Statistiken
Im Fenster Statistiken können Sie die Wörter, Segmente und Zeichen im Projekt oder in den ausgewählten Dokumenten zählen. Sie können sie anhand der Translation Memories und der LiveDocs-Korpora analysieren und so feststellen, wie groß der tatsächliche Arbeitsaufwand unter Berücksichtigung der vorhandenen Ressourcen ist.
Mit dem Befehl Statistiken finden Sie heraus, wie viel Sie für das Projekt in Rechnung stellen können – wiederum auf Basis der Analyse.
Dies ist die manuelle Vorgehensweise: Im Rahmen von Projektvorlagen kann memoQ Analyseberichte automatisch ausführen.
Dies ist die angepasste Vorgehensweise: In der Projektverwaltung können Sie schnelle Analyseberichte für das gesamte Projekt, mit weniger Einstellungen, erstellen.
Navigation
- Öffnen Sie ein Projekt. Oder erstellen Sie ein Projekt, und importieren Sie Dokumente.
- Sie können ein Dokument zur Übersetzung öffnen – wenn Sie einen Teil eines Dokuments analysieren müssen.
- Klicken Sie auf der Registerkarte Dokumente des Menübands auf Statistiken.
Das Fenster Statistiken wird angezeigt.
Erfordert memoQ project manager: Zum Verwalten von Online-Projekten benötigen Sie die Edition project manager von memoQ.
Sie müssen Projekt-Manager oder Administrator sein: Sie können Online-Projekte nur verwalten, wenn Sie Mitglied der Gruppe Projektmanager oder Administratoren auf dem memoQ-Server sind oder wenn Ihnen die Rolle Projektmanager im Projekt zugewiesen wurde.
- Öffnen Sie ein Online-Projekt zur Verwaltung. Oder erstellen Sie ein Online-Projekt und importieren Sie Dokumente.
- Wählen Sie im Fenster memoQ-Online-Projekt die Option Übersetzungen aus.
- Klicken Sie unter der Dokumentenliste auf Statistiken.
Das Fenster Statistiken wird angezeigt.
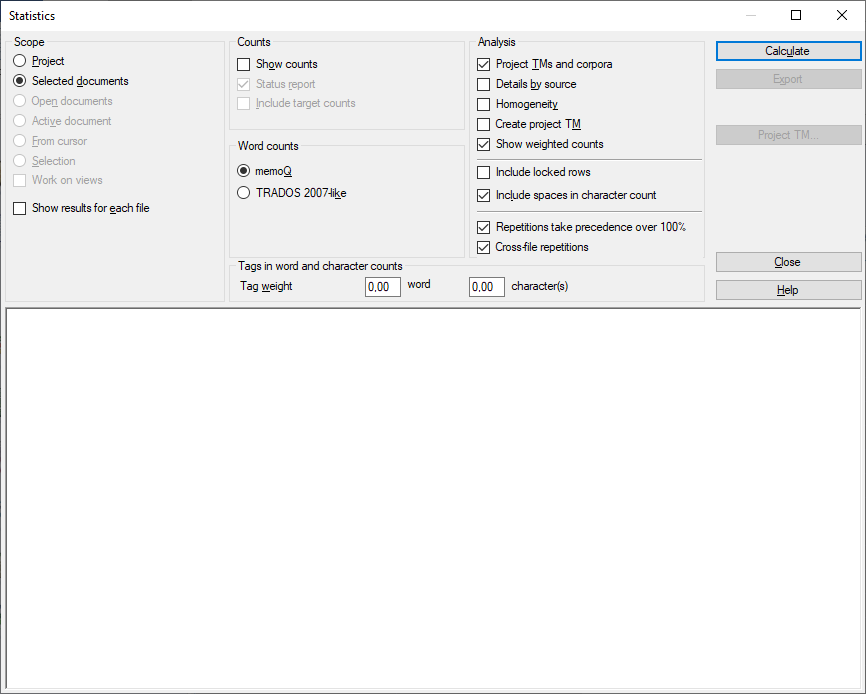
Möglichkeiten
Mit einem Bereich wird festgelegt, welche Dokumente einbezogen werden sollen. Folgende Optionen stehen zur Verfügung – wählen Sie ein Optionsfeld aus:
- Projekt: Es werden alle Segmente in allen Dokumenten des aktuellen Projekts analysiert. Wenn das Projekt zwei oder mehr Zielsprachen aufweist, werden die Segmente in jeder Zielsprache überprüft.
- Aktives Dokument: Analysiert alle Segmente im aktiven Dokument. Das aktive Dokument ist das Dokument, das im Übersetzungseditor angezeigt wird. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
- Ausgewählte Dokumente: Analysiert alle Segmente in den ausgewählten Dokumenten Diese Einstellung können Sie nur auswählen, wenn Sie mehrere Dokumente im Bereich Übersetzungen der Projektzentrale markieren. Die Option kann nicht verwendet werden, wenn der Übersetzungseditor geöffnet ist.
- Ab Cursorposition: Die Segmente unterhalb der aktuellen Position im aktiven Dokument werden analysiert. Das aktive Dokument ist das Dokument, das im Übersetzungseditor angezeigt wird. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
- Geöffnete Dokumente: Alle Segmente in allen als Registerkarten des Übersetzungseditors geöffneten Dokumenten werden analysiert.
- Auswahl: Die ausgewählten Segmente im aktiven Dokument werden analysiert. Das aktive Dokument ist das Dokument, das im Übersetzungseditor angezeigt wird. Diese Einstellung können Sie nur auswählen, wenn Sie gerade an einem Dokument im Übersetzungseditor arbeiten.
- Kontrollkästchen An Ansichten arbeiten: Aktivieren Sie dieses Kontrollkästchen, wenn die Segmente in den Ansichten im aktuellen Projekt verarbeitet werden sollen. Diese Option können Sie nur auswählen, wenn mindestens eine Ansicht im Projekt vorhanden ist.
So analysieren Sie Segmente in nur einer Zielsprache: Wählen Sie vor dem Öffnen des Fensters Statistiken eine Sprache im Bereich Übersetzungen der Projektzentrale aus. Wählen Sie alle Dokumente aus, öffnen Sie dann Statistiken und wählen Sie Ausgewählte Dokumente aus.
Im Vergleich zu einer Neuübersetzung des Texts fällt weniger Arbeit für ein Segment an, wenn dafür ein Treffer in einem Translation Memory vorhanden ist – zumindest theoretisch. Bevor Sie mit der Übersetzung beginnen, müssen Sie sich eine Vorstellung von Ihrem Arbeitsaufwand machen können. Dies gilt insbesondere, wenn bereits übersetzte Dokumente auf neuere Versionen aktualisiert werden sollen. In diesem Fall kann die eigentliche Übersetzungsarbeit lediglich 10 % (oder weniger) der Gesamtwortzahl der Ausgangsdokumente ausmachen, da Sie größtenteils die früheren Übersetzungen verwenden können.
Die Wortzahl wird in memoQ nach Trefferkategorien angegeben: Dadurch wissen Sie, wie viele Wörter in Segmenten mit 100%-Treffern enthalten sind, wie viele in 95–99%-Treffern usw.
Für jede Trefferkategorie können Sie eine Gewichtung festlegen. Die Gewichtung liegt zwischen 0 % (kein Arbeitsaufwand) und 100 % (Neuübersetzen jedes Worts). Sie multiplizieren die Wortzahl in einer Kategorie mit der Gewichtung. Dadurch ergibt sich eine theoretische gewichtete Wortzahl.
Beispiel: Ein 90%-Treffer in einem Segment unterscheidet sich normalerweise in einem Wort. Die Gewichtung für diese Trefferkategorie (85–94 %) kann beispielsweise bei 50 % liegen. Wenn im Segment 10 Wörter enthalten sind, werden 5 Wörter für dieses Segment berechnet.
Diese Berechnung ist nur sinnvoll, wenn das Projekt mindestens ein Translation Memory oder ein LiveDocs-Korpus enthält.
Dies können Sie für sich im Fenster Analysebericht erstellen mit den folgenden Optionen einrichten:
Diese Einstellungen gelten für ein lokales Projekt.
- Aktivieren Sie das Kontrollkästchen Projekt-TMs und Korpora verwenden. Dadurch wird sichergestellt, dass die Segmente in jedem Translation Memory und LiveDocs-Korpus im Projekt überprüft werden.
- Aktivieren Sie das Kontrollkästchen Homogenität berechnen. Es werden auch interne Fuzzy-Treffer berechnet. Das heißt es wird vorausberechnet, welche Treffer Sie aus dem Translation Memory erhalten werden, das sich während der Übersetzung füllt.
Verwenden Sie diese Einstellung nur, wenn Sie allein an dem Auftrag arbeiten: Aktivieren Sie das Kontrollkästchen Homogenität berechnen nicht, wenn auch andere Personen an der Übersetzung arbeiten.
- Deaktivieren Sie das Kontrollkästchen Gesperrte Zeilen einschließen: Wenn Sie Dokumente erhalten, die gesperrte Zeilen enthalten, sieht der Kunde meistens vor, dass Sie diese Zeilen nicht bearbeiten dürfen.
- Stellen Sie sicher, dass das Kontrollkästchen Wiederholungen haben Vorrang vor 100% Treffern aktiviert ist: Verwenden Sie diese Option, wenn eine konsistente Übersetzung wichtiger ist als die Verwendung aller möglichen Treffer aus dem Translation Memory.
- Stellen Sie sicher, dass das Kontrollkästchen Dateiübergreifende Wiederholungen aktiviert ist: Da Sie allein an der Übersetzung arbeiten, können Sie ein Segment verwenden, das von anderen Dokumenten im Projekt wiederholt wird. Deaktivieren Sie dieses Kontrollkästchen nur, wenn auch andere Personen an diesem Projekt arbeiten.
- Aktivieren Sie das Kontrollkästchen Gewichtete Anzahl anzeigen. Es wird eine ungefähre "tatsächliche" Wortzahl für den Auftrag berechnet. Dazu verwendet memoQ die in den Optionen (Kategorie Verschiedenes, Registerkarte Gewichtete Anzahl) festgelegten Gewichtungen.
Verwalten Sie ein Online-Projekt? Wenn Sie den Befehl Statistiken für ein Online-Projekt ausführen, verwendet memoQ die Gewichtungen vom memoQ-Server. Das Einrichten der Gewichtungen auf einem memoQ-Server erfolgt über den Server-Administrator. Wählen Sie Gewichtete Anzahl und prüfen Sie die Gewichtungen oder legen Sie sie fest.
Wenn mehrere Übersetzer an einer Reihe von Dokumenten arbeiten, kann nicht vorausberechnet werden, wann ein Übersetzer ein Segment oder ein Dokument bearbeiten wird. Sie können nicht wissen, welcher Übersetzer die Übersetzungen von anderen verwenden kann. Somit kann nicht vorausberechnet werden, welche internen Wiederholungen verwendet werden.
Fazit: Wenn die Übersetzung statt von einem einzelnen Übersetzer von mehreren Übersetzern übernommen wird, können Sie den Arbeitsaufwand vorab nicht genau abschätzen. Den tatsächlichen Arbeitsaufwand können Sie durch Ausführen einer Nach-Übersetzungsanalyse nach Abschluss der Übersetzung ermitteln.
Dies können Sie für das Team im Fenster Analysebericht erstellen mit den folgenden Optionen einrichten:
Diese Einstellungen gelten für ein Online-Projekt. Sie können sie auch in einem lokalen Projekt anwenden, wenn Sie Projekt-Manager sind und das Projekt auf einem Server veröffentlichen oder mit Paketen verteilen möchten.
- Aktivieren Sie das Kontrollkästchen Projekt-TMs und Korpora verwenden. Dadurch wird sichergestellt, dass die Segmente in jedem Translation Memory und LiveDocs-Korpus im Projekt überprüft werden.
-
Deaktivieren Sie das Kontrollkästchen Homogenität berechnen. memoQ sollte keine internen Fuzzy-Treffer erfassen, da nicht bekannt ist, wer zuerst ein Segment übersetzen wird.
Für weitere Informationen: Siehe Hilfe zu Homogenität und Wiederholungen in einem Projekt.
- Deaktivieren Sie das Kontrollkästchen Gesperrte Zeilen einschließen: Wenn Sie Dokumente erhalten, die gesperrte Zeilen enthalten, sieht der Kunde meistens vor, dass Sie diese Zeilen nicht bearbeiten dürfen.
- Stellen Sie sicher, dass das Kontrollkästchen Wiederholungen haben Vorrang vor 100% Treffern aktiviert ist: Verwenden Sie diese Option, wenn eine konsistente Übersetzung wichtiger ist als die Verwendung aller möglichen Treffer aus dem Translation Memory.
- Stellen Sie sicher, dass das Kontrollkästchen Dateiübergreifende Wiederholungen deaktiviert ist: Es ist nicht bekannt, welche Übersetzer Wiederholungen verwenden können.
- Aktivieren Sie das Kontrollkästchen Gewichtete Anzahl anzeigen. Es wird eine ungefähre "tatsächliche" Wortzahl für den Auftrag berechnet. Dazu verwendet memoQ die Gewichtungen von der Registerkarte Gewichtete Anzahl im Bereich Verschiedenes von Optionen.
Verwalten Sie ein Online-Projekt? Wenn Sie den Befehl Statistiken für ein Online-Projekt ausführen, verwendet memoQ die Gewichtungen vom memoQ-Server. Das Einrichten der Gewichtungen auf einem memoQ-Server erfolgt über den Server-Administrator. Wählen Sie Gewichtete Anzahl und prüfen Sie die Gewichtungen oder legen Sie sie fest.
Um sich lediglich einen Überblick über die Größe des Projekts zu verschaffen, verwenden Sie die folgenden Einstellungen:
- Deaktivieren Sie das Kontrollkästchen Projekt-TMs und Korpora verwenden.
- Deaktivieren Sie das Kontrollkästchen Homogenität berechnen.
- Aktivieren Sie das Kontrollkästchen Gesperrte Zeilen einschließen.
- Aktivieren Sie das Kontrollkästchen Wiederholungen haben Vorrang vor 100% Treffern.
- Deaktivieren Sie das Kontrollkästchen Dateiübergreifende Wiederholungen.
Ein Überprüfer – oder Korrekturleser – bearbeitet eine bereits vorhandene Übersetzung. Die Arbeit von Überprüfern beruht nicht auf Treffern aus Translation Memories. Sie bearbeiten den gesamten Text, daher ist es nicht sinnvoll, ihre Arbeit anhand von Translation Memories zu analysieren.
- Deaktivieren Sie das Kontrollkästchen Projekt-TMs und Korpora verwenden.
- Deaktivieren Sie das Kontrollkästchen Homogenität berechnen.
- Wenn der Überprüfer nicht nur die neu übersetzten Segmente, sondern die gesamte Übersetzung überprüfen soll: Aktivieren Sie das Kontrollkästchen Gesperrte Zeilen einschließen.
- Aktivieren Sie das Kontrollkästchen Wiederholungen haben Vorrang vor 100% Treffern.
- Deaktivieren Sie das Kontrollkästchen Dateiübergreifende Wiederholungen.
In den meisten Fällen, vor allem bei Übersetzungen aus dem Englischen, wird der Arbeitsaufwand anhand der Wortzahl des Ausgangstexts berechnet. In einigen Märkten oder Fachgebieten werden Übersetzungen jedoch nach der Anzahl der Zeichen berechnet.
In der bei der Analyse erstellten Tabelle ist immer die Zeichenzahl sowie die Wortzahl angegeben. In den meisten Fällen müssen auch die Leerzeichen gezählt werden.
Stellen Sie sicher, dass das Kontrollkästchen Leerzeichen in Zeichenzählung einschließen aktiviert ist. Alle Leerzeichen werden in memoQ einzeln gezählt. Zwei Leerzeichen direkt nacheinander werden somit als zwei Leerzeichen und nicht als ein Leerzeichen gezählt.
Einige Dokumentformate enthalten viele Inline-Tags im Text. Zu diesen Formaten gehören XML, HTML, PDF, InDesign, manchmal Microsoft Word – und eventuell viele weitere Formate.
Das Einfügen dieser Tags an den richtigen Stellen kann viel Arbeit bedeuten. Dies muss sich im Analysebericht widerspiegeln.
Tags werden in memoQ normalerweise gezählt, allerdings in einer separaten Zahlenangabe. Diese lässt sich nur schlecht in die endgültige Wortzahl einbeziehen.
Bei der Tag-Gewichtung können Sie Tags als Wörter oder als Zeichen zählen.
Geben Sie in der Zeile Tag-Gewichtung im Feld Wort/Wörter eine Zahl ein. Wenn Sie z. B. 0.25 eingeben, wird nach jedem vierten Inline-Tag ein Wort gezählt – bzw. ein Viertel Wort nach jedem Tag.
Dies ist auch mit Zeichen möglich. Geben Sie im Feld Zeichen eine Zahl ein. Wenn Sie z. B. 2 eingeben, werden nach jedem Tag zwei Zeichen gezählt.
Im Fenster Statistiken gibt es mehrere Optionen, über die Sie die im Bericht zu berücksichtigenden Details festlegen können.
- So erhalten Sie einen separaten Bericht für jedes Dokument: Aktivieren Sie das Kontrollkästchen Ergebnisse für jede Datei anzeigen.
- So erhalten Sie die Gesamtanzahl der Segmente, Wörter und Zeichen, nicht nur die Analyseergebnisse: Aktivieren Sie das Kontrollkästchen Wortzahl anzeigen. Dies ist der Normalfall in memoQ.
- So erhalten Sie einen Statusbericht – wie viele Segmente oder Wörter sind bestätigt, bearbeitet, vorübersetzt oder unberührt: Aktivieren Sie das Kontrollkästchen Statusbericht.
- So erfahren Sie die Größe der Übersetzung: Aktivieren Sie das Kontrollkästchen Wortzahl des Zieltextes einschließen. Verwenden Sie diese Option, wenn Sie die Rechnung auf Basis des Zieltextes – nicht des Ausgangstextes – erstellen.
Verwenden Sie nicht die Zählweise gemäß Trados 2007: Normalerweise entspricht die Wortzählung in memoQ der in Microsoft Word. Das Übersetzungstool Trados 2007 oder ältere Versionen (Trados Translator's Workbench) beherrschten lange Zeit den Markt, und es war wichtig, dass mit memoQ ähnliche Wortzahlen berechnet wurden, damit Übersetzungsfirmen die Zahlen vergleichen konnten. Dies ist aber nicht mehr der Fall. Verwenden Sie die Trados 2007-Zählweise nur, wenn Ihr Kunde weiterhin mit einer älteren Trados-Version arbeitet und darauf besteht.
Rechnungslegung auf Basis der Wortzahl des Zieltextes, nicht des Ausgangstextes? Aktivieren Sie das Kontrollkästchen Wortzahl des Zieltextes einschließen.
Nachdem Sie die oben aufgeführten Optionen alle festgelegt haben, können Sie die Analyse ausführen. Klicken Sie auf Ermitteln.
Je nach Größe des Projekts und der verwendeten Ressourcen kann dies einige Minuten oder länger dauern.
Nach Abschluss der Analyse werden die Ergebnisse unten im Fenster Statistiken angezeigt:
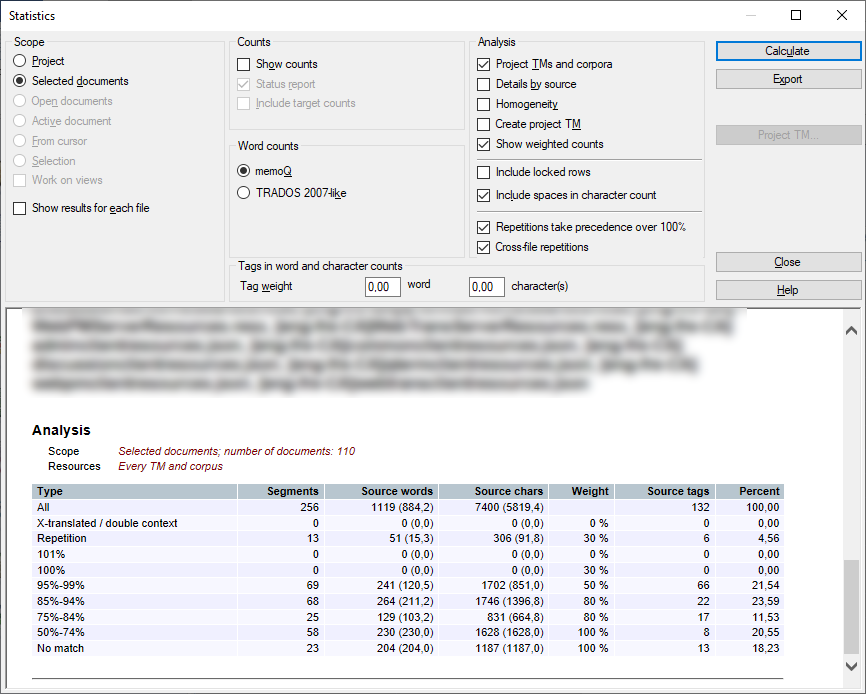
Sie können sie hier überprüfen. Während Sie das Projekt vorbereiten, können Sie dieses Fenster schließen und zum Projekt zurückkehren. Sie können beispielsweise ein neues Translation Memory hinzufügen, damit die Anzahl für Kein Treffer geringer ausfällt.
Für den Fall, dass Sie die Analyse verschicken möchten: Sie können sie in einer Datei speichern. memoQ kann Berichte in Formaten speichern, die Sie mit Excel oder einem Webbrowser öffnen können.
So speichern Sie die Analyseergebnisse:
- Klicken Sie auf Export. Das Fenster Statistikergebnisse exportieren wird angezeigt.
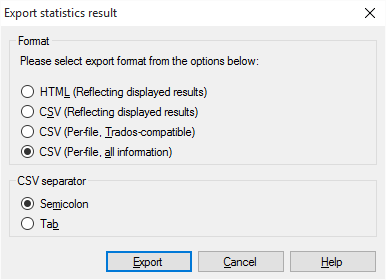
- Wählen Sie eines der folgenden Formate aus:
- HTML (Ergebnisse, wie angezeigt): Speichert die angezeigten Statistiken als HTML-Datei
- CSV (Ergebnisse, wie angezeigt): Speichert die Ergebnisse in einer CSV-Datei (die in Excel geöffnet werden kann)
- CSV (pro Datei, TRADOS-kompatibel): Speichert die Ergebnisse in einer CSV-Datei, wobei die Details zu jedem Dokument genau eine Zeile einnehmen. Dies ist der alte Trados-Stil.
- CSV (pro Datei, alle Informationen): Speichert die Ergebnisse in einer CSV-Datei, wobei das Layout der Ergebnisse genau dem im Fenster Statistiken entspricht
- Wenn Sie eines der CSV-Formate auswählen, können Sie das Trennzeichen auswählen, mit dem die Spalten in der Tabelle getrennt werden. Es gibt keinen Grund, ein anderes als das Tabulatorzeichen zu verwenden: Klicken Sie unter CSV-Trennzeichen auf Tab.
- Klicken Sie auf Export. Das Fenster Speichern unter wird angezeigt. Geben Sie einen Speicherort und einen Namen für die Berichtsdatei an und klicken Sie auf Speichern. Der Bericht wird exportiert und Sie kehren zum Fenster Statistiken zurück.
Beim Ermitteln der Analyse kann memoQ die relevanten Segmente aus den Translation Memories und den LiveDocs-Korpora des Projekts erfassen. Sie können ein als Projekt-TM bezeichnetes spezielles TM zusammenstellen, das nur die von der Analyse gefundenen Segmente enthält.
Gehen Sie dazu wie folgt vor:
- Aktivieren Sie vor Ausführen der Analyse das Kontrollkästchen Projekt-TM erstellen.
- Führen Sie die Analyse aus: Klicken Sie auf Ermitteln.
- Speichern Sie das Translation Memory: Klicken Sie auf Projekt-TM. Das Fenster Projekt-TM exportieren wird angezeigt:

- Wählen Sie aus, wo die Segmente abgelegt werden sollen:
- Sie können sie in einer TMX-Datei speichern, sodass sie auf einem anderen Computer und in ein anderes Übersetzungstool importiert werden können.
- Sie können sie in einem Translation Memory speichern, das bereits Teil Ihres Projekts ist. Wählen Sie in der Dropdown-Liste Name das Translation Memory aus.
- Oder Sie können ein neues Translation Memory im Projekt erstellen und die Segmente dort speichern.
- Klicken Sie auf Export. Die Segmente werden gespeichert.
Bei Auswahl von TMX-Datei: Das Fenster Speichern unter wird angezeigt. Wählen Sie einen Speicherort und einen Namen für die Datei aus und klicken Sie auf Speichern.
Die Ergebnisse bestehen aus zwei Teilen: einem Abschnitt Wortzahl und einem oder mehreren Abschnitten Analyse. Dies hängt von der Anzahl der Translation Memories im Projekt und den Einstellungen für die Kontrollkästchen Ergebnisse für jede Datei anzeigen und Details pro Quelle ab.
Bereich: Der im Abschnitt "Bereich" ausgewählte Bereich der Analyse
Ressourcen: Gibt die Ressourcen an, auf deren Grundlage die Ergebnisse gewonnen wurden. Hier finden Sie den Namen eines Translation Memory oder Homogenität für Homogenitätsprüfungen. Wenn es sich um aggregierte Ergebnisse handelt, wird die Beschriftung Jedes TM und Korpus bzw. Jedes TM und Korpus, Homogenität angezeigt.
Spalte Typ:
- Alle: Diese Zeile enthält die Anzahl aller Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern im ausgewählten Bereich.
- Dokumentenbasiert vorübersetzt: Diese Zeile enthält die Anzahl der dokumentenbasiert vorübersetzten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern im ausgewählten Bereich.
- Wiederholung: Diese Zeile enthält die Anzahl der sich wiederholenden Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe auf der Grundlage der Anzahl an Ausgangswörtern im ausgewählten Bereich.
Analyse für ausgewählten Bereich: Wenn ein Projekt beispielsweise zwei Dokumente enthält, in denen das gleiche Segments jeweils genau einmal vorkommt, wird in der für den Projektbereich ermittelten Statistik ein Segment als Wiederholung angezeigt. Wenn Sie die Statistik für die zwei Dokumente separat ermitteln, werden keine Wiederholungen angezeigt.
Wenn Sie ein großes Projekt auf verschiedene Übersetzer aufteilen möchten, kann dieser Unterschied erheblich sein, da die Gesamtstatistik für das gesamte Projekt unter Umständen eine deutlich höhere Anzahl an Wiederholungen enthält als die Statistiken für die verschiedenen Teilmengen der Dokumente zusammen.
- Nicht begonnen: Anzahl der unberührten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
- Vorübersetzt: Anzahl der vorübersetzten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
- Fragmente: Anzahl der Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis, einschließlich aus Fragmenten zusammengefügten Treffern
- Bearbeitet: Anzahl der bearbeiteten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis
- Durch Übersetzer bestätigt: Anzahl der bestätigten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
- Durch Überprüfer 1 bestätigt: Anzahl der durch Überprüfer 1 bestätigten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis
- Durch Überprüfer 2 bestätigt (Korrektur gelesen): Anzahl der durch Überprüfer 2 bestätigten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis.
- Gesperrt: Anzahl der gesperrten Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis
- Prozentbereiche: Diese Zeilen zeigen die Anzahl der Ausgangssegmente, Ausgangswörter und Ausgangstextzeichen sowie die Prozentangabe für den analysierten Text auf Wortbasis für Segmente mit einem Treffer aus derselben Kategorie. Wenn hinter 75–84 % die Angabe 5 steht, als Ressource Jedes TM und Korpus und als Bereich Projekt angegeben ist, bedeutet dies, dass Sie bei Kombination aller Translation Memories für fünf Segmente einen 75–84-%-Treffer erhalten.
Spalte Segmente: Anzahl der in der Spalte Typ angegebenen Ausgangssegmente im ausgewählten Bereich.
Spalte Ausgangswörter: Anzahl der in der Spalte Typ angegebenen Ausgangswörter im ausgewählten Bereich Wenn die Tag-Gewichtung ungleich 0 ist, ist diese Anzahl unter Umständen größer als die eigentliche Wortzahl.
Spalte Ausgangszeichen: Anzahl der in der Spalte Typ angegebenen Ausgangstextzeichen im ausgewählten Bereich Die Zeichenanzahl umfasst Leerzeichen, aber keine nicht übersetzten Format-Tags. Wenn die Tag-Gewichtung ungleich 0 ist, ist diese Anzahl unter Umständen größer als die eigentliche Zeichenanzahl.
Spalte Ausgangstext-Tags: Anzahl der Tags im ausgewählten Bereich, die in den Segmenten der Spalte Typ enthalten sind
Spalte Prozent: Prozentsatz der Quellwörter in dieser Kategorie in Bezug auf die Gesamtwortzahl im ausgewählten Bereich Die Summe aller Prozentangaben ergibt aufgrund der Rundung möglicherweise nicht genau 100 %.
Spalte Zieltextwörter: Anzahl der in der Spalte Typ angegebenen Zielwörter im ausgewählten Bereich. Diese Spalte wird nur angezeigt, wenn das Kontrollkästchen Wortzahl des Zieltextes einschließen aktiviert ist.
Spalte Zielzeichen: Anzahl der in der Spalte Typ angegebenen Zieltextzeichen im ausgewählten Bereich. Diese Spalte wird nur angezeigt, wenn das Kontrollkästchen Wortzahl des Zieltextes einschließen aktiviert ist.
In der Projekt-Manager-Version von memoQ können Sie in einem Projekt mit zwei oder mehr Zielsprachen arbeiten – in lokalen wie auch in Online-Projekten.
Wenn Sie Statistiken für alle Zielsprachen des Projekts ausführen, erhalten Sie zusätzliche Details:
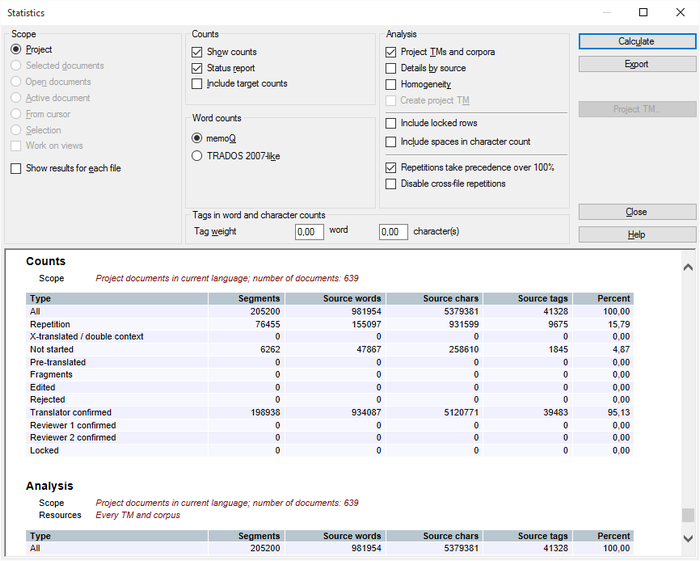
Wenn Sie die Analyse exportieren, wird nun für jedes zielsprachliche Dokument für die Optionen HTML und CSV (Ergebnisse, wie angezeigt) eine separate Zeile hinzugefügt. Wenn Sie die Analyse als CSV (pro Datei, TRADOS-kompatibel) oder als CSV (pro Datei, alle Informationen) exportieren, wird in der CSV-Datei für jede Zielsprache ein Präfix hinzugefügt, z. B. [ger] Beispiel.txt:
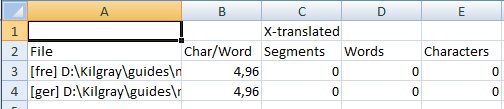
Hinweis: Wenn Sie die Analyse im Modus alle Sprachen für ein lokales Projekt ausführen, ist die Option zum Erstellen eines Projekt-TMs nicht verfügbar.
Wenn die Ausgangssprache eines Projekts eine ostasiatische Sprache ist, sind in den Statistikergebnissen von memoQ zusätzlich die Spalten Nicht-asiatische Ausgangstextwörter und Asiatische Ausgangstextzeichen vorhanden:
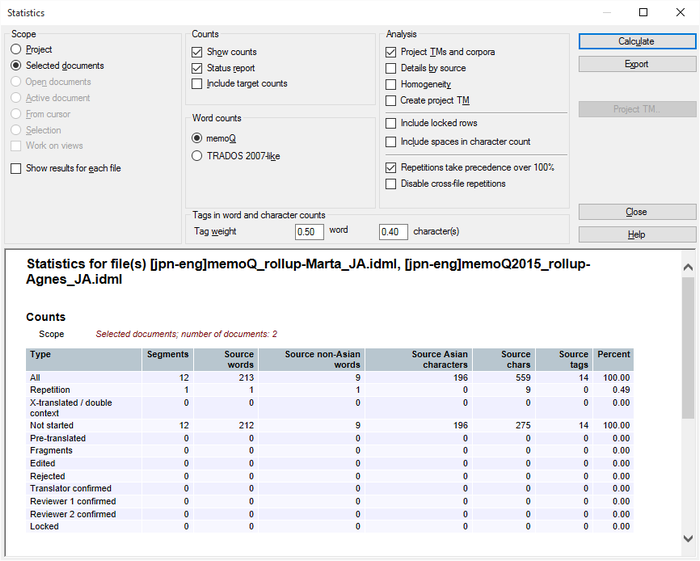
Im Japanischen und im Chinesischen werden Wörter nicht durch Leerzeichen voneinander getrennt, sodass die Wortzählung nicht zuverlässig ist. Verwenden Sie daher stattdessen die asiatische Zeichenzählung. Im Fenster Statistiken zeigt die Spalte Ausgangswörter die Summe von Nicht-asiatische Ausgangstextwörter und Asiatische Ausgangstextzeichen (Ausgangswörter = Zeichen) an.
Koreanisch verwendet Leerzeichen: Im Koreanischen werden – anders als im Japanischen und Chinesischen – Leerzeichen zum Trennen der Wörter verwendet. Wenn Sie Koreanisch als Ausgangssprache verwenden, können Sie die Wortzählung nutzen. Zudem wird das Koreanische wie das Deutsche als alphabetische Schrift gezählt.
Abschließende Schritte
So kehren Sie zur Projektzentrale, zum Fenster memoQ-Online-Projekt oder zum Übersetzungseditor zurück: Klicken Sie auf Schließen.