統計
memoQの統計は、翻訳メモリを使用して単語数、一致、繰り返しを分析することにより、作業量と費用を見積もるのに役立ちます。このガイドは、さまざまなプロジェクトの役割とシナリオに対して統計を実行し、解釈する方法を説明します。
統計ウィンドウでは、プロジェクトまたは選択したドキュメントに含まれる単語数、セグメント数、または文字数を確認できます。memoQはまた、あなたの翻訳メモリやライブ文書資料と比較して、すでに翻訳済みコンテンツや再利用可能なコンテンツの量を示します。
-
これを自動化できます:プロジェクトテンプレートから作成されたプロジェクトの場合、memoQは分析レポートを自動的に作成することができます。
-
さらに設定が必要な場合は統計ウィンドウを使用します:ローカルプロジェクトの概要やオンラインプロジェクトのレポートペインでは、より少ない設定でプロジェクト全体の分析レポートを迅速に作成できます。
-
翻訳メモリやライブ文書資料の一致を考慮して、どれだけの作業が必要かを把握するため。
-
ローカルおよびオンラインプロジェクトをカスタマイズされた設定で分析するため。
-
加重単語数に基づいて請求額を見積もるため。
memoQは、単語を一致カテゴリ(100%一致、95-99%など)によってグループ化します。各カテゴリには、どれだけの作業が必要かを表す加重があります(0% = 作業なし、100% = 完全な翻訳)。
例:10単語の90%マッチセグメントで50%の加重は、5単語の作業としてカウントされます。
操作手順
-
または、プロジェクトを作成してドキュメントをインポートします。
-
翻訳用にドキュメントを開きます - その一部を分析したい場合は。
-
文書リボンで、統計をクリックします。
-
統計ウィンドウが開きます。
オンラインプロジェクトを管理できるのは、memoQ TMSのプロジェクト管理者または管理者グループのメンバーである場合、またはプロジェクトでプロジェクト管理者役割を持っている場合のみです。
-
管理対象のオンラインプロジェクトを開きます。
または、オンラインプロジェクトを作成してドキュメントをインポートします。
-
memoQ オンラインプロジェクトウィンドウで、翻訳をクリックします。
-
準備リボンの統計をクリックします。
統計ウィンドウが開きます。
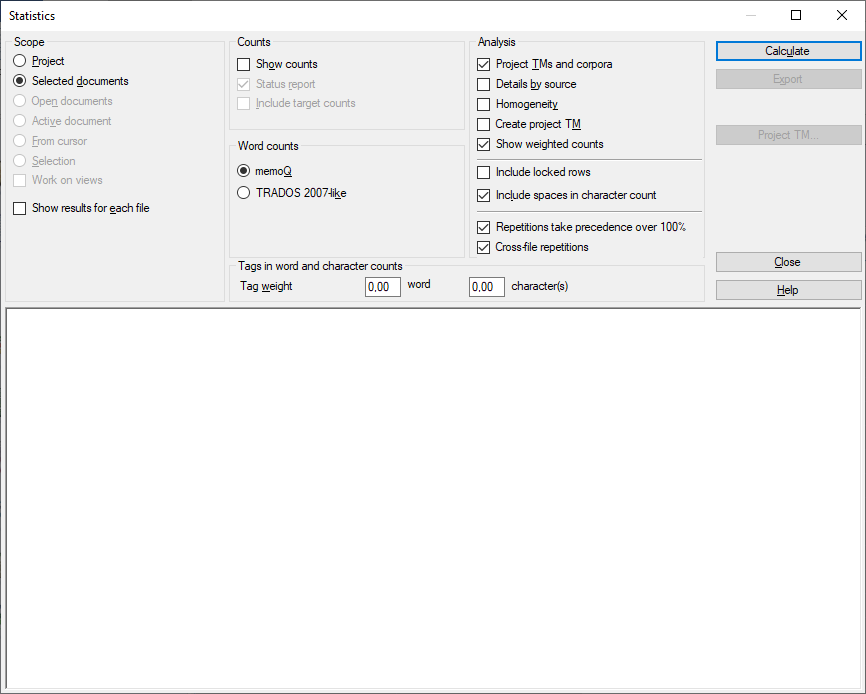
その他のオプション
対象とする文書の範囲をmemoQに指示します。
-
プロジェクト:現在のプロジェクトのすべてのドキュメント内のすべてのセグメント。プロジェクトに複数のターゲット言語がある場合、memoQはすべてのターゲット言語のセグメントをチェックします。
-
作業中の文書:アクティブなドキュメント内のすべてのセグメント。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
-
選択した文書:選択したドキュメント内のすべてのセグメント。プロジェクトホームにある翻訳で複数の文書を選択している場合のみこれを選択できます。
-
カーソル以降:アクティブなドキュメントの現在の位置以降のセグメント。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
-
開いている文書:翻訳エディタのタブで開いているすべてのドキュメントのすべてのセグメント。
-
選択:アクティブドキュメント内の選択されたセグメント。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
-
ビューで使用:現在のプロジェクトのビューにあるセグメント。プロジェクトに少なくとも1つのビューが存在する場合のみこれを選択できます。
1つのターゲット言語でセグメントを分析したいですか?統計ウィンドウを開く前に、翻訳ペインで言語を選択します。すべてのドキュメントを選択して統計を開き、選択した文書を選択します。
これらの設定はローカルプロジェクト用です。
自分で統計を実行する際は、分析レポートを作成 ウィンドウでこれらの設定を使用します:
-
プロジェクトTMと資料を使用してマッチを見つけます。memoQはプロジェクトのすべての翻訳メモリとライブ文書資料でセグメントを確認します。
-
均一性を使用して、繰り返しのセグメントを正しくカウントします。memoQは、翻訳メモリが増大していく翻訳中に何が一致するかを予測します。このオプションを使用するのは、翻訳を一人で行っている場合にのみ意味があります。
-
セグメントに翻訳すべきでないものがある場合はロックされた行を含めるをオフにします。
-
重複したセグメントが二重にカウントされないように繰り返しを100%一致よりも優先を選択します。これは、翻訳メモリから一致するものをすべて使用するよりも、一貫した翻訳が重要な場合にのみ使用します。
-
プロジェクトに複数のドキュメントがある場合は、クロスファイル繰り返しを使用し、ファイル間の繰り返しが認識されるようにします。
-
加重カウントを表示を選択して、実際の作業量の見積もりを見ることができます。
オンラインプロジェクトを管理?
統計をオンラインプロジェクトで実行している場合、memoQはmemoQ TMSの加重を使用します。
memoQ TMSに加重を設定するには、サーバーマネージャを使用します。加重カウントを選択し、加重をチェックまたは設定します。
これらの設定は、オンラインプロジェクト用です。プロジェクトマネージャで、プロジェクトをサーバーに公開するか、パッケージを使用してプロジェクトを配布する場合は、ローカルプロジェクトでも使用できます。
プロジェクトに複数の翻訳者が参加する場合は、分析レポートを作成ウィンドウでこれらの設定を使用します:
-
プロジェクトTMと資料を使用して一致を見つけます。memoQはプロジェクト内ですべての翻訳メモリとライブ文書資料のセグメントを確認します。
-
Homogeneityは使用しないでください。内部のファジーマッチを予測することはできません。なぜなら、誰が最初にセグメントを翻訳するか分からないからです。
-
翻訳者がロックされたコンテンツの作業をするのでない限り、ロックされた行を含めるは選択しないでください。
-
重複したセグメントが二重にカウントされないように繰り返しを100%一致よりも優先を選択します。これは、翻訳メモリから一致するものをすべて使用するよりも、一貫した翻訳が重要な場合にのみ使用します。
-
クロスファイル繰り返しをクリアしてください。誰が最初にセグメントを翻訳するかわからないので、翻訳に対して完全な報酬を受けるべきです。
-
加重カウントを表示を選択して、現実的な作業見積もりが表示されます。
翻訳者のチームが行った作業量を知るには、翻訳の完了後に翻訳後分析を実行します。
オンラインプロジェクトで統計を実行している場合、memoQ TMSの加重を使用します。
memoQ TMSに加重を設定するには、サーバーマネージャを使用します。加重カウントを選択し、加重をチェックまたは設定します。
一致分析なしで全体のテキストサイズの単純なカウントを取得するには:
-
プロジェクトTMと資料、均一性、および クロスファイル繰り返しチェックボックスをオフにします。
-
ロックされた行を含めると繰り返しを100%一致よりも優先を選択します。
編集者(校正者)は、一致に関係なく、すでに翻訳されたコンテンツで作業するため、翻訳メモリで作業を分析しても意味はありません。
-
プロジェクトTMと資料、均一性、および クロスファイル繰り返しチェックボックスをオフにします。
-
繰り返しを100%一致よりも優先を確認し、編集者がロックされたコンテンツをレビューする場合は、ロックされた行を含めるをオンにします。
一部の市場では、翻訳のボリュームを単語ではなく文字数で測定します。memoQは常にワードカウントと一緒に文字数を表示します。
スペースをカウントするには、文字カウントに空白を含めるを選択します。memoQはすべてのスペースを別々にカウントします。たとえば、連続して2つのスペースがある場合、それは1つではなく2つとしてカウントされます。
XML、HTML、PDF、InDesign、またはMicrosoft Wordのような形式には、多くのインラインタグを含むことが多く、編集の複雑さを増します。分析レポートには、それが反映されている必要があります。
タグに加重を割り当てることができます:
-
単語数または文字数でタグの加重を設定する
タグの加重フィールドで、単語数または文字ボックスに数字を入力します(例:タグごとに0.25単語またはタグごとに2文字)。
0.25と入力した場合、memoQはインラインタグが4つあるたびに1単語、または2と入力した場合、memoQはタグ1つにつき2文字とカウントします。
-
memoQは次にこれらの加重カウントをあなたの総作業負荷見積もりに加えます。
統計ウィンドウには、memoQにレポートに含める詳細を指示するいくつかのオプションがあります。
-
各ファイルの結果を表示はドキュメントごとにレポートを生成します。
-
カウントを表示は、セグメント、単語、文字の合計数を示します。
-
進捗レポートは、セグメントの状況(確定、編集済み、前翻訳、開始前)を表示します。
-
ターゲットの数も含めるは、ターゲットテキストのサイズに基づいて請求する場合に必要です。
オプションを設定したら、計算をクリックします。プロセスはプロジェクトのサイズによって数分かかる場合があります。
分析が完了すると、memoQは統計ウィンドウの下部に結果を表示します:
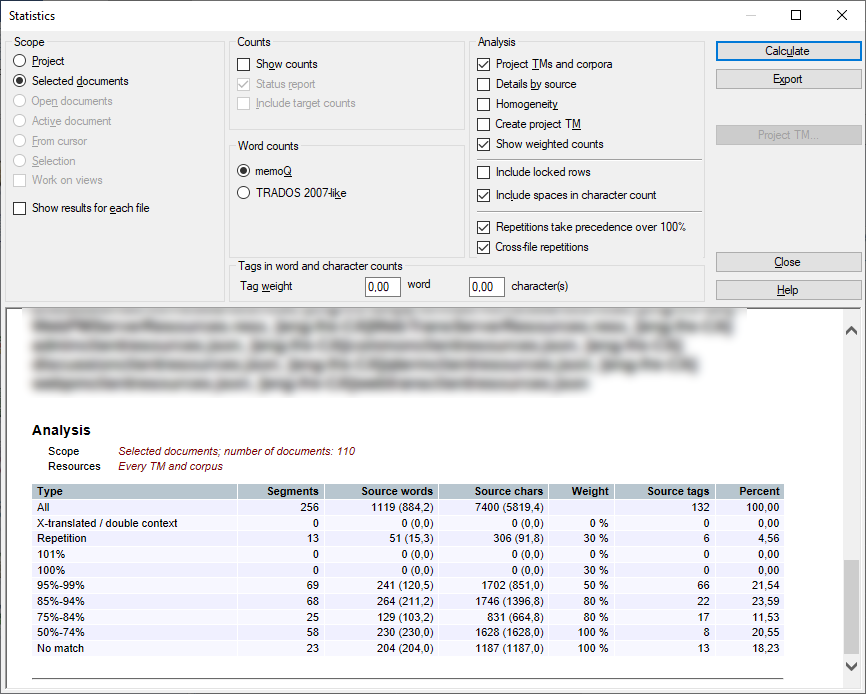
ここでレビューするか、複数の形式でレポートをエクスポートできます。
分析レポートをエクスポートして保存するには:
-
エクスポートをクリックします。統計結果のエクスポートウィンドウが開きます。
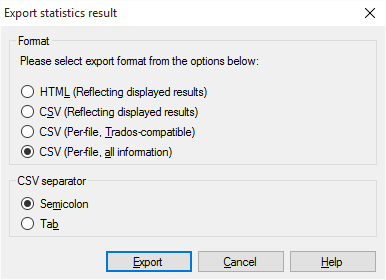
-
次のいずれかの形式を選択します:
- HTML (表示されている結果を反映):表示された統計情報をHTMLファイルとして保存します。
- CSV (表示されている結果を反映):結果をCSVファイルに保存します (Excelで開きます)。
- CSV (ファイルごと、Trados 互換):結果をCSVファイルに保存します。各ドキュメントの詳細は正確に1行になります。これは古いTradosスタイルです。
- CSV (ファイルごと、全情報):結果をCSVファイルに保存します。結果は統計ウィンドウとまったく同じようにレイアウトされます。
-
CSV形式のいずれかを選択した場合は、memoQがテーブル内の列を区切るために使用する区切り文字を選択できます。タブ文字以外を使用する理由はありません:CSV 区切り文字で、タブをクリックします。
-
エクスポートをクリックします。形式を選択して保存ウィンドウが開きます。レポートファイルのフォルダと名前を検索し、保存をクリックします。memoQはレポートをエクスポートし、統計ウィンドウに戻ります。
memoQは、分析中に見つかった翻訳メモリとライブ文書資料からすべてのセグメントを特別なプロジェクト翻訳メモリに収集し、再利用を容易にします。
そのためには:
-
分析を実行する前に、プロジェクト翻訳メモリを作成チェックボックスをオンにします。
-
分析を実行します:計算をクリックします。
-
翻訳メモリを保存します:プロジェクト TMをクリックします。プロジェクトTMのエクスポートウィンドウが開きます:
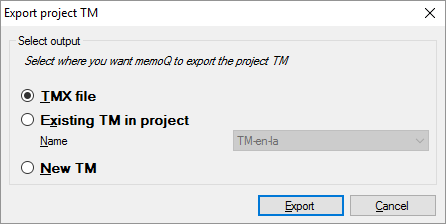
-
memoQがセグメントを置く場所を選択します:
- TMXファイルに保存して、別のコンピュータ上の別の翻訳ツールにインポートできます。
- プロジェクトに既に存在する翻訳メモリに保存できます。名前ドロップダウンボックスから、翻訳メモリを選択します。
- または、プロジェクトに新しい翻訳メモリを作成し、そこにセグメントを保存します。
-
エクスポートをクリックします。memoQはセグメントを保存します。
結果は2つの主要なセクションに分割されます:
-
総数 — 合計セグメント数、単語数、文字数を表示します。
-
分析 — 一致タイプとリソース(TM、均一性など)による詳細な内訳。
分析セクションを複数持つことができます。これは、プロジェクト内の翻訳メモリの数と、各ファイルの結果を表示またはソース単位での詳細チェックボックスの設定によって異なります。
範囲 - 範囲を選択セクションで選択した分析の範囲を示します。
リソース - 結果が取得されたリソースを示します。ここでは、均一性のチェックのための翻訳メモリや均一性が参照できます。集計結果の場合は、すべての翻訳メモリと資料、すべての翻訳メモリと資料または均一性キャプションが表示されます。
次の行が表示されます:
-
すべて - 全範囲(すべてのソースセグメント数、ソースワード数、文字数、およびソースワードカウントに基づく割合)。
-
クロス翻訳済み - 翻訳されたソースセグメント数、ソース単語数、文字数、およびソースワードカウントに基づく割合。
-
繰り返し - 繰り返されたセグメント(すべてのソースセグメント数、ソースワード数、文字数、およびソースワードカウントに基づく割合)。
-
パーセンテージによる一致範囲(例:95-99%)。
-
セグメント数、ソースおよびターゲットの単語数と文字数。
選択した範囲で分析が実行されます。例えば、プロジェクト内に2つの文書が含まれていて、その両方の文書に同じセグメントが1つ含まれている場合、プロジェクト範囲で計算された統計には、1つのセグメントが繰り返しとして表示されます。2つのドキュメントの統計を別々に計算した場合、結果には繰り返しは表示されません。
大きなプロジェクトを複数の翻訳者に分割する場合、この差は重要になります。プロジェクト全体としての統計を取ることで、異なるドキュメントのセットに比べて、繰り返しの率がはるかに高くなる可能性があるためです。
-
開始前:作業していないソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
前翻訳済み:前翻訳されたソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
フラグメント:フラグメント結合マッチのあるソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
編集済み:編集中のソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
翻訳者確定済み:確定済みのソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
レビュー担当者 1 確定済み:レビュー担当者1確定済みのソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
レビュー担当者 2 確定済み (校正済み):レビュー担当者2確定済みのソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
ロック済み:ロック済みのソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合。
-
パーセンテージ:これらの行には、同じカテゴリに属する一致があるセグメントのソースセグメント数、ソース単語数、文字数、およびワードカウントからカウントされたテキストの割合が表示されます。
たとえば、75-84%で5が表示されている場合、リソースがすべての翻訳メモリと資料で、範囲がプロジェクトであると、すべての翻訳メモリの組み合わせから5つのセグメントに対して75~84%の一致が得られることを意味します。
分析レポートの列:
各行(各種類)には次の行に値があります:
-
セグメント:選択した範囲のそのタイプのソースセグメント数。
-
ソースの単語数:選択した範囲のそのタイプのソース単語数。タグの加重が0でない場合は、実際の単語数よりも大きくなる可能性があります。
-
ソースの文字数:選択した範囲のそのタイプのソース文字数。文字数のカウントには、ホワイトスペースは含まれますが、未解釈の書式タグは含まれません。タグの加重が0でない場合は、実際の文字数よりも大きくなる可能性があります。
-
ソースのタグ:選択した範囲の、種類列で指定したセグメントにあるタグの数。
-
割合:選択した範囲内における、総単語数に対するこのカテゴリのソース単語の割合。丸め誤差があるため、すべての割合の合計は正確には100%になりません。
-
ターゲットの単語数:選択した範囲のそのタイプのターゲット単語数。この列は、ターゲットの数も含めるチェックボックスがオンになっている場合にのみ表示されます。
-
ターゲットの文字数:選択した範囲のそのタイプのターゲット文字数。この列は、ターゲットの数も含めるチェックボックスがオンになっている場合にのみ表示されます。
プロジェクトのすべてのターゲット言語に対して統計を実行すると、追加の詳細が表示されます。
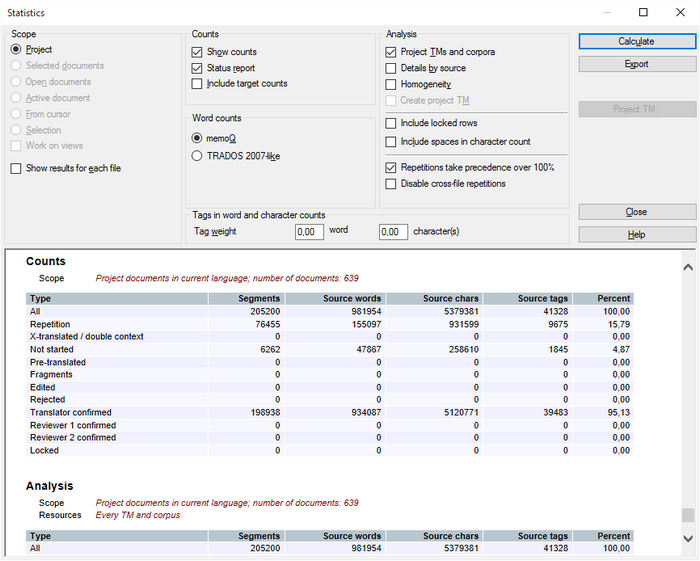
分析をエクスポートするときに、memoQはHTMLおよびCSV (表示されている結果を反映)オプションでターゲット言語ドキュメントごとに個別の行を追加します。CSV (ファイルごと、Trados 互換)またはCSV (ファイルごと、全情報)でエクスポートする場合、memoQは各ターゲット言語接頭辞が付いたCSVをエクスポートします。例:[ger] sample.txt
日本語や中国語のようなソース言語の場合(単語の間にスペースがない)、memoQは統計結果にソースがアジア言語以外の単語数およびソースがアジア言語の文字数の列を追加します。
memoQは次を表示します:
-
単語数の代わりにソースがアジア言語以外の単語数数。
-
結合されたソースの単語数列には、アジアの文字数と非アジアの単語数が含まれています。
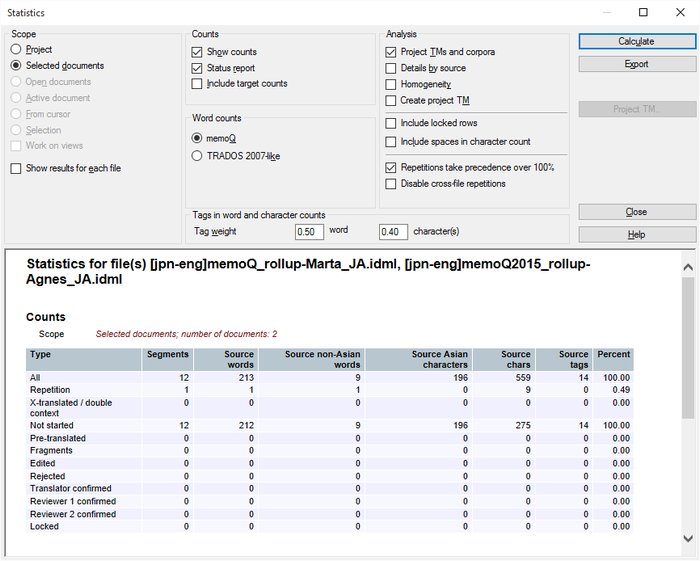
韓国語はスペースを使用するため、単語数のカウントはヨーロッパの言語と似ています。