用語ベースのCSVインポート設定
ほとんどの場合、インポートするファイルには、memoQが期待するすべての列は含まれていません。
列に名前がある場合とない場合があります。用語ベースのCSVインポート設定ウィンドウでは、名前の有無にかかわらず、列を用語ベースフィールドに変換できます。
テキストファイルをインポートする場合、文字エンコーディングも問題になります。用語ベースのCSVインポート設定ウィンドウにプレビューが表示され、すべての文字が適切に表示されるかどうかを確認できます。
ここではExcelファイルをインポートしないでください。memoQはExcelを直接インポートできます:ExcelシートをmemoQ用語ベースにインポートするには、Excelファイルをプレーンテキスト形式で保存する必要はありません。直接インポートできます。詳細については:用語ベースのExcelインポート設定ウィンドウについてのヘルプを参照してください。
操作手順
- プロジェクトを開きます。プロジェクトホームで、用語ベースを選択します。
リソースコンソールから:リソースコンソールを開きます。用語ベースを選択します。
オンラインプロジェクトから:プロジェクトマネージャは、管理用にオンラインプロジェクトを開くことができます。memoQ オンラインプロジェクトウィンドウで、用語ベースを選択します。
- 新しい用語ベースに用語が必要な場合は、まず用語ベースを作成します。
- 用語をインポートする必要がある用語ベースの名前を右クリックします。メニューから用語集をインポートを選択します。
- 開くウィンドウが表示されます。インポートする必要のあるファイルを見つけます。開くをクリックします。
ファイルがプレーンテキストファイル (単独、またはイメージと一緒に圧縮) の場合、用語ベースのCSVインポート設定ウィンドウが開きます。
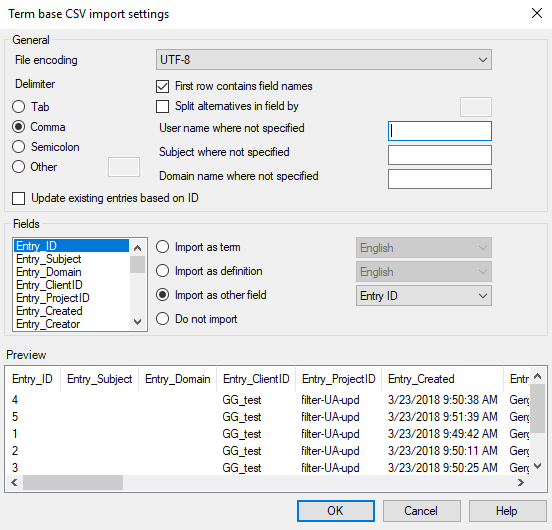
その他のオプション
現在、ほとんどの場合文字はUnicodeでエンコードされています。Unicodeでは、ほとんどすべての文字や記号をエンコードできます。
プレーンテキストファイルでは、より単純で古いエンコーディングが使用される場合があります。インポートするファイルがUnicodeでない場合は、
下部のプレビューボックスですべての文字が正しく表示されているか確認します。そうでない場合は、ファイルのエンコード(E)ドロップダウンボックス (上部) から別のエンコーディングを選択します。文字が正しく表示されるまで試してみる必要があるかもしれません。
memoQはファイルから区切り文字を選択します。表形式のテキストファイルでは、区切り文字によって列 (セル) が区切られます。
適切でない場合は、別のデリミタを選択する必要があります。
タブまたはカンマまたはセミコロンまたはその他をクリックします。その他をクリックした場合は、その横のボックスに、ファイルで使用する区切り文字を入力します。
別の区切り文字を選択したら、もう一度プレビューを確認します。
memoQは、テーブルの各行を用語ベースの新しいエントリとしてインポートします。
各列は、用語ベースのフィールドにインポートされます。
ファイルに列ヘッダーがある場合、memoQはすべての列に対して正しいフィールドを見つけようとします。
これを動作させるには、先頭行をフィールド名として使うチェックボックスをオンにします。
1つのセルに2つ以上の用語がありますか?1つの列に1つの用語だけでなく、複数の選択肢が含まれている場合でも、それらの分けられ方が分かれば、memoQはそれらをインポートすることができます。これは別の区切り文字でなければなりません (列を区切る文字ではありません)。このような選択肢がある場合:候補を次のフィールドで分割チェックボックスをオンにして、その横のボックスに文字を入力します。
列とフィールドを一致させるには、フィールドの設定を使用します。
各フィールドに対して、インポート方法を選択します。フィールドは、表のカラムです。フィールドでは、CSVファイル内のフィールドを用語ベースエントリのフィールドと一致させる (または一致させない) ことができます。(CSVファイルからフィールドを省略できます。)
- フィールドリスト:一覧表示されているフィールド名をクリックし、インポートする方法を選択します。コントロールでのすべての変更は、リストで現在選択されているフィールドに適用されます。
- 用語としてインポート:選択したフィールドのコンテンツを用語としてインポートするには、このオプションを選択し、ドロップダウンから言語を選択します。
- 定義としてインポート:選択したフィールドのコンテンツを定義としてインポートするには、このオプションを選択し、ドロップダウンから言語を選択します。
- 別のフィールドとしてインポート(F):選択したフィールドのコンテンツを、サブジェクト、ドメイン、メモ、作成日、作成者、最終更新日または最終更新者としてインポートするには、このオプションを選択します。
- インポートしない:選択したフィールドの内容をインポートしない場合には、これをクリックします。
列およびフィールドでは、用語は「用語」とは呼ばれません:それはその言語で呼ばれます。memoQが用語をインポートするとき、memoQは「用語 (Term)」という単語ではなく、その言語の英語名を列ヘッダーで探します。
memoQがすぐに使えるテーブルを作りたいですか?memoQで使用されているフィールド名を調べるには:memoQから用語ベースをCSVファイルにエクスポートします。Excelでファイルを開き、列ヘッダーを確認します。
表の最初の行に次の列ヘッダーが含まれている場合、memoQは自動的にフィールドを検出できます:
- Entry_ID:エントリの識別子 (通常は番号)。手動でテーブルをまとめる場合は、これを使用する必要はありません。
- Entry_Subject:エントリのサブジェクトフィールド。
- Entry_Domain:エントリのドメイン。
- Entry_ClientID:エントリに関係するクライアントの名前または識別子。
- Entry_ProjectID:エントリが属する大きなプロジェクトの名前または識別子。これをmemoQのプロジェクトと混同しないでください。
- Entry_Created:エントリの作成日時が表示されます。例:12/2/2015 11:12:36 AM。手動でテーブルをまとめる場合は、これを使用する必要はありません。memoQはシステムから入力できます。
- Entry_Creator:エントリを作成したユーザーの名前。手動でテーブルをまとめる場合は、これを使用する必要はありません。memoQはシステムから入力できます。
- Entry_LastModified:エントリが最後に修正された日時です。手動でテーブルをまとめる場合は、これを使用する必要はありません。
- Entry_Modifier:最後にエントリを変更したユーザーの名前。手動でテーブルをまとめる場合は、これを使用する必要はありません。
- Entry_Note:エントリ全体に属するコメントです。
- Entry_Image:エントリ全体に属するイメージのフォルダおよびファイル名。ファイル名は1_で始まる必要があります。
- <language>:指定された言語の用語。言語名は英語で、memoQがサポートしている言語の1つでなければなりません。サポートされている言語のリストを参照してください。同じ行には、同じ言語に対して複数の用語と関連フィールドが存在する場合があります。
- <language>_Def:指定された言語での概念の定義。言語名は英語で、memoQがサポートしている言語の1つでなければなりません。サポートされている言語のリストを参照してください。
-
Term_Info:この列には、必ずいずれかの言語の用語の次に置いてください。これには、「大文字と小文字を区別」の一致設定とそれに続く「接頭辞の一致」が含まれます。例:"CasePermissive;カスタム"
有効な値は次のとおりです:
- 大文字と小文字を区別:CasePermissive; CaseSensitive; CaseInsense
- 接頭辞の一致:HalfPrefix;完全一致;あいまい一致;カスタム
- Term_Example:この列には、必ずいずれかの言語の用語の次に置いてください。用語の使用例が記載されています。
一部のエントリは追加ではなく、更新される必要がある場合:これは、
これらのメタデータがテキストファイルにない場合でも、新しいエントリに追加できます。
指定されていない場合のユーザー名(U)、指定されていないサブジェクト、および指定されていない場合のドメイン名(D)ボックスに詳細を入力します。
これらの詳細がテキストファイルにある場合:memoQはここに入力したものではなく、それらを使用します。
完了したら
用語ベースにテキストファイルをインポートし、プロジェクトホームまたはリソースコンソールに戻るには:OK(O)をクリックします。
CSVに用語ベースにない言語が含まれている場合は、追加することができます。
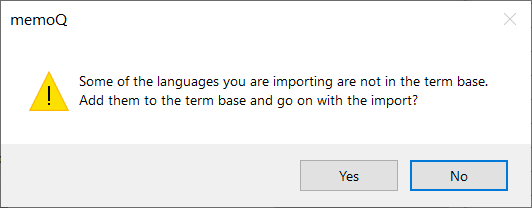
言語を追加してインポートを続行するには、
用語ベースのCSVインポート設定ウィンドウに戻るには、いいえをクリックします。
エントリをインポートせずに、プロジェクトホームまたはリソースコンソールに戻るには:キャンセル(C)をクリックします。
インポート後に用語ベースの重複するエントリがある可能性があります:重複したエントリを削除するには、用語ベースを開いて編集します。用語ベースエディタで、重複する用語をフィルタします。詳細については:用語ベースエディタのヘルプを参照してください。