新規用語の既定値
新規用語の既定値ウィンドウでは、用語ベース内のすべての新規エントリに対して、接頭辞一致のデフォルト設定や大文字/小文字の区別を選択できます。
操作手順
リソースコンソールから
-
memoQウィンドウの左上で、リソースコンソール
 アイコンをクリックします。リソースコンソールウィンドウが開きます。
アイコンをクリックします。リソースコンソールウィンドウが開きます。 -
リソースリストで、用語ベースをクリックします。
-
リストの下で新規作成/使用をクリックします。
または:リストまたは下のスペースを右クリックし、メニューで新規作成をクリックします。
既存の用語ベースに新しい用語のデフォルトを設定するには、用語ベースを右クリックし、メニューでプロパティをクリックします。
-
新規用語ベースまたは用語ベースのプロパティウィンドウが開きます。ウィンドウの下部にある新規用語の既定値リンクをクリックします。
ローカルプロジェクトから
-
ローカルプロジェクトを開きます。
-
プロジェクトホームウィンドウの左側で、設定をクリックします。
-
用語ベースリボンの新規作成/使用をクリックします。
または:リストまたは下のスペースを右クリックし、メニューで新規作成をクリックします。
既存の用語ベースに新しい用語のデフォルトを設定するには、用語ベースを右クリックし、メニューでプロパティをクリックします。
オンラインプロジェクトから
-
管理対象のオンラインプロジェクトを開きます。
-
memoQ オンラインプロジェクトウィンドウの左側で、設定をクリックします。
-
用語ベースリボンの新規作成/使用をクリックします。
または:リストまたは下のスペースを右クリックし、メニューで新規作成をクリックします。
既存の用語ベースに新しい用語のデフォルトを設定するには、用語ベースを右クリックし、メニューでプロパティをクリックします。
-
新規用語ベースまたは用語ベースのプロパティウィンドウが開きます。ウィンドウの下部にある新規用語の既定値リンクをクリックします。
新規用語の既定値ウィンドウが開きます。
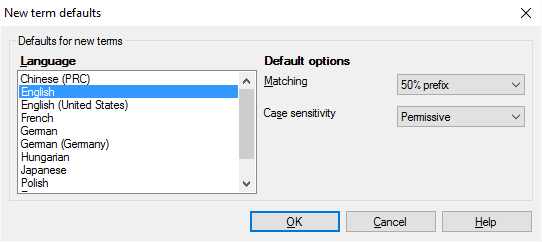
その他のオプション
言語一覧で、設定を変更する言語を選択します。
言語を選択すると、一致および大文字と小文字を区別の設定がその言語の新しい用語に適用されます。設定は言語ごとに異なる場合があります。
一致は、memoQがテキスト内の用語のバリエーションを認識する方法を制御します。たとえば、接頭辞や接尾辞が付いた形式などです。
一致ドロップダウンボックスで一致方法を選択します:
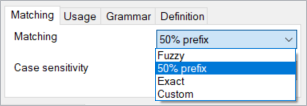

注意:青色の背景は認識された用語を示します。ハイライト表示されていない用語は、現在の設定では認識されません。
50% 接頭辞:これがデフォルト設定です。memoQは単語を最初から (1文字ずつ) 比較し、単語がエントリで始まる場合は単語を検索し、その単語に接尾辞を追加します。このオプションは、テキスト中の少なくとも前半の単語がその用語と一致する場合に、その単語に対する用語を表示します。使用例を見てみましょう:

使用方法の提案:さまざまな語尾や接尾辞を使用できますが、語尾や接尾辞がベースエントリよりも長い場合、つまり単語全体の50%を超える場合は使用できません。
50% 接頭辞一致の例:
- 用語「cat」は「cats」と一致しますが、「catnapping」(cat - 3 + napping - 7) とは一致しません
- 用語「review」は「reviewer」と一致しますが、「reviewability」(6+7) とは一致しません
- 用語「man」は「manner」と一致しますが、「maneuver」(3+5) とは一致しません
- 用語「Projekt」は「Projekte」および「Projektion」と一致しますが、「Projektverwaltung」(7+11) とは一致しません
- 用語「noc」は「nocnik」と一致しますが、「nocowanie」(3+6) とは一致しません
あいまい一致:用語の先頭、中間、または末尾が変化するバリエーションがある場合に使用します。memoQは、ソーステキスト内のフレーズが少なくとも80%類似している場合に、その用語を認識します。この場合、memoQは50% 接頭辞一致の場合のように開始文字ではなく、フレーズ全体を参照します。また、誤って入力された用語も認識します。
この設定では、他の設定よりも多くの一致が得られます。また、QA中に用語をチェックするときに多くの誤検出を検出するので、注意して使用してください。使用例を見てみましょう:
用語ベースエントリ:translate

単語は、ベースエントリと比較して追加の接頭辞 (「pretranslate」) で開始することも、接尾辞 (「translated」) を持つこともできますが、ベースエントリは変更されない必要があります。
使用方法の提案:接頭辞と接尾辞の両方に文法情報が含まれている言語や、複数の単語を含む式に使用します。
あいまい一致の例:
- 用語「Mutter」は、その複数形「Mütter」と一致します
- 用語「Baum」は、その複数形「Bäume」と一致します
- 用語「Anleitung」は、「Gebrauchsanleitung」と一致します
- 用語「board of directors」は、「boards of directors」と一致します
- 用語「manteau」は、「porte-manteau」と一致します
- 用語「system operacyjny」は、「systemu operacyjnego」や「systemie operacyjnym」と一致します
- 「superwoman」でさえ「superman」と一致します
完全一致:単語にバリエーションがない場合に使用します。memoQはソーステキストに完全に一致する単語がある場合、ソーステキスト内で単語を検索します。使用例を見てみましょう:
用語ベースエントリ:spell

使用方法の提案:固定された単語形式を持つ言語 (アラビア語など) や、あまり多くの一致を避けるのに役立ちます (必要な一致を見逃す可能性があります)。
カスタム:memoQがテキスト内の用語を検索する方法をより細かく制御できます。最も強力な味方はカスタムマッチングです。これを使用すると、単語が接尾辞を取得するときに語幹を少し変更できます。一致はベース用語で開始する必要がありますが、ワイルドカード (パイプ ('|') またはアスタリスク ('*') 文字) を使用すると、バリエーションを使用できます。用語にワイルドカード文字を少なくとも1つ入力すると、一致ドロップダウンボックスは自動的にカスタムに切り替わります。
このドキュメントでは、「ステム」は語幹を意味しますが、言語学的な意味合いではありません。これは単に、ワイルドカードの前の単語部分です。
ワイルドカードを使用して、用語ベースの精度を高め、QA中の誤検出を減らします。
'*' と '|' の違いは何ですか?
アスタリスク '*'
- ステムの後の任意の数の文字と一致します
- 翻訳結果ではステムのみが表示されます
- 単語の末尾に配置して、単語の接尾辞の形式と一致させます
- また、接頭辞の付いた形式に一致する単語の前に置くこともできます
パイプ '|'
- ステムの後の任意の数の文字と一致します
- 完全に一致した用語が翻訳結果に表示されます
- 単語の真ん中に置いて、ステムをマークすることができます
- 代替語尾を定義することができます
- ステムで始まるすべての用語に一致するが、ステムそのものには一致しません
ステムが同じ場合、パイプまたはアスタリスクを使用すると、まったく同じ単語に一致しますが、異なる部分がハイライトされ、翻訳結果ペインに異なる候補が表示されます。
使用例を見てみましょう:
用語ベースエントリ:text*

用語ベースエントリ:program|ming instruction|s

使用方法の提案:柔軟で長い語尾を持つ言語では、異なる単語形式を認識します。また、複合単語を一緒に記述する傾向のある言語でも使用できます。
カスタム一致の例:
パイプ '|' 付き
- 用語「glorif|y」は、「glorify」または「glorifies」または「glorified」に一致します
- 用語「articula|tion」は、「articulations」、「articulaire」、「articulatoire」に一致します
- 用語「Wassert|urm」は、「Wasserturm」、「Wassertürme」、「Wassertropfen」と一致しますが、「Wasserschutz」とは一致しません
- 用語「flick|a」は、「flicka」、「flickor」に一致します
- 用語「wrażliw|ość sensoryczn|a」は、「wrażliwy sensorycznie」、「wrażliwości sensoryczne」に一致します
アスタリスク '*' 付き:
- 用語「tid*」は、「tid」、「tider」、「tidning」に一致します
- 用語「*tid」は、「kvällstid」、「dagtid」に一致します
- 用語「*tid*」は、「tider」、「dagtid」、「kvällstidning」、「partidagar」に一致します
- 用語「*piec*」は、「przypiec」、「pieczątka」、「pieczęć」、「zapiecz」に一致します
- 用語「*dać」は、「dodać」、「zbadać」に一致します
パイプ '|' とアスタリスク '*' を同時に使用することも可能です:
- 用語「beautiful* writ|ing」は、「beautifully written」に一致します
- 用語「program|mer guide*」は、「programmer's guide」、「programming guides」や「program guide」に一致します
- 用語「gul|t hårstrå*」は、「gult hårstrå」や「gula hårstrån」に一致します
詳細については:用語ベースエントリの編集についてのドキュメントの記事を参照してください。
用語の一致で、memoQは大文字の一致を厳格にすることも鈍感することもできます。大文字と小文字を区別するかどうかは、用語ごとに個別に設定できます。
用語リストの下にある一致タブの大文字と小文字を区別ドロップダウンボックスで大文字と小文字を区別するかどうかを選択します。
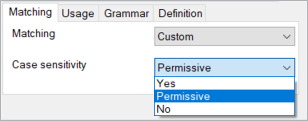
大文字と小文字を区別のオプションは次のとおりです:
![]()
Permissive - これがデフォルト設定です。大文字が同じ場合、用語はテキストで一致します。用語中の小文字はテキスト中で大文字でも一致します。ほとんどの固有名詞でこの設定を使用します。
用語ベースエントリ:Editor-in-chief

その他の例:
- 「it」は「it」、「IT」、「It」に一致します。
- 「sample」は「sample」、「Sample」、「SAMPLE」と一致します。
- 「memoQ」は「MEMOQ」または「MemoQ」と一致しますが、「memoq」または「Memoq」とは一致しません。
はい - テキスト内の単語と大文字と小文字が同じ場合にのみ、用語はテキストと一致します。「TBD」や「XML」などの略語に使用します。実際の動作を見てみましょう:
用語ベースエントリ:memoQ

その他の例:
用語ベースの「IT」は、ソーステキストに「IT」が大文字である場合にのみ表示され、「it」では表示されません。
用語ベースの「Can」は、ソーステキストに「Can」と大文字のCが含まれている場合にのみ表示され、「CAN」や「can」では表示されません。
いいえ - テキストが同じ場合、または大文字と小文字だけが異なる場合は、この用語はテキストと一致します。この設定は、一般的な単語に使用します。
用語ベースエントリ:CAT

その他の例:
「translation」は「Translation」、「TRANSLATION」、または「TranslatioN」に一致します。
先頭が大文字の用語集をインポートする場合は、必ずいいえに設定してください。大文字と小文字の区別で甘いを使用した場合、memoQはこれらの用語のすべて小文字の形式を認識しません。同じ問題は、センテンスの最初の単語 (大文字の頭文字) を用語ベースに追加した場合にも発生します。
詳細については:用語ベースエントリの編集についてのドキュメントの記事を参照してください。
ある言語の設定を選択した後、別の言語を選択し、その言語の設定も選択できます。
完了したら
変更を保存して新規用語ベースまたは用語ベースのプロパティウィンドウに戻るには:OK(O)をクリックします。
新規用語ベースまたは用語ベースのプロパティウィンドウに戻り、これらの設定を変更しない場合は:閉じる(_C)をクリックします。