正規表現
正規表現は、テキスト内の文字シーケンスを検索するための強力な手段です。memoQでは、セグメンテーションルール、自動翻訳ルール、または正規表現タグ化ツールのルールを定義するために使用されます。正規表現は、検索と置換や、翻訳エディタのフィルタフィールドでも使用できます。
文字列の検索は、ワードプロセッサやテキストエディタを使用していたユーザーにとっては良く知られているタスクです。検索または検索ダイアログで、もし「cat」を検索すると、「cat」、「cats」、「sophisticated」などの単語 (または単語の一部) が強調表示されます。
正規表現を使用すると、検索する単語をより自由に指定することができます。2、3文字の「c」の後に続く文字「a」、1桁以上の複数の数字を含む、または「cat」、「dog」や「mouse」のいずれかの単語を含むなど、特定のシーケンスを識別できます。さらには引用符の間にある単語の出現などのシーケンスを識別できます。このページを参照し、例を試すことで、正規表現について理解を深めることができるはずです。詳細を学習する準備ができていない場合は、正規表現アシスタントがお手伝いします。
注意:正規表現は、パターンマッチング法の基礎となっている数学的理論に由来しています。regexpやregexなどの省略系で表示されることが多いですが、ここでは、正規表現を使用します。
リテラルとメタ
ワープロの昔ながらの検索機能では、すべての文字は文字通りに解釈されます。「Yes? No...」を検索すると、「Yes? No...」が強調表示されるか、テキストにこれらの文字がない場合には、何も強調表示されません。正規表現では、特別な意味を持つ文字があります。これらはメタ文字と呼ばれます。最も重要なメタ文字:
|
表現 |
説明 |
|---|---|
|
. |
すべての文字に一致します。 |
|
| |
左側か右側の表現がターゲット文字列に一致します。たとえば、「a|b」は「a」と「b」に一致します。 |
|
[] |
[] 内のすべての文字は、ターゲット文字に一致します。たとえば、「[ab]」は「a」と「b」に一致します。'[0-9]' はあらゆる数字に一致します。 |
|
[^] |
[] 内のどの文字も、ターゲット文字に一致しません。たとえば、「[^ab]」は「a」と「b」を除くすべての文字に一致します。'[^0-9]' は数字でないすべての文字に一致します。 |
|
* |
表現内のアスタリスクの左側の文字は、0回以上一致すべきです。たとえば、「be*」は「b」、「be」と「bee」に一致します。 |
|
+ |
表現内の+記号の左側の文字は、1回以上一致すべきです。たとえば、「be+」は「be」と「bee」に一致しますが、「b」には一致しません。 |
|
? |
表現内のクエスチョンマークの左側の文字は、0回または1回一致すべきです。たとえば、「be?」は「b」と「be」に一致しますが、「bee」には一致しません。 |
|
{num} |
かっこ内の数字の左側の文字は、numの回数一致すべきです。たとえば、「be{2}」は「bee」に一致しますが、「be」には一致しません。 |
|
() |
グループを作成し、文字列の一致セクションを「記憶します」。グループは、文字列の一部を再配列するために使用できます。例:日付を異なるフォーマットに変換するときなど |
|
\ |
エスケープ文字。エスケープ文字文字列「\」自体を使用したい場合には、「\\」を使用してください。 |
混乱していますか?この表は、短い概要と参照のみを表しています。これらの表現すべての意味は、以下のセクションに分類できます。
次に、ドットに焦点を当ててみましょう。正規表現では、「ここに入るあらゆる文字」を意味します。つまり、正規表現では、「No...」は以下のすべてと一致します:
- Notes
- Notte
- No...
- No&%X
では、「No...」という文字列のみに正確に一致するよう、正規表現を記述するには、どのようにしたら良いでしょうか?特別な意味を持つ文字列を使用するには、それを「エスケープ」する必要があります。つまり、前にバックスラッシュを付けます。このように、「No\.\.\.」は「No...」と完全に一致し、その他には一致しません。
正規表現をテストするには
memoQでは、検索と置換でも正規表現が使用できます。Ctrl+Fキーを押して、翻訳するドキュメントを開いて正規表現を試すことができます。[次を検索] ボックスに正規表現を入力し、[次を検索] をクリックします。
また、正規表現を使用して、翻訳エディタでドキュメントをフィルタすることもできます。翻訳グリッドのすぐ上で、[正規表現を使用] ![]() アイコンのチェックボックスをオンにし、ソースセグメントまたはターゲットセグメントの上にあるフィルタボックスに正規表現を入力します。Enterを押します:memoQは、正規表現に一致するセグメントを表示します。たとえば、数字の後にドットが続くセグメントをフィルタする方法を次に示します:
アイコンのチェックボックスをオンにし、ソースセグメントまたはターゲットセグメントの上にあるフィルタボックスに正規表現を入力します。Enterを押します:memoQは、正規表現に一致するセグメントを表示します。たとえば、数字の後にドットが続くセグメントをフィルタする方法を次に示します:
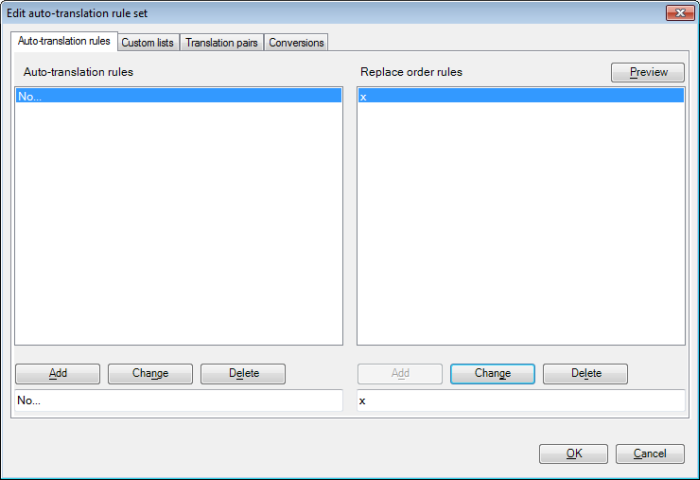
正規表現を学習する際に、memoQからのより詳細なフィードバックが必要な場合は、自動翻訳ルールを「乱用」して実験するためのコツを紹介します。テストプロジェクトを作成し、プロジェクトホームの設定ペインで自動翻訳ルールタブをクリックします。表示されるダイアログで、そこにあるすべてのルールを削除し、独自のルールを入力します。そのルールに対して、置換順序のルールを追加します。以下のように入力されたダイアログが表示されます。(置換順序のルールについて、およびそのルールが必要な理由については、以下で説明します。)
次に、プレビュー(P)をクリックし、下のように自動翻訳前ボックスにのテキストを入力し、プレビュー(P)ボタンをクリックします。以下のように表示されます。
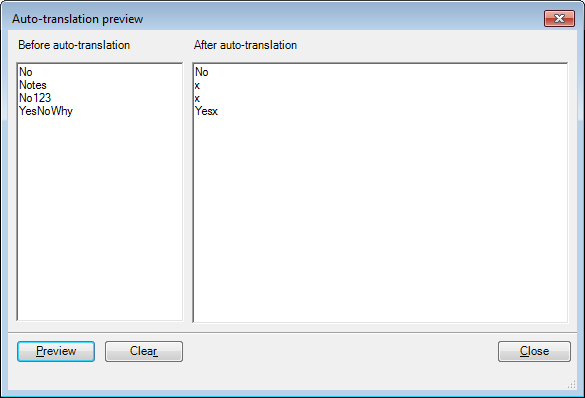
置換順序のルールフィールドの「x」は、指定された正規表現と一致するテキストを文字「x」で置き換えるようmemoQに指示します。これが、この実験で正規表現が動作していることを示すものです。[自動翻訳プレビュー]ダイアログでは、テキストのどの部分が「x」で置換されるのかを参照でき、使用した正規表現をテストすることができます。
文字クラス
ドットを網羅し、新しい正規表現の方法の試し方も勉強しました。次はもう少し難しい表現に進みましょう。正規表現にかっこを使用することで、一連の文字列または文字クラスを指定できます。「[ab][01]」は、「a」または「b」で始まり、「0」または「1」で終わる0文字のシーケンスに一致します。この例では、4つの一致(「a0」、「b0」、「a1」、「b1」)が考えられます。
文字クラスは、「カンマまたは感嘆符に続く1桁」のようなもの(たとえば「[0123456789][,!]」のように表記)を表現するために使用できます。ただし、これでは記述するのが大変です。正規表現では、更に詳細を識別できます。「[0-9][,!]」と記述することで、前述の表現と全く同じ文字領域を指定できます。
注意:範囲を使用して「任意のアルファベット文字に一致」と言えるか?「はい」であり「いいえ」でもあります。これを行うための典型的な解決策は、「[a-z]」でした。これはaとzの間の任意の文字に一致します。しかしながら、memoQはさまざまな言語に対応しています。各言語のアルファベットには、特殊な文字も含まれている場合もあります。たとえば、アイスランド語の「đ」は、「a-z」の範囲には含まれません。このため、memoQでは特別な拡張子を使用して、アルファベット文字を処理します。
それについては、以下で説明します。また、memoQの正規表現のすべての文字は、大文字と小文字を区別して解釈されます。このように、「[a-z]」は「f」に一致しますが、「f」には一致しません。
一致させたい文字を指定する他に、一致しない文字を指定するために文字クラスを使用することもできます。正規表現「[^0a].」は、最初の文字が「0」または「a」でない限り、無数の2文字の文字列に一致します。
エスケープシーケンス
上記のように、先頭にバックスラッシュ(「\」)を付けることで、特殊なメタ文字の元の意味を指定できます。他にも実用的なエスケープシーケンスがあります。memoQで使用されている正規表現の目的にとって最も重要なものは次のとおりです:
|
シーケンス |
説明 |
|
\s |
スペース、タブ、または改行 |
|
\S |
空白以外なら何でも |
|
\t |
タブ |
|
\n |
改行 |
|
\d |
数字(0と9の間) |
|
\D |
数字以外なら何でも |
|
\w |
英数字とアンダースコア |
|
\W |
英数字以外なら何でも |
数量子
与えられた位置に一致する一連の代替文字列を指定する方法を勉強しました。次は、一致する文字列の数を指定してみましょう。これには、「*」や「+」のような特殊文字と表現{num}を使用します。
- 正規表現「x+」は、1以上の「x」から成る一連の文字列に一致します(つまり、「x」、「xx」、「xxx」など)。
- 正規表現「x{3}」は、3つの「x」から成る一連の文字列に一致します(つまり、「xxx」。「x」や「xx」ではない)。テキストが「xxxx」の場合には、正規表現では最初の3つの「x」は一致し、4つめは無視されます。表示: 「xxxx」。通常の[検索]ダイアログは、「cats」の中で「cat」という単語を見つけます。
- 数量子{num} は、最小または最大値(またはその両方)を指定することで、使用できます。「x{3,5}」は、3~5つの「x」に一致します。「x{3,}」は、3つ以上の「x」を含むシーケンスと一致し、「x{,5}」は、5つ以内の「x」を含むあらゆるシーケンスと位置します。
- おそらく、数量子の中でも特徴のあるのは、アスタリスク (「*」)でしょう。アスタリスクは、「0または与えられた文字以上の」という意味です。では、アスタリスクはどのように使用するのでしょうか?「0個以上の「a」で始まる「T」という文字に一致」などというように指定できます。相当する正規表現は、「a*T」で、「t」、「aT」、「aaT」などに一致します。
- 同じく重要なものに、疑問符があります。これは、0または1つのその文字で始まるシーケンス一致するという意味です。このように、「ax?y」は「ay」と「axy」に位置しますが、「axxy」には一致しません。
次に、文字セットと数量子を組み合わせて見ましょう。文字のすぐ後に、一連の文字列の後に数量子を書くことができます。「[0-9]+%」は、数字で始まり%記号が続くシーケンスと一致します(例:「1%」または「99%」と一致しますが、「10a%」とは一致しません)。
グループと代替
文字セットと数量子について説明しました。残っている標準的な正規表現の機能は2つだけです:グループと代替です。
パイプ記号(「|」)を使用すると、「これか、あれかまたはその他のいずれかに一致する」というように、複数の小さな正規表現をつなぐことができます。正規表現「EUR|USD|GBP」は、これらの単語のどれにも一致し、これらのみに一致します。
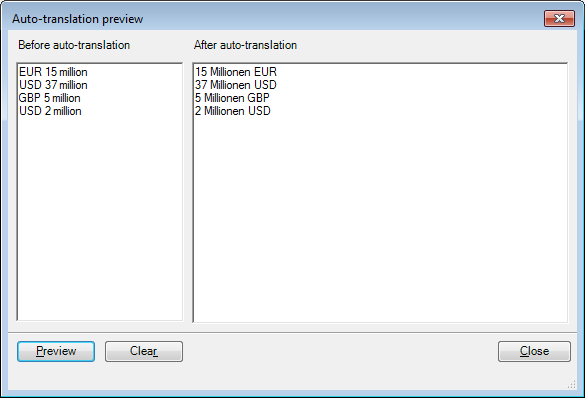
別の選択を使用する場合、希望する結果を得るよう、丸かっこでかこむ必要があります。これらの表現のいずれかに一致する正規表現が必要とします。'「EUR 15 million」、「USD 37 million」、「GBP 5 million」。まずは、「EUR|USD|GBP \d{1,} million」と入力してみます。ただし、この場合には以下の文字列のみに一致します。'「EUR」、「USD」、「GBP [any natural number] million」。正規表現「(EUR|USD|GBP) \d{1,} million」で代替をグループ化する必要があります。「EUR|USD|GBP」は、「EUR」または「USD」または「GBP」のいずれかで、「\d{1,}」は0から始まるあらゆる自然数が考えられます。
置換と再配置
セグメント化のために、memoQでは、翻訳文書のテキスト内でパターンを一致させるために正規表現のみを使用しています。自動翻訳ルールに対しては、グループと関係のある強力な別の正規表現機能(一致したテキストの置換および並べ替え)を利用することもできます。
- 一致したテキストと1つの文字列を置換:
このページの「テスト方法」セクションでは、置き換えの可能性についてすでに説明しています。そこで、簡単な「x」の置換ルールを定義して、テスト目的で、「x」という文字を含む正規表現一致を置換してみましょう。
- 一致したテキストの一部を再配置する/または置換する:
ここで、その正規表現のすべての部分を丸かっこで囲む必要があります。丸かっこで囲まれた一致はmemoQによって記憶され、1で始まる数字が割り当てられます。配置順序ルールを書く際、これらの記憶されたサブ文字列を「$1」、「$2」などで、正規表現内の左丸かっこの位置順に参照できます。
前の正規表現の例を使用する場合、これらの通貨と考えられる値「(EUR|USD|GBP) (\d{1,}) million」の配置を変えるために、「\d{1,}」もかっこに入れる必要があります。配置順序ルールでは、「$1」で「EUR|USD|GBP」を、「$2」で「\d{1,}」を参照できます。これらの順序を変更する場合には、置換順序ルールは「$2 Millionen $1」になります。
memoQでの拡張
タグの検索
正規表現でタグを検索する場合は、次の3つの特別なエスケープシーケンスを使用してそれらを一致させることができます:
- \tag:すべてのタグに一致します
- \itag:インラインタグ (次のように五角形または六角形で表示されるタグ) と一致します:
- \mtag:memoQタグ (テキストの {中括弧} 内に表示されるタグ) に一致します
タグは通常、タグの前または後にあるテキストと結合されるため、タグとテキストの組み合わせを検索する場合は、括弧「()」にタグを入れることをお勧めします。例:「(\itag)int」は、インラインタグ (開始、終了、空のいずれか) の後に「integrated」、「interesting」、「intentional」などの単語が後に続くと一致します。
カスタムリスト
セグメンテーションと自動翻訳ルールを定義するために、通常は単語のリスト(略語、月の名前、通貨など)を使用します。理論的には、前のセクションのように、これらの単語を代替として正規表現でグループ化することも可能です。ただし、これを行うと、正規表現の維持が非常に複雑で困難になります。そのため、memoQでは正規表現に特別な拡張が導入されています:カスタムリストです。
正規表現で使用される単語のリストは、[セグメンテーションルール] ダイアログボックス、[自動翻訳ルール] ダイアログボックスのカスタムリストタブ、または [自動翻訳] ダイアログボックスの 翻訳ペアタブで定義できます。
- [セグメンテーションルール] ダイアログのカスタムリストタブにあるカスタムリストには、セグメンテーションに重要な文字や略語(「.」、「!」や「e.g.」など)が含まれている必要があります。
- [自動翻訳] ダイアログのカスタムリストタブにあるカスタムリストには、ソースとターゲットで同じ形式の単語(「€」、「$」など)が含まれている必要があります。
- [自動翻訳] ダイアログの翻訳ペアタブ内のカスタムリストには、ソース単語とそれに対応するターゲット単語が含まれている必要があります (例えば、英独プロジェクトでは、「January」は「Januar」、「February」は「Februar」などと訳されます)。
カスタムリストの名前は、常にハッシュ記号(「#」)で始まる必要があります。カスタムリストを構成する単語は、常にテキストとして解釈されます(つまり、特殊な意味を持つメタ文字としては処理されません)。
注意:セグメンテーションルールに対して、memoQはもう1つの特殊項目「#!#」を定義します。この例外は、正規表現の一致には影響しません。代わりに、memoQは、インポートされた文書にその表現が一致する場合に、指定された位置にセグメント区切りを入れるよう伝えます。
自動翻訳ルールダイアログボックスの カスタムリストタブのカスタムリストの使用例
翻訳結果で「EUR 15 million」に対しては「15 Millionen EUR」を、「USD 37 million」に対しては「37 Millionen USD」を提案して欲しい場合。「EUR」、「USD」および「GBP」を含む「カスタムリスト」タブで「#currency#」というラベルのカスタムリストを作成します。
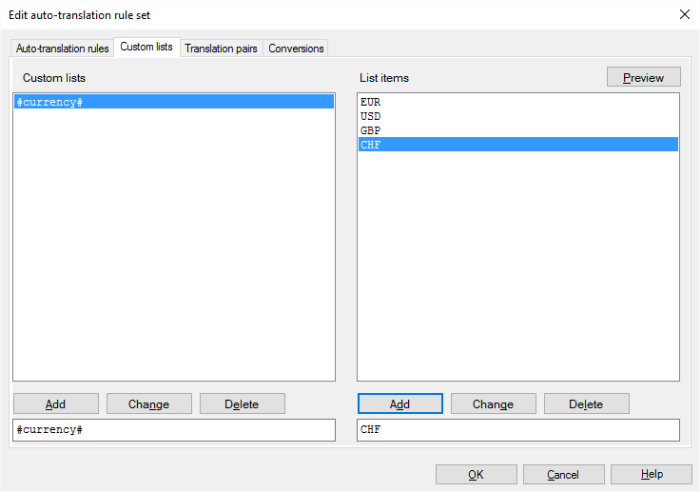
次の正規表現「(#currency#) (\d{1,}) million」(「(EUR|USD|GBP) (\d{1,}) million」と同等)を作成し、置換順序ルールは「$2 Millionen $1」にします。上記正規表現と置換順序ルールのプレビューは、以下のようになります:
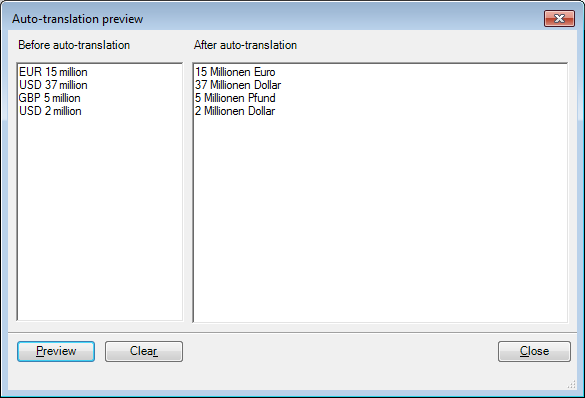
翻訳ペア
翻訳結果で「EUR 15 million」に対しては「15 Millionen Euro」を、「USD 37 million」に対しては「37 Millionen Dollar」を提案して欲しい場合。翻訳ペアタブで「#currency2#」というラベルのカスタムリストを作成し、次の翻訳ペアを含めます:「EUR」–「Euro」、「USD」–「Dollar」、「GBP」–「Pfund」。
注意:翻訳ペアリストの名前は、カスタムリストの名前とは異なるものにする必要があります。
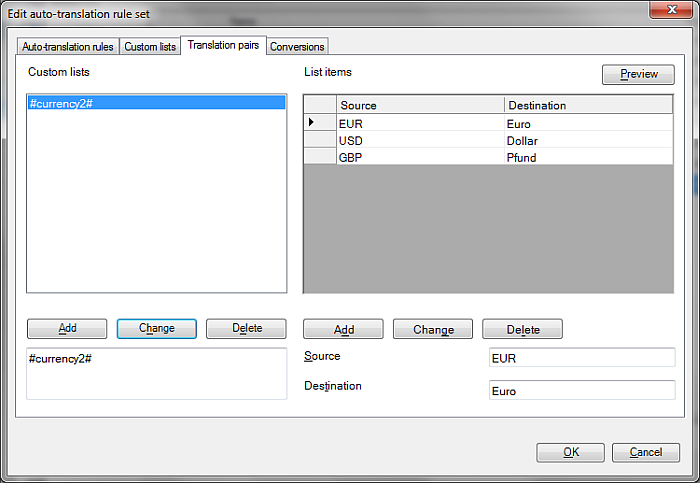
次の正規表現「'(#currency2#) (\d{1,}) million」を作成し、置換順序ルールは「$2 Millionen $1」にします。上記正規表現と置換順序ルールのプレビューは、以下のようになります: