Règles d’importation XML
Pour importer un fichier XML multilingue, vous avez besoin de règles.
Une entrée dans un fichier XML multilingue a le même texte dans plusieurs langues. Une règle d’importation indique à memoQ où trouver le texte pour l’une de ces langues.
La règle d’importation indique également à memoQ s’il y a un contexte, un commentaire, et peut-être une limite de longueur pour le texte dans cette langue. Pratiquement, vous avez besoin d’une règle d’importation pour chaque langue.
Une règle d’importation utilise des expressions XPath pour indiquer l’emplacement du texte ou d’autres informations dans un fichier XML. D’une certaine manière, XPath décrit les "coordonnées" d’un élément dans un fichier XML.
Dans la fenêtre des règles d’importation XML, vous pouvez configurer des règles d’importation sans réellement connaître ou écrire des expressions XPath.
Comment se rendre ici
- Commencez à importer un fichier XML multilingue.
- Dans la fenêtre Options d’importation de documents, sélectionnez les fichiers XML, puis cliquez sur Modifier le filtre et la configuration.
- La fenêtre Paramètres d’importation de document apparaît. Dans la liste déroulante Filtrer, choisissez filtre XML multilingue.
- Cliquez sur l’onglet Règles d’importation. La liste des règles d’importation XML apparaît. En bas, cliquez sur Modifier les règles d’importation. La fenêtre des règles d’importation XML apparaît.
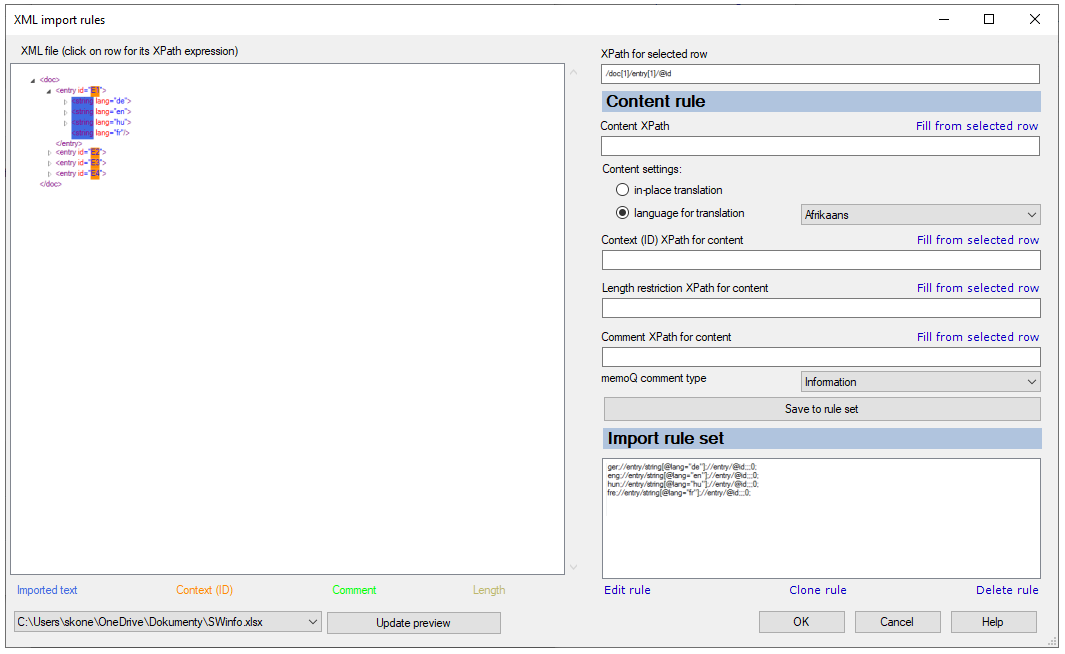
Que pouvez-vous faire?
Établir une règle pour chaque langue dans le projet - ou pour chaque langue dans le document.
À gauche, memoQ affiche le contenu de l’un des fichiers XML que vous importez. Normalement, c’est le premier dans la sélection.
Le fichier XML apparaît dans une arborescence XML. Au début, vous ne voyez que l’élément le plus haut. Vous pouvez développer et réduire les éléments en cliquant sur les petites têtes de flèche à gauche.
Utiliser un fichier différent pour l’aperçu: Choisissez un autre fichier dans la liste déroulante en bas à gauche. Alors cliquez sur Mettre à jour l’aperçu. Vous pouvez choisir parmi les fichiers que vous avez initialement sélectionnés pour l’importation.
D’abord, établissez la règle pour la langue source. Dans l’arborescence XML à gauche, cliquez sur la balise qui contient le texte source. Assurez-vous de cliquer sur la balise. Ne cliquez pas sur le texte lui-même, ni sur un de ses attributs.
Dans la boîte XPath pour le segment sélectionné, memoQ affiche l’expression XPath qui pointe vers cette balise. S’il y a d’autres endroits similaires dans le document, cette expression XPath les ignore toujours.
Dans la zone Content XPath, cliquez sur Remplir à partir du segment sélectionné. L’expression XPath apparaît également dans la zone XPath de contenu.
Vous n’êtes pas terminé encore: Vous devez modifier cette expression XPath pour sélectionner tous les éléments similaires du document. Ensuite, dans la liste déroulante de langue de memoQ, choisissez la langue pour cet élément.
Exemple :
La langue source est allemande. Dans l’exemple ci-dessous, cliquez sur la balise « string » où l’attribut « lang » est "de".
memoQ insère cette expression XPath:
/ doc[1]/entrée[1]/chaîne[1]
Cela ne signifie pas 'toutes les chaînes allemandes'. Cela signifie le premier élément de chaîne de la première entrée du premier document. Si vous laissez cette règle comme ça, elle importera exactement un segment, même s’il y a des milliers de documents similaires dans les documents que vous importez.
Donc, au lieu de cela, vous avez besoin d’un élément XPath qui dit: toutes les chaînes où l’attribut « lang » est "de", de chaque entrée spécifique, de tout document dans l’importation. Vous ne vous souciez pas de quel document, mais vous voulez vous assurer que les parties de texte importées dans un segment proviennent en fait de la même 'entrée'.
Dans la zone XPath de contenu, modifiez l’expression XPath comme suit:
//entrée/string[@lang="de"]
Dans la liste déroulante des langues de memoQ, choisissez l’allemand.
En plus du contenu, vous pouvez récupérer le contexte, ainsi qu’une restriction de longueur optionnelle et un commentaire optionnel du document XML.
Il est recommandé que vous saisissiez au moins le contexte.
Exemple :
Dans le fichier d’exemple, le contexte pour une entrée est l’ID d’entrée. Cliquez sur l’attribut 'id' de la première balise 'entry'. À l’Xpath contextuel (ID) de la zone de contenu, cliquez sur Remplir à partir du segment sélectionné.
memoQ insère cette expression XPath:
/doc[1]/entry[1]/@id
Cela signifie l’attribut « id » de la première entrée du premier document. Au lieu de cela, vous avez besoin d’un élément XPath qui indique: l’attribut « id » de chaque entrée, de tout document dans l’importation. Vous ne vous souciez pas de quel document, mais vous voulez vous assurer que toutes les dates importées dans un segment proviennent en fait de la même 'entrée'.
Dans le contexte (ID) XPath pour la zone de contenu, modifiez l’expression XPath comme suit:
//entrée/@id
S’il est nécessaire - et si ces données sont présentes - établir des règles similaires pour la restriction de longueur et le commentaire pour le texte. Après avoir inséré l’expression XPath pour le commentaire, utilisez la boîte déroulante de type de commentaire de memoQ pour choisir le type de commentaire.
Rappelez-vous qu’une expression XPath créée automatiquement pointe vers un seul élément ou attribut dans le XML. Vous devez modifier l’expression pour la rendre plus générale - afin d’inclure tous les éléments pertinents ou attributs. Dans l’exemple, c’est exactement ce que nous avons fait.
Après avoir configuré une expression XPath pour chaque élément que vous souhaitez dans le segment, cliquez sur Enregistrer dans l’ensemble de règles.
À ce stade, vous devez également ajouter des règles pour les autres langues. Répétez les étapes ci-dessus.
Dans l’exemple, l’expression XPath pour récupérer les chaînes en anglais est //entry/string[@lang="en"]
Après avoir configuré tout pour le texte allemand, et cliqué sur Enregistrer dans l’ensemble de règles, les expressions XPath et d’autres paramètres restent dans la fenêtre des règles d’importation XML.
Dans l’exemple, pour ajouter la règle pour le texte anglais, il suffit de modifier la zone Content XPath pour qu’elle contienne //entry/string[@lang="en"]. Puis cliquez sur Enregistrer pour l’ensemble de règles à nouveau.
Changer une règle existante, et non ajouter une nouvelle: Cliquez sur la règle en bas (dans la liste des règles d’importation ). Les détails de la règle apparaissent dans les zones de texte en haut. Pour modifier cette règle, cliquez sur Modifier la règle en bas. Ensuite, modifiez les expressions XPath et changez les paramètres selon vos besoins. Lorsque vous cliquez sur Enregistrer pour l’ensemble de règles, la règle existante est mise à jour.
Si vous modifiez simplement les expressions XPath et les paramètres, mais que vous ne cliquez pas sur Modifier la règle, le bouton Enregistrer dans les règles ajoute une nouvelle règle.
memoQ met en évidence tous les éléments que la règle actuelle détecte: Lorsque vous cliquez sur une règle d’importation, memoQ met en surbrillance tous les éléments dans l’arborescence XML qui sont pris en compte par la règle. Ces éléments sont codés par couleur: consultez la légende au bas de la fenêtre des règles d’importation XML. Lorsque vous cliquez sur une règle, vérifiez si tous les éléments pertinents sont surlignés. Développez plusieurs entrées dans le document si nécessaire.
Lorsque vous avez terminé
Pour enregistrer les règles et revenir à la fenêtre Paramètres d’importation de documents: Cliquez sur OK.
Pour ignorer les règles et revenir à la fenêtre Paramètres d’importation de documents sans nouvelles règles: Cliquez sur Annuler.