。そのため、memoQは用語ベースヒットを採点し、スコアの高いほうを採用します。
もちろん、より長いヒットは常により強いですが、2つ以上のヒットが同等に長い場合、memoQはそれらをより詳細に見る必要があります。
一方では、用語ベース間に優先順位を設定できます。用語がより重要な用語ベースに由来する場合、その用語が勝利します。
他方では、同じ用語ベースから来た場合、memoQが判断する必要があります。
このプロセスは、ランキングがオンになっている場合に機能します。ランキングをオンにするには、翻訳結果設定ダイアログボックスを開き、ランクおよびメタデータ別に用語ベースヒットを並べるチェックボックスをオンにします。
そしてmemoQは、用語ベースヒットがプロジェクトとどの程度共通しているかをチェックします。1つの用語ベースヒットがプロジェクトに一致する2つの詳細を持ち、別の用語ベースヒットが3つの詳細を持つ場合、3つの詳細を持つヒットが勝利します。
両方の用語ベースヒットがプロジェクトに一致する同じ数の詳細を持つ場合、memoQはこれらの詳細の重要性をチェックします。最も重要なものから最も重要でないものまで、重要な順序は次のとおりです:
- プロジェクト名
- クライアント名
- サブジェクト
- ドメイン
たとえば、ある用語ベースヒットに一致するクライアント名フィールドがあり、別の用語ベースヒットに同じサブジェクトがある場合、クライアント名がサブジェクトよりも重要であるため、最初の用語ベースヒットが勝利します。
memoQがテキスト中に用語を見つけると、それは候補のリストに現れます。ただし、次の例では、翻訳メモリの一致と用語ベースのヒットの両方がリソース (つまり、翻訳メモリと用語ベース) から取得され、memoQはそれらを組み合わせます。
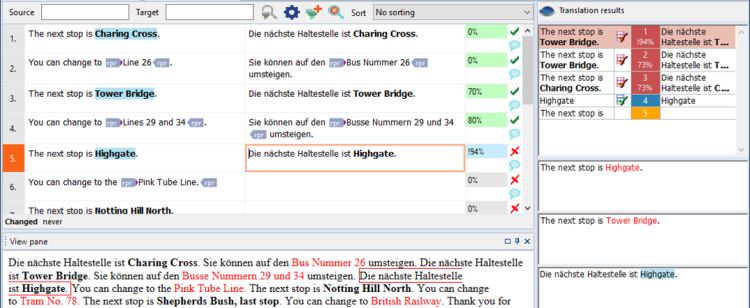
memoQが完全な翻訳を挿入したことに注目してください。翻訳メモリの一致が「The next stop is Tower Bridge」であったのに、なぜこうなりますか?
ソーステキストと翻訳メモリ一致の違いは、駅名です。ソーステキストは「Highgate」、翻訳では「Tower Bridge」です。どちらの名前も、用語ベースにありました。memoQは「Tower Bridge」の翻訳を保存していましたが、すでに「Highgate」の翻訳も知っていたので、簡単に新しい名前に置き換えることができました。
これを、memoQが翻訳にパッチを当てると言います。また、memoQはパッチされた翻訳に高いスコアを与えますが、感嘆符 (! - セグメントの横の青いステータスボックスを参照) でマークします。
これを機能させるには、オプションウィンドウを開きます。その他を選択します。検索結果タブをクリックします。あいまいTM一致のパッチチェックボックスをオンにします。
詳細については:オプションウィンドウのセクションを参照してください。
memoQでは、パッチされた一致が、マッチ率の前に感嘆符が付いて表示されます:!93%。翻訳結果ペインの下部に、2つのマッチ率が表示されます:73%->93%。もともと73%だった一致が、memoQは93%に改善することができました。
memoQはソースセルの書式設定も使用します。用語が太字で表示されている場合は、ターゲット用語も太字で表示されます。
memoQはファジーマッチの各差を調べます。したがって、理論的にはすべてのパッチを適用できますが、実際には通常1つか2つの違いがパッチされます。これは、マッチパッチが高いマッチスコアを必要とし、参照資料のヒット数が少ないために起こります。機械翻訳によるパッチ適用にもいくつかの制限があります。
-
memoQは、1つのMTサービス内でフレーズを1回だけ検索し、最初に返された翻訳だけを受け取ります。翻訳が翻訳メモリのファジーマッチの翻訳と異なる場合、memoQはそのフレーズにパッチを適用できません。
-
memoQは3文字以下の単語を検索しません。
ターゲット言語に応じて、末尾または単語の形式を調整する必要があります。グリッドでは、パッチされた一致は水色で示されます。これは、「通常の」前翻訳されたセグメントとは異なります。
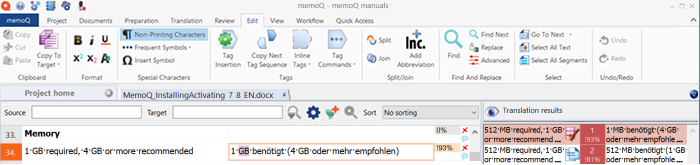
前翻訳中にパッチが適用されない:memoQは前翻訳の段階では一致を修正しません。
数字またはタグをパッチしない:それは翻訳メモリ自体のタスクです。マッチパッチはテキストの違いのみに機能します。
パッチを適用した場合、ペナルティが発生します:パッチを当てた一致は完全 (正確) かもしれないが、memoQはペナルティを適用します。パッチを当てたファジーマッチのマッチ率は94%を超えることはありません。
例1:
英語のソーステキスト:Chocolate was the best-selling commodity in the last summer.
リソース:
上記の文は、正しいドイツ語翻訳文と共にTMに保存されています:Schokolade war die meist verkaufteste Ware im letzten Sommer.
用語ベースに次の用語が含まれています:ice cream = Eiscreme
ここで、この英語を含むソーステキストを受け取ります:
Ice cream was the best-selling commodity in the last summer.
ドイツ語ターゲット:Eiscreme war die meist verkaufte Ware im letzten Sommer.
例2:
英語のソーステキスト:Chocolate was the best-selling commodity in the last hot summer.
リソース:
上記の文は、正しいドイツ語翻訳文と共にTMに保存されています:Schokolade war die meist verkaufte Ware im letzten heißen Sommer.
用語ベースに次の用語が含まれています:ice cream = Eiscreme そして cold = kalten
ここで、この英語を含むソーステキストを受け取ります:
Ice cream was the best-selling commodity in the last cold summer.
ドイツ語ターゲット:Eiscreme war die meist verkaufte Ware im letzten kalten Sommer.
機械翻訳サービスにアクセスできる場合は、このサービスを使用して、TMから送られてくるファジーマッチをパッチすることもできます。
- 機械翻訳設定を編集ウィンドウを開きます。
- 必要に応じて、リスト内のMTサービスの行をクリックし、プラグインを設定します。
- 設定タブで、マッチパッチドロップダウンからサービスを選択します。
- OK(O)をクリックします。
用語ベースまたはTM結果を使用してファジーマッチをパッチできない場合、マッチパッチは選択したMTサービスをパッチに使用します。