Fichiers PO Gettext
Les fichiers PO sont des fichiers de localisation, principalement utilisés pour écrire des programmes multilingues sur des ordinateurs Unix. Les fichiers PO Gettext sont bilingues et peuvent contenir une seule langue source et langue cible.
memoQ peut travailler directement avec des fichiers PO Gettext. Le fichier exporté est bilingue.
Comment se rendre ici
-
Dans la fenêtre Options d’importation de documents, sélectionnez les fichiers PO Gettext, puis cliquez sur Modifier le filtre et la configuration.
-
La fenêtre Paramètres d’importation de document apparaît. Dans la liste déroulante Filtre, choisissez le filtre PO Gettext.
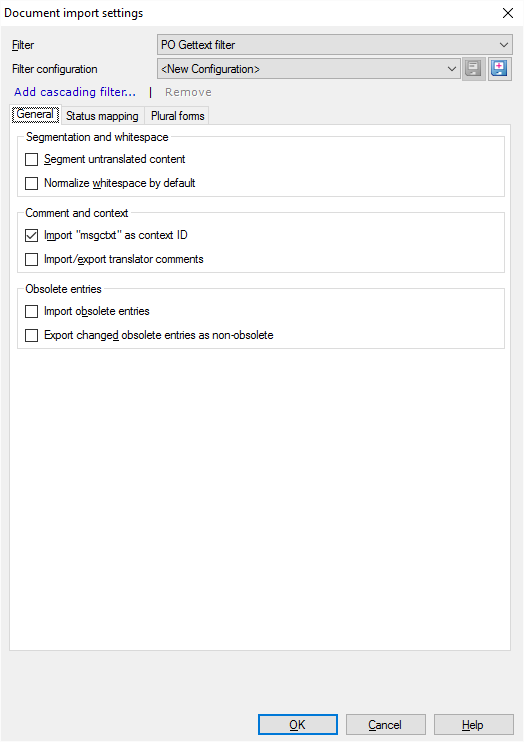
Que pouvez-vous faire?
-
Normalement, memoQ ne divise pas le texte non traduit en segments. Un fichier PO est composé d’entrées. Chaque entrée devient exactement un segment, peu importe combien de phrases elle contient. Diviser les entrées en segments: Sous Segmentation et espaces vides, cochez la case Segment non traduit.
-
Normalement, memoQ ne change pas les espaces (cassants et non cassants), les tabulations et les sauts de ligne lorsqu’il importe des fichiers PO Gettext. Mais memoQ peut les normaliser: Il peut convertir des séquences d’onglets, des espaces, des espaces insécables et des caractères de saut de ligne en un seul espace. Lorsqu’il normalise l’espace blanc, memoQ supprime également tout l’espace blanc au début et à la fin des entrées. Normaliser les espaces: Cochez la case Normaliser les espaces par défaut.
Exemple :
Avant normalisation:
Il est un
test, avec beaucoup d’espaces.
Après normalisation:
C’est un test, avec beaucoup d’espaces.
-
Dans un fichier PO Gettext, chaque entrée a un attribut appelé 'msgctxt'. Normalement, memoQ importe cet attribut comme le contexte du segment. Si vous n’avez pas besoin du contexte, décochez la case Importer un fichier msgctxt comme ID de contexte.
-
Normalement, memoQ n’importe pas les commentaires des fichiers PO Gettext. Importer des commentaires: Cochez la case Importer/exporter les commentaires du traducteur.
Si les commentaires ne sont pas importés, ils ne sont pas exportés non plus: Si vous ne choisissez pas d’importer les commentaires du fichier PO Gettext, memoQ n’exportera pas les commentaires que les traducteurs font. Si vous souhaitez que les commentaires des traducteurs ou des relecteurs apparaissent dans les fichiers exportés, cochez cette case, même lorsqu’il n’y a pas de commentaires dans les fichiers sources.
-
Dans les fichiers PO Gettext, les entrées obsolètes sont celles qui n’apparaissent pas dans le programme étant en cours de localisation, ou celles qui ne devraient pas être traduites. Normalement, memoQ n’importe pas ceux-ci.
- Importer des entrées obsolètes: Cochez la case Importer les entrées obsolètes.
- Normalement, si vous importez des entrées obsolètes, leurs traductions deviennent obsolètes. Mais vous pouvez les rendre actifs à nouveau. Pour ce faire, cochez la case non-obsolète pour exporter les entrées obsolètes.
La structure d’une entrée d’un fichier PO est la suivante:
white-space
# commentaires du traducteur
#. extraits-commentés
# : référence...
#, drapeau...
#| msgid previous-untranslated-string
msgid chaîne-non-traduite
msgstr traduction automatique
-
La chaîne msgid untranslated-string est importée comme source, et la chaîne msgstr translated-string est importée comme cible. Les champs msgid et champs msgstr contiennent la chaîne source et la chaîne cible d’une unité de traduction. Les éléments msgid sont uniques au sein d’un domaine PO.
Par exemple:
.
msgid " "
"memoQ Zrt. est "
" "
« %. \n»
Qu’est-ce que c’est?
" "
"De quoi parle l’entreprise?"
est identique à:
memoQ Zrt. est%s. De quoi \n s’agit-il dans l’entreprise? - L’élément msgctxt est importé en tant qu’ID de contexte. L’élément #| msgid est marqué comme obsolète.
- Le #, élément indicateur est conservé. Les indicateurs sont utilisés pour indiquer l’état d’une unité de traduction (par exemple, terminée ou floue). Un drapeau flou peut être associé à un état de segment memoQ (dans l’onglet de mappage des états). Les indicateurs multiples sont séparés par des virgules.
- Les # Translator-commentaires peuvent être importés et exportés en tant que commentaires memoQ, si vous choisissez de le faire lors de l’importation du fichier. Ces commentaires sont ajoutés par les traducteurs et ne sont pas présents dans les fichiers PO. Les commentaires sont insérés avant les commentaires extraits et les commentaires de référence.
- Les champs #. commentaires extraits et # : commentaires de référence sont conservés dans la structure. Ces ne sont pas modifiés par memoQ. Les éléments de commentaires extraits sont extraits du code source s’ils se trouvent dans la même ligne que la chaîne source ou dans la ligne précédente. Les éléments de commentaires de référence sont des listes d’emplacements séparées par des espaces, spécifiant où l’unité de traduction se trouve dans un fichier source. Une seule unité de traduction peut contenir plusieurs références (une pour chaque emplacement).
- Les entrées obsolètes sont des entrées qui sont commentées lorsque le fichier PO est mis à jour. Par exemple, le texte qui n’est pas destiné à la traduction devient obsolète. Habituellement, l’élément msgmerge est utilisé pour commenter les entrées (les rendre obsolètes). Les entrées obsolètes sont marquées avec #~.
Vous pouvez trouver une spécification complète de ce format de fichier ici ou ici.
Les entrées dans un fichier PO Gettext ont deux états: flou et non flou. Pour importer ceux-ci dans memoQ, ou les exporter de nouveau vers les fichiers PO Gettext, cliquez sur l’onglet de mappage des états.
- Normalement, memoQ n’importe pas les états Gettext lorsqu’il importe un fichier. Pour ce faire, cochez la case "Vérifier les états de la carte lors de l’importation ".
- Encore une fois, au début, memoQ n’exporte pas les états de memoQ lorsqu’il exporte un fichier PO Gettext. Pour ce faire, cochez la case d’exportation des états de la carte memoQ.
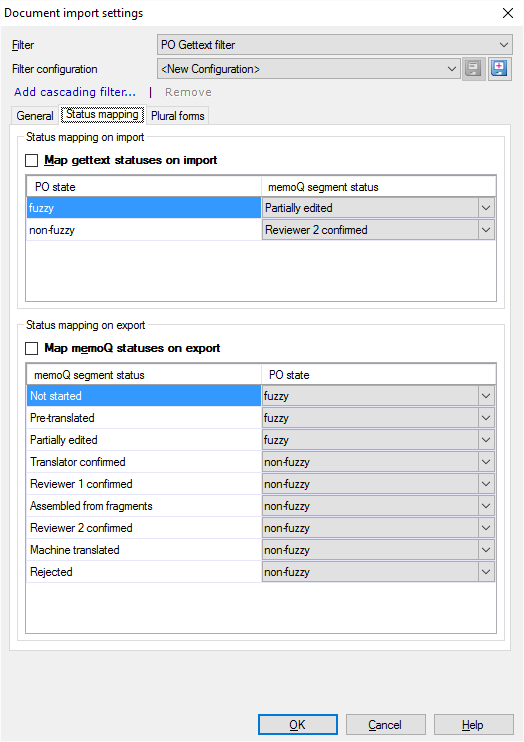
Lorsque memoQ importe un fichier PO Gettext, il comprend l’état qu’il lit à partir du fichier.
- Normalement, les entrées « floues » sont importées comme Partiellement éditées (Éditées). Pour changer cela, choisissez un état différent dans le menu déroulant à côté de 'fuzzy'.
- Normalement, les entrées « non-fusées » sont importées comme Confirmés par Relecteur 2. Pour changer cela, choisissez un état différent dans la liste déroulante à côté de 'non-fuzz'.
Lorsque memoQ exporte un fichier PO Gettext, l’état de chaque segment est exporté soit comme 'fuzz', soit comme 'non-fuzzé'.
Normalement, les segments Non commencé,Pré-traduit et Partiellement édité (Édité) sont exportés comme 'flous'. Le reste est exporté comme 'non-fuzzé'. Pour changer cela, choisissez un état différent dans une ou plusieurs des zones déroulantes de la liste en bas.
Si une entrée contient des espaces réservés numériques, les fichiers PO Gettext peuvent contenir des variantes pour le texte - si les formes au pluriel sont différentes dans la langue source ou la langue cible.
Vous pouvez configurer cela dans l’onglet formulaires Plural. Permettre les variantes: Cochez la case Ajuster les entrées au pluriel.
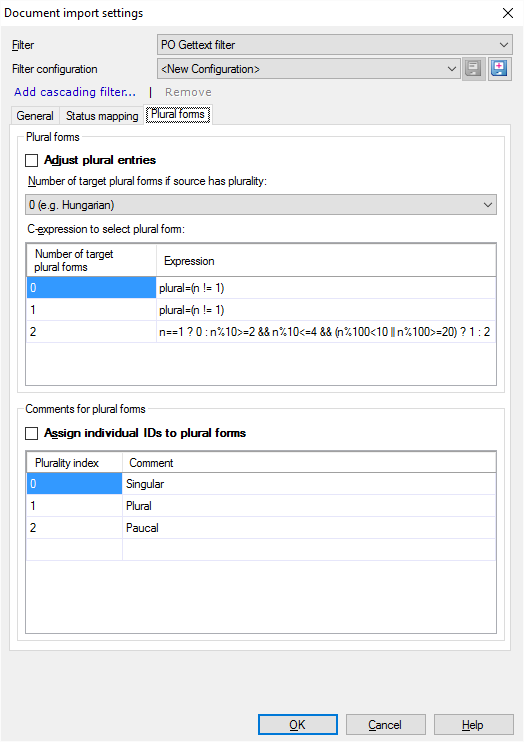
Dans les entrées, les variantes au singulier et au pluriel ressemblent à ceci:
# : SRC/msgcmp.c:338 src/po-lex.c:699
#, format C
msgid "trouvé%d erreur fatale"
msgid_plural "trouvé%d erreurs fatales"
msgstr[0] "on a trouvé%d erreur fatale"
"On a trouvé%d erreurs fatales"
Choisissez combien de formes au pluriel la langue source a. Dans le nombre de formes au pluriel de la cible si la source a une liste déroulante au pluriel, vous pouvez choisir 0 (par exemple) Hongrois), 1 (par exemple Langues latines), ou 2 (p. ex. Langues slaves).
L’expression à côté de chaque forme indique quand utiliser quelle forme au pluriel. Vous pouvez définir cela en utilisant des expressions C. Les expressions C sont des formules conditionnelles qui suivent la syntaxe du langage de programmation C (non détaillée ici).
Chaque type de pluriel peut avoir un nom. Utiliser ces noms: Cochez la case Attribuer des ID individuels aux pluriels de formulaires. Les noms que vous voyez dans la copie d’écran sont là automatiquement. Cliquez sur chaque nom pour le changer.
Lorsque la case au pluriel de formulaires pour attribuer des identifiants individuels est cochée, cette information est ajoutée à l’attribut msgctxt (context). Si vous ne faites pas cela, et qu’il y a deux formes au pluriel de la cible, la source et l’ID de contexte peuvent être les mêmes pour les deux. Dans ce cas, le contexte ne fournirait pas assez d’informations pour les stocker dans la mémoire de traduction en tant que deux unités différentes - à moins que l’information au pluriel ne soit présente.
Lorsque vous avez terminé
-
Pour confirmer les paramètres et revenir à la fenêtre Options d’importation de documents: Cliquez sur OK.
Dans la fenêtre Options d’importation de documents: Cliquez à nouveau sur OK pour commencer l’importation des documents.
-
Pour revenir à la fenêtre des Options d’importation, et ne pas changer les paramètres du filtre: Cliquez sur Annuler.
-
Si c’est un filtre en cascade, vous pouvez modifier les paramètres d’un autre filtre dans la chaîne : Cliquez sur le nom du filtre en haut de la fenêtre.
Il est possible de cascader des filtres après les filtres bilingues et multilingues. Par exemple, textes ,textes multilingues Excel et textes délimités peuvent être le premier filtre dans une chaîne de filtrage, mais n’oubliez pas que le Module de balisage RegEx doit toujours être le dernier filtre appliqué.