Regular expressions
Regular expressions are a powerful means for finding character sequences in text. In memoQ, they are used to define segmentation rules, auto-translation rules, or rules for the Regex tagger. You can also use regular expressions in Find and replace, and in the filtering controls in the translation editor.
Finding character sequences is a familiar task to everyone who has used a word processor or text editor before. The Find or Search dialog serves this purpose – if you search for 'cat', your editor will highlight words (or parts of words) such as 'cat', 'cats', or even 'sophisticated'.
Regular expressions, however, provide a lot more freedom to tell the computer what you are looking for. You can identify sequences such as a letter 'a', followed by two or three letters 'c'; a number of letters followed by one or more digits; or either of the words 'cat', 'dog' or 'mouse' – and much more. After reading through this page and experimenting with the examples, you'll know exactly how.
Note: The term regular expression comes from the mathematical theory on which this pattern matching method is based. It is often abbreviated as regexp or regex – here we'll use regex, or in the plural, regexes.
Literal and Meta
In a word processor's old-school Find function every character is interpreted literally. If you search for 'Yes? No...' it will highlight 'Yes? No...' – or nothing if these characters do not appear in the text. In a regex, however, some characters have special meaning – these are called meta characters. The most important meta characters are:
Confusing? This table is only meant as a short summary and reference – the meaning of all of these expressions will be clarified in the sections below.
For now, let's focus on the first one, the dot. In a regex it means 'any character may stand here'. So the expression 'No...' in a regex will match any of the following:
- Notes
- Notte
- No...
- No&%X
So what do you need to write in a regex to match precisely 'No...' and no other text? To use a character that has a special meaning, you must 'escape' it: that is, precede with a backslash. Thus, 'No\.\.\.' will match exactly 'No...' and nothing else.
How to test regular expressions
In memoQ, regular expressions now work in Find and replace, too. You can try a regular expression by opening a document for translation, pressing Ctrl+F. Type your regular expression in the Find what box, and click Find Next.
Alternatively, you can filter your document in the translation editor - using regular expressions. Just above the translation grid, check the check box with the Use regular expressions ![]() icon, and then type the regular expression in the filter box above the source or the target segments. Press Enter: memoQ will show those segments that match your regular expression. For example, here is how you filter for segments that include numbers, followed by a dot:
icon, and then type the regular expression in the filter box above the source or the target segments. Press Enter: memoQ will show those segments that match your regular expression. For example, here is how you filter for segments that include numbers, followed by a dot:
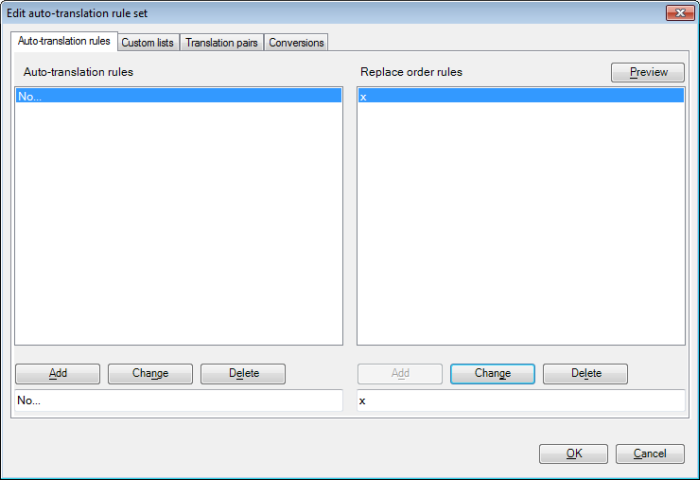
If you need more detailed feedback from memoQ as you learn regular expressions, here's a trick to 'abuse' auto-translation rules for experimenting. Create a test project, and in the Settings pane of Project home click the Auto-translation rules tab. In the dialog that appears, delete every rule already there, and enter a rule of your own. For that rule, also add a replace order rule so that you see the dialog fields filled as shown below. (What a replace order rule means and why you need it here will be explained below.)
Now click Preview, type the text shown below in the Before auto-translation box, and click the Preview button. You will see the following:
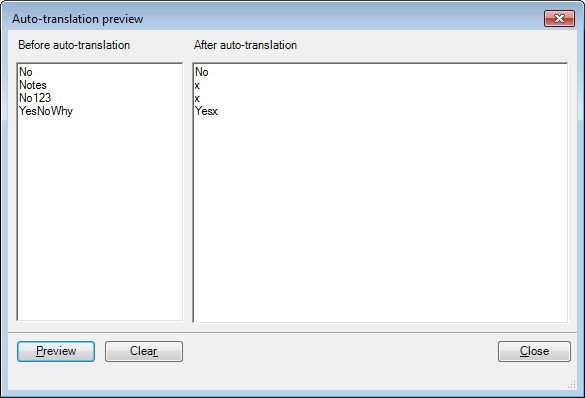
The 'x' in the Replace order rules field tells memoQ to replace text which the specified regex matches with a letter 'x' – that's how you know that your regex is working in this experiment. In the Auto translation preview dialog you can see exactly which parts of the text you provided are replaced by an 'x', allowing you to test your regex.
Character classes
Now that we've covered the dot and know how to experiment with new regexes, let's move on to some more serious expressions. Brackets in regexes allow you to specify a set of characters, or a character class. '[ab][01]' will match two-character-long sequences where the first character is either an 'a' or a 'b', and the second is either a '0' or a '1'. This yields 4 possible matches: 'a0', 'b0', 'a1', 'b1'.
Character classes can be used to express things like 'a digit followed by a comma or an exclamation mark' – which could be expressed as '[0123456789][,!]'. This, however, would be a very inconvenient thing to write. Regexes know better: you can specify a range of characters by writing '[0-9][,!]', which is exactly the same as the previous expression.
Note: Can you use ranges to say 'match an alphabetical letter'? Yes and no. A typical solution to do this used to be '[a-z]', which matches any of the letters between a and z. Keep in mind, however, that memoQ works with many different languages which often have special characters in their alphabet. The Icelandic letter 'đ', for instance, is definitely not in the range a-z. Therefore memoQ uses a special extension to deal with alphabetical letters, which will be described below.
Also, keep in mind that all letters in memoQ regexes are interpreted in a case-sensitive way. Thus, '[a-z]' will match 'f' but not 'F'.
Besides specifying what you want to match, you can also use character classes to specify what not to match. The regex '[^0a].' will match an infinite number of two-character sequences, so long as the first character is not '0' or 'a'.
Escape sequences
As you saw above, you can specify the original meaning of the special meta characters by preceding them with a backslash ('\'), or escaping them. There are also other practical escape sequences available. The ones most important for the purposes regexes are used for in memoQ are:
|
Sequence |
Description |
|
\s |
Whitespace: space, tab or newline |
|
\S |
Anything but whitespace |
|
\t |
Tab |
|
\n |
Newline |
|
\d |
Digit (between 0 and 9) |
|
\D |
Anything but digits |
|
\w |
Alphanumeric character and underscore |
|
\W |
Anything but alphanumeric characters |
Quantifiers
Now that you've learned to specify a set of alternative characters to match at a given position, it's time to move down the road and tell memoQ how many characters to match. The special characters '*' and '+', and the expression {num} are used for this purpose.
- The regex 'x+' will match a sequence of characters which consists of one or more 'x's – thus, 'x', 'xx', 'xxx' and so on.
- The regex 'x{3}' will match a sequence of characters which consists of exactly 3 'x's – thus, 'xxx', but not 'x' or 'xx'. If the text is 'xxxx', the regex will match the first 3 'x's and ignore the fourth. Visually: 'xxxx'. For a parallel, remember that the traditional Find dialog will find the word 'cat' in 'cats'.
- You can use the {num} quantifier in a special flavor by specifying a minimum or maximum value (or both). Thus, 'x{3,5}' will match between 3 and 5 'x's; 'x{3,}' will match any sequence with at least 3 'x's; and 'x{,5}' will match any sequence with at most 5 'x's.
- Perhaps the funniest of the quantifiers is the asterisk ('*'). Its meaning is 'match zero or more of the given character'. What on earth is that good for? Well, you can say things like "match the letter 'T' preceded by some 'a's – or maybe none". The corresponding regex is 'a*T', which will match 'T', 'aT', 'aaT' and so on.
- A little less exciting but no less useful quantifier is the question mark. Its meaning is to match zero or one of the character in front of it. Thus, 'ax?y' will match 'ay' and 'axy', but not 'axxy'.
If you think quantifiers are fun, it's time to combine them with character sets. Just as after characters, you can write quantifiers after character sets. '[0-9]+%' will match a sequence of digits followed by a percentage sign; for instance, '1%' or '99%', but not '10a%'.
Groups and Alternatives
Having covered character sets and quantifiers, there are only two standard regex features left to explore: groups and alternatives.
Using the pipe ('|') symbol you can join several smaller regexes to say 'match either this, that or the other thing'. The regex 'EUR|USD|GBP' will match any of these words, and only these.
When working with alternatives you mostly need to group them together using parentheses to get the desired results. Let's say you want a regex that matches any of these expressions: 'EUR 15 million', 'USD 37 million' and 'GBP 5 million'. As a first try, you might be inclined to write 'EUR|USD|GBP \d{1,} million'. This, however, will not do, as it only matches the following strings: 'EUR', 'USD' and 'GBP [any natural number] million'. You need to group your alternatives together in the regex: '(EUR|USD|GBP) \d{1,} million', where 'EUR|USD|GBP' can be either 'EUR' or 'USD' or 'GBP' and '\d{1,}' can be any natural number starting from zero.
Replacing and reordering
For the purposes of segmentation, memoQ only uses regexes to match patterns in the translation document's text. For auto-translation rules it also makes use of another powerful regex feature that has to do with groups: replacing and reordering parts of the matched text.
- Replacing a matched text with a single string:
You already saw a possible use for replacement in the How to test section of this page. There we defined the rather simplistic Replace order rule of 'x' to replace a regex match with the letter 'x' for the purposes of testing.
- Reordering and/or replacing parts of a matched text:
Here you need to group all those parts of the regex in pair of parentheses that you want to reference. The match enclosed in every pair of parentheses is remembered by memoQ and assigned a number starting with 1. When writing the replace order rule you can reference these remembered substrings by '$1', '$2' etc., in the order of the opening parenthesis' appearance in the regex.
Using the previous regex example, you have to put also '\d{1,}' in parentheses to make reordering of these currencies and their values possible: '(EUR|USD|GBP) (\d{1,}) million'. In the replace order rule you can reference 'EUR|USD|GBP' by '$1', and '\d{1,}' by '$2'. So if you want to change their order, the replace order rule could be '$2 Millionen $1'.
memoQ extensions
If you want to find tags with regular expressions, you can use three special escape sequences to match them:
- \tag will match any tag
- \itag will match an inline tag (one that appears in a heptagon or a hexagon, like this:
- \mtag will match a memoQ tag (one that appears in {curly brackets} in the text)
Because tags are usually joined with the text that precedes or follows them, it is best to put them in parentheses '()' when you are looking for a combination of tags and text. Example: '(\itag)int' will match inline tags (no matter whether opening, closing, or empty) that are followed by words like 'integrated', 'interesting', 'intentional'.
Custom lists
For the purposes of segmentation and defining auto-translation rules it is often useful to work with lists of words – abbreviations, the names of months, currencies etc. In theory it would be possible to list these words grouped together as alternatives in the regular expressions, as you saw in the preceding section. However, doing so would result in very complicated and hard to maintain regexes. memoQ therefore introduces a special extension to regular expressions: custom lists.
Lists of words used in regular expressions can be defined in the Custom lists tab of the segmentation rules dialog or of the auto-translation rules dialog, or in the Translation pairs tab of the auto-translatables dialog.
- The custom lists in the Custom lists tab of the segmentation rules dialog should contain characters, abbreviations that are important for segmentation (e.g. '.', '!', 'e.g.').
- The custom lists in the Custom lists tab of the auto-translatables dialog should contain words that have the same source and target form (e.g. '€', '$').
- The custom lists in the Translation pairs tab of the auto-translatables dialog should contain source words with their target equivalents (e.g. In English-German projects 'January' should be translated as 'Januar', 'February' as 'Februar' etc.).
The name of a custom list must always start and end with a hash mark ('#'). The words that make up a custom list are always interpreted as plain text, i.e. no characters are treated as meta characters with a special meaning.
Note: For segmentation rules memoQ defines one more special item: '#!#'. This extension does not influence regex matching in any way. Instead, it tells memoQ to introduce a segment break at the given location if the expression matches text in the imported document.
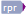
Example for using custom lists of the Custom lists tab of the Auto-translation rules dialog.
If you want memoQ to offer you '15 Millionen EUR' in the Translation results pane for every occurrence of 'EUR 15 million' and '37 Millionen USD' for 'USD 37 million'. Create a custom list labeled '#currency#' in the Custom lists tab containing 'EUR', 'USD' and 'GBP'.
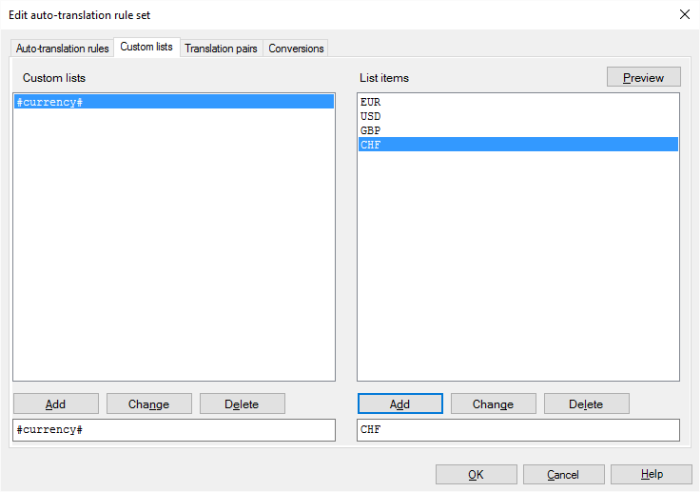
Now create the following Regex '(#currency#) (\d{1,}) million' (equivalent with '(EUR|USD|GBP) (\d{1,}) million') for which the replace order rule could be '$2 Millionen $1'. The preview of the above Regex and replace order rule will yield the following result:
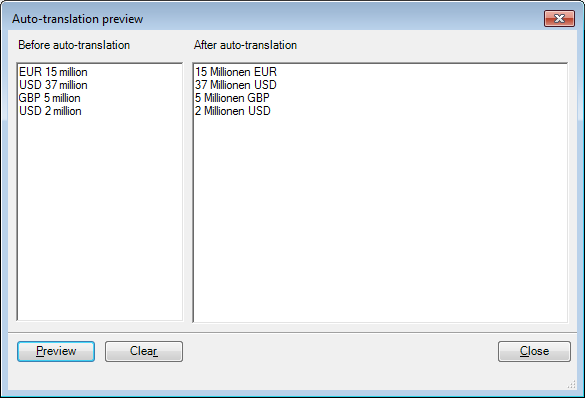
Translation pairs
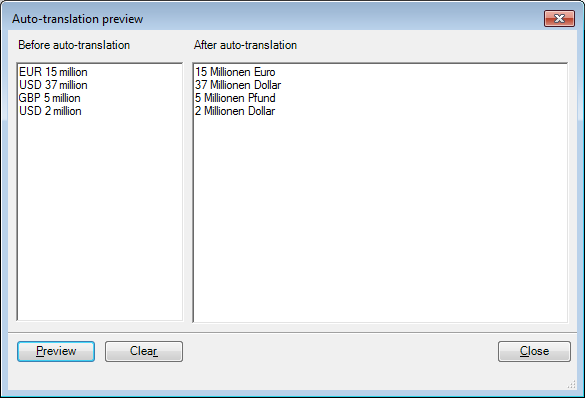
If you want memoQ to offer you '15 Millionen Euro' in the Translation results pane for every occurrence of 'EUR 15 million' and '37 Millionen Dollar' for 'USD 37 million'. Create a custom list labeled '#currency2#' in the Translation pairs tab containing the following translation pairs: 'EUR' – 'Euro', 'USD' – 'Dollar' and 'GBP' – 'Pfund'.
Note: The name for the Translation pairs list must be a different one than for the Custom lists.
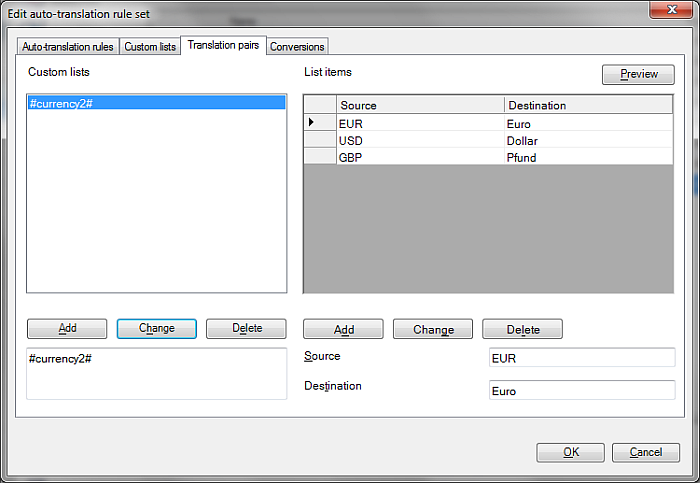
Now create the following Regex '(#currency2#) (\d{1,}) million' for which the replace order rule could be '$2 Millionen $1'. The preview of the above Regex and replace order rule will yield the following result: