Ergebnisse
Während Sie übersetzen, unterstützt memoQ Sie im Hintergrund. Dabei wird auf mehrere lokale und Online-Übersetzungsressourcen zugegriffen, darunter Translation Memorys, LiveDocs-Korpora, Termdatenbanken, Fragmentsuche, Auto-Übersetzungsregeln, Treffer auf Untersegmentebene usw. Die Ergebnisse aller Abfragen werden zusammengefasst im Bereich Ergebnisse des Übersetzungseditors angezeigt.
![]()
Wenn Sie in eine andere Zeile wechseln, beginnt memoQ mit der Abfrage der Übersetzungsressourcen. Die verschiedenen Ressourcen werden im Abschnitt zu den Ressourcen weiter unten beschrieben.
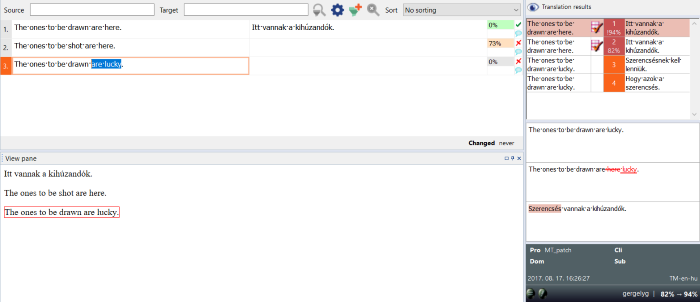
Im oberen Teil des Bereichs Ergebnisse wird eine Liste der Ergebnisse (Treffer) aus allen Übersetzungsressourcen angezeigt.
- In der linken Spalte finden Sie den ausgangssprachlichen Eintrag der Ressource.
- In der mittleren Spalte wird eine Nummer angezeigt.
- Die rechte Spalte enthält die zielsprachliche Entsprechung, falls vorhanden.
Enthält die Liste mehrere Ergebnisse, können Sie die aktuell markierte Auswahl mit den Tasten Strg+Pfeil-nach-oben und Strg+Pfeil-nach-unten verändern.
Die Hintergrundfarbe des jeweiligen Ergebnisses steht für die Ressource, in der das Ergebnis gefunden wurde:
Vorschläge aus Translation Memories und LiveDocs-Korpora werden rot angezeigt. Das aktuelle Ausgangssegment wird mit denen verglichen, die in den verschiedenen, dem Projekt hinzugefügten Translation Memories gespeichert sind. Der Vergleich erfolgt numerisch (nicht linguistisch). Er basiert auf der Ähnlichkeit von Buchstaben und Wörtern. Seien Sie daher nicht überrascht, wenn einige der als ähnlich angegebenen Treffer etwas ganz anderes bedeuten.
Es gibt drei Arten von roten Treffern (TM-Treffern):
-
 : Dieser Treffer stammt aus einem zweisprachigen Dokument in einem LiveDocs-Korpus.
: Dieser Treffer stammt aus einem zweisprachigen Dokument in einem LiveDocs-Korpus. -
 : Dieser Treffer stammt aus einem Alignment-Paar in einem LiveDocs-Korpus.
: Dieser Treffer stammt aus einem Alignment-Paar in einem LiveDocs-Korpus. -
 : Dieser Treffer stammt aus einem Translation Memory (TM).
: Dieser Treffer stammt aus einem Translation Memory (TM).TM-Treffer haben eine Trefferquote in Prozent: Diese Zahl zeigt die Ähnlichkeit zwischen dem Ausgangstext im Treffer und dem Ausgangstext im aktuellen Segment. Wenn der Treffer ein korrigierter Treffer ist, wird dies durch ein Ausrufezeichen angezeigt: !92%. Weitere Informationen erhalten Sie später in diesem Thema.
Wenn Sie einen Treffer aus einem Translation Memory oder einem LiveDocs-Korpus erhalten, weist memoQ dem Treffer einen Wert zu. Der Wert zeigt an, wie ähnlich das aktuelle Ausgangssegment dem Segment ist, das memoQ in der Ressource gefunden hat. Es gibt Kontexttreffer, exakte Treffer und Fuzzy-Treffer. Im Folgenden finden Sie eine Erklärung der jeweiligen Treffer:
- Kontexttreffer: Das Ausgangssegment im Fließtext ist vollkommen identisch mit dem in der Ressource. Außerdem sind das vorherige und das nächste Segment gleich (im Ausgangstext). In strukturierten (XML) Dokumenten oder Tabellen sind das Ausgangssegment und die sogenannte Kontext-ID in der Ressource dieselben. Wenn das Dokument Fließtext ist und eine Kontext-ID hat und es einen Treffer gibt, bei dem beide gleich sind, sprechen wir von einem Treffer mit doppeltem Kontext. Die Trefferquote eines einfachen Kontexttreffers beträgt 101 %. Die Trefferquote eines Treffers mit doppeltem Kontext beträgt 102 %.
- Exakter Treffer: Das Ausgangssegment ist im Dokument und in der Ressource absolut identisch, jedoch ist der Kontext unterschiedlich. Die Trefferquote ist 100 %.
Ein TC-Treffer (Track Changes, Änderungen nachverfolgen) ist ein besonderer exakter oder Kontexttreffer: Sie sehen diese Treffer, wenn das Ausgangsdokument nachverfolgte Änderungen enthält. Sie können diese nutzen, wenn Sie ein Dokument zuvor übersetzt haben und nun eine überarbeitete Version desselben Dokuments übersetzen sollen. Da die Änderungen alle markiert sind, weiß memoQ, wir der Text vor dem Bearbeiten lautete. memoQ sucht nach dem Text vor der Bearbeitung – als ob alle Änderungen abgelehnt wurden – und gibt, sofern vorhanden, Treffer zurück. Ein TC-Treffer ist ein exakter oder Kontexttreffer für die nicht bearbeitete Version des Ausgangssegments.
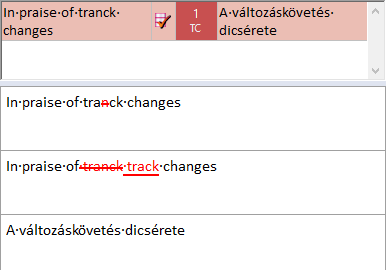
Ein TC-Treffer
- Hoher Fuzzy-Treffer: Die Trefferquote liegt zwischen 95 % und 99 %. Der Text ist im Dokument und in der Ressource identisch, es gibt jedoch Unterschiede bei den Zahlen, Satzzeichen, Tags oder Leerzeichen.
- Mittlerer Fuzzy-Treffer 1: Die Trefferquote liegt zwischen 85 % und 94 %. In Segmenten mit durchschnittlicher Länge (ungefähr zehn Wörter) gibt es in der Regel ein Wort, das in Dokument und Ressource nicht übereinstimmt.
- Mittlerer Fuzzy-Treffer 2: Die Trefferquote liegt zwischen 75 % und 84 %. In Segmenten mit durchschnittlicher Länge (ungefähr zehn Wörter) gibt es in der Regel zwei Wörter, die in Dokument und Ressource nicht übereinstimmen.
- Geringer Fuzzy-Treffer: Die Trefferquote liegt zwischen 50 % und 74 %. Der Unterschied ist in der Regel zu groß und der Treffer nicht brauchbar, außer das Ausgangssegment ist sehr kurz (weniger als sechs Wörter). Bei kurzen Segmenten können recht gute Treffer geringe Trefferquoten haben.
memoQ zeigt Lookup-Ergebnisse aus Translation Memories und LiveDocs-Korpora. Beim Übersetzen von XLIFF:doc-Dateien werden ggf. auch Treffer angezeigt, die mit übersetzten Zeilen gespeichert wurden. Die Übersetzungsergebnisse haben folgende Reihenfolge:
- Die höchste Trefferquote wird zuerst angezeigt.
- Haben mehrere Ergebnisse dieselbe Trefferquote, gilt diese Reihenfolge:
- Ergebnisse mit gespeicherter Trefferquote – nur XLIFF:doc-Dateien
- Ergebnisse aus dem Master-TM
- Ergebnisse aus LiveDocs-Korpora
- Ergebnisse aus dem Arbeits-TM
- Ergebnisse aus anderen (Referenz-)TMs
- Stammen aus einer dieser Kategorien mehrere Ergebnisse, wird das neueste zuerst angezeigt (d. h., das Ergebnis mit dem jüngsten Datum der Kategorie Geändert).
Vorschläge aus Termdatenbanken werden blau angezeigt. memoQ überprüft jedes Wort und jeden Ausdruck im Ausgangssegment und bietet eine Übersetzung an, wenn in einer der Termdatenbanken des Projekts ein Treffer hierfür gefunden wird.
Es gibt drei Arten von blauen Treffern (Termdatenbank-Treffern):
-
 : Der Treffer stammt aus einer gewöhnlichen Termdatenbank. In vielen Umgebungen gilt sie als autoritative Quelle.
: Der Treffer stammt aus einer gewöhnlichen Termdatenbank. In vielen Umgebungen gilt sie als autoritative Quelle. -
 : Der Treffer stammt aus einem akzeptierten Eintrag in einer Terminologieextraktionssitzung.
: Der Treffer stammt aus einem akzeptierten Eintrag in einer Terminologieextraktionssitzung. -
 : Der Treffer stammt von einem externen Terminologiedienst. Siehe "Hilfe" zum Bereich Terminologie-Plugins in Optionen.
: Der Treffer stammt von einem externen Terminologiedienst. Siehe "Hilfe" zum Bereich Terminologie-Plugins in Optionen.Wenn Sie einen Termdatenbank-Eintrag in der Trefferliste auswählen, werden die Details des Eintrags unterhalb der Trefferliste in einem formatierten Layout angezeigt:
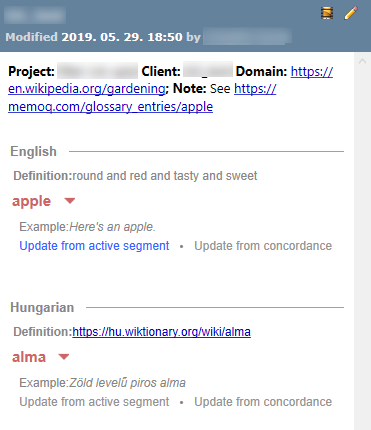
- Es werden nur Begriffe aus den Projektsprachen mit dem ausgangssprachlichen Begriff oben gefolgt von den zielsprachlichen Begriffen angezeigt.
- Nur die in der Liste Ergebnisse ausgewählte Benennung wird erweitert (Ausgangs- und Zielsprache). Alle sonstigen Benennungen zu dem Eintrag werden reduziert.
So erweitern bzw. reduzieren Sie die Informationen zu einem Begriff: Klicken Sie rechts von dem Begriff auf das nach unten oder nach rechts weisende Dreieck.
Wenn Sie in der oberen rechten Ecke auf das Symbol Eintrag bearbeiten ![]() klicken, wird das Fenster Eintrag in Termdatenbank bearbeiten geöffnet. In diesem Fenster können Sie Änderungen am Eintrag vornehmen.
klicken, wird das Fenster Eintrag in Termdatenbank bearbeiten geöffnet. In diesem Fenster können Sie Änderungen am Eintrag vornehmen.
So fügen Sie dem Begriffseintrag das aktuelle Segment als Beispiel hinzu: Klicken Sie unter der Sprache, die Sie aktualisieren möchten, auf Aus aktivem Segment aktualisieren.
So fügen Sie einen Konkordanz-Treffer als Beispiel in die Termdatenbank hinzu: Wählen Sie eine Phrase im Übersetzungseditor aus, drücken Sie Strg+K, wählen Sie den Konkordanztreffer, den Sie hinzufügen möchten, und klicken Sie unter der Sprache, die Sie aktualisieren möchten, auf Aus aktivem Segment aktualisieren.
So kopieren Sie Benennungsinformationen: Wählen Sie mit der Maus die Metadaten der Eintragsebene (im Bild oben, Projekt und Kunde), die Sprachebene (Definition) und die Benennungsebene (Beispiel). Drücken Sie Strg+C. Oder klicken Sie mit der rechten Maustaste auf eine beliebige Stelle in diesem Bereich und wählen Sie Auswahl kopieren, Benennungspaar-Info kopieren oder Eintrags-Info kopieren aus dem Menü.
Wenn das Projekt, an dem Sie arbeiten, eine QTerm-Termdatenbank hat, können Sie dieser ebenfalls Einträge hinzufügen und vorhandene Einträge bearbeiten (vorausgesetzt Sie verfügen über die erforderlichen Berechtigungen).
Treffer aus einer QTerm-Termdatenbank sehen so aus:
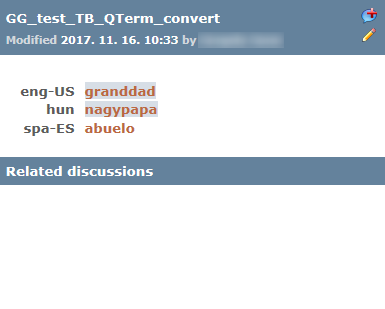
Sie können auch eine Diskussion für einen QTerm-Termdatenbank-Eintrag beginnen. Klicken Sie auf das Symbol Diskussion ![]() : Daraufhin wird das Dialogfeld Eine Diskussion beginnen angezeigt, in dem Sie eine Zusammenfassung, eine Problembeschreibung und einen Lösungsvorschlag eingeben können, womit eine Diskussion begonnen wird. Wenn bereits Diskussionen für den Eintrag vorhanden sind, werden sie unterhalb der Benennungen unter Dazugehörende Diskussionen aufgeführt. Sie können etwas zu einer Diskussion beitragen, indem Sie auf die Überschrift der Diskussion klicken: Daraufhin wird das Fenster Themen geöffnet.
: Daraufhin wird das Dialogfeld Eine Diskussion beginnen angezeigt, in dem Sie eine Zusammenfassung, eine Problembeschreibung und einen Lösungsvorschlag eingeben können, womit eine Diskussion begonnen wird. Wenn bereits Diskussionen für den Eintrag vorhanden sind, werden sie unterhalb der Benennungen unter Dazugehörende Diskussionen aufgeführt. Sie können etwas zu einer Diskussion beitragen, indem Sie auf die Überschrift der Diskussion klicken: Daraufhin wird das Fenster Themen geöffnet.
Hinweis: Sie können keine Diskussion hinzufügen oder sich an einer Diskussion beteiligen, wenn Diskussionen auf dem Server oder in qTerm deaktiviert sind oder wenn Sie Mitglied einer Gruppe sind, die aus Diskussionen ausgeschlossen ist.
Wenn viele Termdatenbank-Treffer vorliegen, werden sie sortiert und teilweise ausgeblendet, sodass Sie eine Liste mit den relevantesten Treffern erhalten. Standardmäßig werden die Treffer in der Reihenfolge angezeigt, in der sie im Ausgangstext vorkommen. Wenn für Teile des Ausgangstexts mehrere Treffer vorliegen, werden kürzere Treffer durch längere verborgen. (Wenn Sie auf das Auge oberhalb der Liste klicken, werden die kürzeren Treffer ebenfalls angezeigt.) Wenn für genau denselben ausgangssprachlichen Ausdruck mehrere Treffer vorliegen, werden die Treffer anhand der Priorität sowie der Details der Termdatenbank priorisiert: Wenn zwei Termdatenbank-Treffer aus derselben Termdatenbank kommen, aber ein Treffer mehr mit dem Projekt gemeinsam hat als der andere, hat der erste Vorrang. Weitere Informationen: Siehe "Hilfe" zum Fenster Trefferlisten-Filtereinstellungen.
Verbotene Benennungen werden schwarz angezeigt. Verbotene Benennungen stammen aus Termdatenbanken. Sie geben an, wie ein ausgangssprachliches Satzstück nicht übersetzt werden darf. Diese Treffer können nicht in die Übersetzung eingefügt werden, sie werden dem Übersetzer jedoch als Warnung angezeigt. Wenn Sie eine verbotene Benennung verwenden, erhalten Sie eine QA-Warnung.
Aus Fragmenten zusammengefügte Vorschläge werden lila angezeigt. memoQ versucht, die Übersetzung des Ausgangssegments aus dessen kleineren Teilen zusammenzusetzen, die entweder in den Translation Memories oder in den Termdatenbanken im Projekt gefunden werden.
So (de)aktivieren Sie fragmentierte Treffer: Wechseln Sie zum Fenster Optionen und klicken Sie links auf Erweiterte Nachschlage-Einstellungen. Klicken Sie dort auf die Registerkarte Einstellungen für Fragmenteinfügungen.
Treffer durch automatische Konkordanz (oder längsten Teilstring-Konkordanzvorschlag, LSC) werden hellorange angezeigt. memoQ versucht, die längsten Ausdrücke abzurufen, die über die Konkordanzsuche gefunden werden können, und auch deren jeweilige Entsprechung anzuzeigen. Wenn memoQ eine Übersetzung findet, wird diese in der Liste angezeigt. Sie können diese Übersetzung wie TM-Treffer in das Zielsegment einfügen.
Falls keine Übersetzung vorhanden ist: Durch Doppelklicken auf den Vorschlag wird das Fenster Konkordanz geöffnet, in dem Sie die Übersetzung suchen und diese einfügen können.
So (de)aktivieren Sie automatische Konkordanztreffer: Wechseln Sie zum Fenster Optionen und klicken Sie links auf Erweiterte Nachschlage-Einstellungen.
Wenn mindestens ein Plugin für die maschinelle Übersetzung eingerichtet ist und die Einstellung Ergebnisse auf der Registerkarte Einstellungen des Fensters Einstellungen für maschinelle Übersetzung bearbeiten nicht Aus ist, fragt memoQ alternativ einen maschinellen Übersetzungsdienst ab. Diese Vorschläge werden dunkelorange angezeigt. Sie können sie wie TM-Treffer in das Zielsegment einfügen.
Vorschläge aus der MT-Konkordanz (maschinell übersetzte Versionen des von Ihnen markierten Ausdrucks) sind gelb. Sie können diese Übersetzungen wie Termdatenbank-Treffer in das Zielsegment einfügen. Der bereits vorhandene Inhalt wird dadurch nicht überschrieben.
Nicht zu übersetzende Elemente werden grau angezeigt. Diese dürfen nicht übersetzt werden. Durch Verwendung dieser Vorschläge können Sie genau dasselbe Wort bzw. den Ausdruck in das Zielsegment einfügen.
Ergebnisse von Auto-Übersetzungsregeln werden grün angezeigt. Auto-Übersetzungsregeln sind Muster, nach denen memoQ im Ausgangssegment sucht. Einige sprachliche Elemente haben sehr viele Kombinationen und können deshalb zwar nicht aufgelistet, aber durch bestimmte Regeln beschrieben werden. Zu diesen Elementen gehören Datumsangaben, Maßeinheiten, Währungsangaben usw. Auto-Translatables werden grün angezeigt.
Wenn Sie im Bereich Ergebnisse einen LiveDocs-Treffer oder einen Translation-Memory-Treffer auswählen, werden in den drei Textfeldern darunter weitere Details angezeigt: In diesen Vergleichsfeldern wird Folgendes angezeigt:
- 1. Das aktuelle Ausgangssegment.
- 2. Der Ausgangstext des ausgewählten Vorschlags.
- 3. Der Zieltext des ausgewählten Vorschlags.
Sie können aus zwei Ansichten wählen. Wenn Sie Ihr erstes TM-Ergebnis in memoQ 8.5 erhalten, erscheint eine Benachrichtigung:
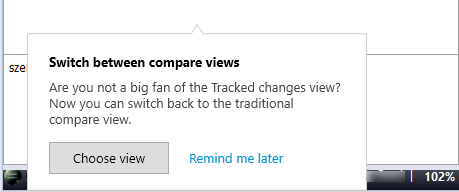
So treffen Sie Ihre Wahl jetzt: Klicken Sie auf Ansicht auswählen. Das Fenster Verschiedene Ansichten vergleichen wird geöffnet (siehe unten).
So treffen Sie Ihre Wahl später: Klicken Sie auf Später erinnern. memoQ verwendet weiterhin die Ansicht „Änderungen nachverfolgen“. Die gleiche Benachrichtigung erscheint später.
Wenn Sie eine Wahl getroffen haben und diese ändern möchten:
- Klicken Sie in der oberen linken Ecke von memoQ bei der Symbolleiste für den Schnellzugriff auf das Symbol Optionen
 .
. - Klicken Sie auf der linken Seite des Fensters Optionen in der Liste auf Verschiedenes.
- Wählen Sie auf der Registerkarte Lookup-Ergebnisse unter Vergleichsfelder die Option Ansicht „Änderungen nachverfolgen“ oder Traditionelle Vergleichsansicht.
So zeigen Sie die Unterschiede an: Klicken Sie auf den Link Verschiedene Ansichten vergleichen.
Oder: Doppelklicken Sie auf das Augensymbol ( ) über der Liste Ergebnisse. Wählen Sie im Fenster Einstellungen für Übersetzungsergebnisse unter Vergleichsfelder die Option Ansicht „Änderungen nachverfolgen“ oder Traditionelle Vergleichsansicht.
) über der Liste Ergebnisse. Wählen Sie im Fenster Einstellungen für Übersetzungsergebnisse unter Vergleichsfelder die Option Ansicht „Änderungen nachverfolgen“ oder Traditionelle Vergleichsansicht.
So zeigen Sie die Unterschiede an: Klicken Sie auf den Link Verschiedene Ansichten vergleichen.
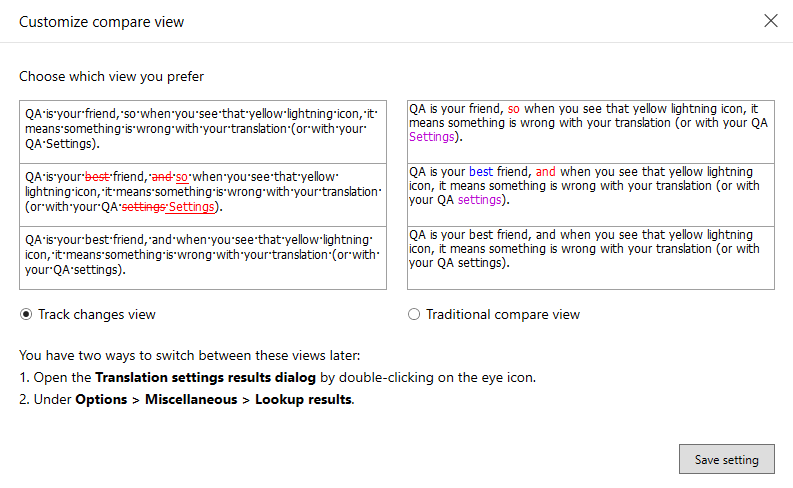
Ansicht „Änderungen nachverfolgen“:
Die Unterschiede zwischen den beiden Ausgangssegmenten erscheinen als Überarbeitungen – genau so, wie Überarbeitungen im Text erscheinen.
Die Änderungen werden nur im zweiten Feld markiert, so als würde der Translation Memory-Treffer zum aktuellen Ausgangssegment korrigiert werden. Das bedeutet Folgendes:
- Neue Satzteile, die sich im aktuellen Ausgangssegment befinden, erscheinen als eingefügt.
- Alte Satzteile im Treffer erscheinen (nur) als gelöscht.
Traditionelle Vergleichsansicht:
memoQ verwendet Farbcodes, um Unterschiede zwischen dem Übersetzungsergebnis und dem Ausgangstext hervorzuheben:
- Schwarz: Identische Abschnitte des zu übersetzenden Ausgangs- und Treffersegments.
- Rot: Unterschiede zwischen dem ersten und zweiten Vergleichsfeld. Untersuchen Sie die hervorgehobenen Teile und passen Sie den Vorschlag an den Ausgangstext an.
- Blau: In dem Vorschlag fehlt ein Wort. Fügen Sie es zur Übersetzung hinzu.
So ändern Sie die Farbe der Markups: Verwenden Sie den Tab Vergleichsfelder des Bereichs Optionen - Erscheinungsbild, um die Farben je nach Bedarf zu ändern.
Farben und Schriftarten können geändert werden: Im Tab Übersetzungsspalte des Bereichs Optionen - Erscheinungsbild können Sie alle Farben, Markierungen und Schriften ändern. Auf dieser Hilfeseite werden die normalen Einstellungen thematisiert. Wenn Sie diese ändern, entspricht diese Beschreibung möglicherweise nicht mehr Ihrer memoQ-Desktopanwendung.
Unter den drei Vergleichsfeldern werden Beschreibungsfelder zum ausgewählten Vorschlag angezeigt. Für Translation-Memory-Einträge werden folgende Informationen angezeigt:
- Fachgeb oder Fachgebiet
- Dom oder Domäne
- Proj oder Projekt-ID
- Kd oder der Kunde, für den das Translation Memory erstellt wurde
- Der Name des Translation Memory oder LiveDocs-Korpus, aus dem der Eintrag stammt
- Benutzername der Person, die den Eintrag erstellt oder zuletzt geändert hat
- Datum und Uhrzeit der Erstellung des Eintrags bzw. der letzten Eintragsänderung
- Wenn der Ausgangstext des Eintrags geändert wurde, ist außerdem das Wort Korrigiert hervorgehoben.
- Trefferquote des Vorschlags
- Die im Translation Memory gespeicherte Benutzerrolle: Wurde dieser Eintrag von einem Übersetzer, einem Überprüfer 1 oder einem Überprüfer 2 bestätigt?
Wenn ein Translation-Memory-Treffer in der Liste oben ausgewählt wird, sind am unteren Rand des Bereichs Ergebnisse zwei Gruppen mit kleinen Symbolen zu sehen:
![]()
Die zwei Symbole auf der linken Seite zeigen an, ob der ausgewählte Eintrag das Ergebnis eines automatischen Alignments ist  oder ob der Ausgangstext des TM-Eintrags geändert wurde, bevor die Übersetzung ins TM übernommen wurde
oder ob der Ausgangstext des TM-Eintrags geändert wurde, bevor die Übersetzung ins TM übernommen wurde  . Beispiel: Wenn ein Tippfehler im Ausgangstext im TM enthalten ist, können Sie im Bereich Ergebnisse mit der rechten Maustaste auf den TM-Eintrag klicken und Anzeigen/bearbeiten auswählen. Korrigieren Sie den Ausgangstext im TM-Eintrag und klicken Sie auf Übernehmen. Dies ist der Fall, wenn Sie in der Übersetzungsspalte wieder in dieses Segment gehen und das Symbol angezeigt wird.
. Beispiel: Wenn ein Tippfehler im Ausgangstext im TM enthalten ist, können Sie im Bereich Ergebnisse mit der rechten Maustaste auf den TM-Eintrag klicken und Anzeigen/bearbeiten auswählen. Korrigieren Sie den Ausgangstext im TM-Eintrag und klicken Sie auf Übernehmen. Dies ist der Fall, wenn Sie in der Übersetzungsspalte wieder in dieses Segment gehen und das Symbol angezeigt wird.
Die anderen sechs Symbole werden angezeigt, wenn der ausgewählte TM-Treffer ein 95–101-%-Treffer ist. Wenn diese Symbole aufleuchten, wird auf geringfügige Unterschiede zwischen dem aktuellen Ausgangssegment und dem Ausgangstext im Translation-Memory-Eintrag hingewiesen (z. B. darauf, dass das Ausgangssegment vorher fett formatiert war und jetzt kursiv formatiert ist):
-
 Das aktuelle Ausgangssegment enthält weniger oder mehr Leerzeichen als der TM-Eintrag.
Das aktuelle Ausgangssegment enthält weniger oder mehr Leerzeichen als der TM-Eintrag. -
 Unterschiedliche Interpunktion
Unterschiedliche Interpunktion -
 Unterschiede in der Groß-/Kleinschreibung
Unterschiede in der Groß-/Kleinschreibung -
 Abweichende Formatierung für fett/kursiv/unterstrichen
Abweichende Formatierung für fett/kursiv/unterstrichen -
 Abweichende Tags
Abweichende Tags -
 Abweichende Zahlen und Entitäten
Abweichende Zahlen und EntitätenWenn eines dieser Symbole farblich aufleuchtet, müssen Sie die jeweilige Abweichung manuell beheben. Wenn eines dieser Symbole leicht gräulich aufleuchtet, wurde die gefundene Abweichung bereits von memoQ behoben. Beispielsweise kann die Fettformatierung auf das gesamte Zielsegment angewendet werden oder Zahlen können durch die Zahlen im Ausgangstext ersetzt werden.
Für Benennungen werden die gleichen Informationen angezeigt – mit Ausnahme der Anzeige Alignment durchgeführt und der Trefferquote des Eintrags.
Damit Abweichungen für Zahlen und Entitäten aufleuchten, müssen Sie die TM-Standardeinstellungen ändern. Wählen Sie von der Projektzentrale Einstellungen aus, und klicken Sie auf die Registerkarte TM-Einstellungen. Klonen Sie die Standardeinstellungen. Klicken Sie anschließend auf Bearbeiten und deaktivieren Sie das Kontrollkästchen Fuzzy-Treffer und Inline-Tags angleichen. Von jetzt an werden Zahlen nicht mehr angeglichen, sondern das Symbol leuchtet auf.
Oben im Bereich Ergebnisse zeigt das Symbol mit dem geschlossenen Auge  an, dass einige Vorschläge aus Translation Memories, LiveDocs-Korpora und Termdatenbanken ausgeblendet sind. So würde memoQ standardmäßig aussehen.
an, dass einige Vorschläge aus Translation Memories, LiveDocs-Korpora und Termdatenbanken ausgeblendet sind. So würde memoQ standardmäßig aussehen.
Klicken Sie auf dieses Symbol, um alle Vorschläge anzuzeigen. Aus dem Symbol wird ein Symbol mit einem offenen Auge . Alternativ können Sie auch Strg+Umschalt+D drücken.
Informationen zum Überprüfen (und Auswählen) ausgeblendeter Vorschläge finden Sie in der Hilfe zum Fenster Trefferlisten-Filtereinstellungen.
Wenn für ein langes Ausgangssegment kein Treffer aus den Translation Memories vorhanden ist, kann memoQ in den dem Projekt zugewiesenen Translation Memories und Termdatenbanken nach kleineren Teilen dieses Segments suchen. Wenn in den Translation Memories oder Termdatenbanken kürzere Segmente gespeichert sind (zusammen mit ihren Übersetzungen), kann memoQ nach kleineren Teilen (Fragmenten) des langen Ausgangssegments suchen und deren Übersetzungen im Zielsegment einfügen. Dies geschieht automatisch: Wenn Sie zu einem Segment gehen und die Translation Memories und Termdatenbanken durchsucht werden, werden die "Patchwork"-Treffer – oder Fragmenttreffer –, sofern welche vorhanden sind, automatisch in der Trefferliste angezeigt.
Die Fragmenttreffer werden in der Trefferliste standardmäßig lilafarben angezeigt. Sie können zu diesen navigieren, indem Sie Strg+Pfeil-nach-unten drücken. Drücken Sie dann Strg+Leertaste zum Einfügen. Alternativ können Sie auf den lilafarbenen Block des Treffers in der Liste doppelklicken oder die Strg-Taste gedrückt halten und die Zahl drücken (wenn eine vorhanden ist – die ersten 9 Treffer sind nummeriert).
Angenommen, Sie haben zuvor die folgenden Segmente übersetzt:

Außerdem ist in der Termdatenbank der folgende Eintrag vorhanden:
Dann müssen Sie das folgende Segment in einem anderen Dokument übersetzen:

Zum Eintragen der Übersetzung für das obige Segment setzen Sie einfach den Textcursor in das Zielsegment. memoQ findet automatisch die zwei kleineren Segmente im Translation Memory und den Termdatenbank-Eintrag für die Benennung am Ende des Segments. Die zusammengefügte Übersetzung wird automatisch in der Trefferliste angezeigt:
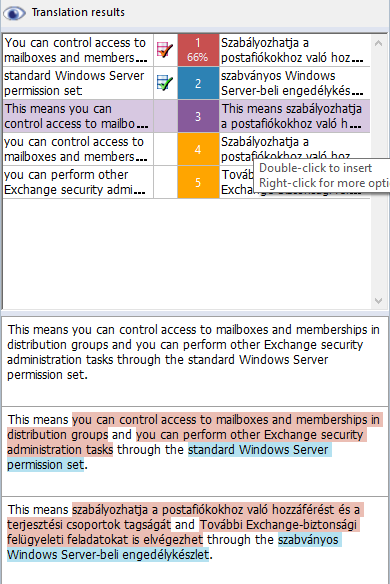
Wenn Sie die vorgeschlagene Übersetzung einfügen möchten, drücken Sie Strg+3 – oder verwenden Sie die Strg-Taste und die Pfeiltasten, um zu dem Vorschlag zu navigieren, und drücken Sie dann Strg+Leertaste.
Sie können das Zusammenfügen von Fragmenten auch während der Vorübersetzung verwenden. (Wählen Sie auf der Registerkarte Vorbereitung des Menübands die Option Vorübersetzen aus.) Aktivieren Sie das Kontrollkästchen Fragmenteinfügung ausführen. Klicken Sie daneben auf den Link Einstellungen.
Das Fenster Einstellungen für Fragmenteinfügungen wird angezeigt:
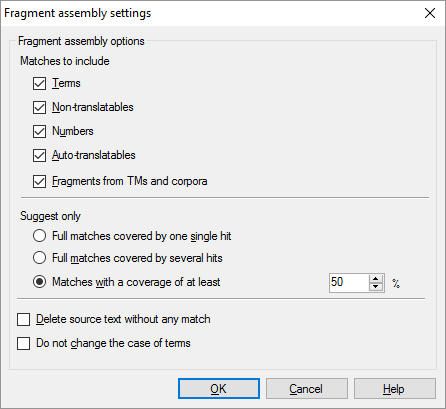
Wählen Sie Ihre Einstellungen und klicken Sie auf OK. Klicken Sie im Fenster Vorübersetzen und Statistiken wieder auf OK. Die Vorübersetzung wird ausgeführt.
Anschließend versucht memoQ, Übersetzungen aus Fragmenten zusammenzufügen, wenn für ein bestimmtes Segment kein Translation-Memory-Treffer vorhanden ist.
Weitere Informationen: siehe "Hilfe" zum Fenster Einstellungen für Fragmenteinfügungen.
Beim Zusammensetzen einer Übersetzung aus Fragmenten wird in memoQ immer ab dem Anfang des Segments nach dem längsten Fragment gesucht. Wenn ein Fragment gefunden wird, wird ab der Stelle, wo das vorherige Fragment endete, wieder nach dem längsten Fragment gesucht. Wird ab dem Anfang des Segments (oder der Stelle, an der mit der Suche begonnen wird) kein Fragment gefunden, wird ab dem nächsten Wort nach einem Fragment gesucht. Wenn die nachfolgenden Suchen ebenfalls erfolglos sind, wird von einem Wort zum nächsten gegangen, bis ein Fragment gefunden wird oder das Ende des Segments erreicht ist.
In memoQ werden bei der Fragmentsuche die Translation Memories und Termdatenbanken im Projekt durchsucht. Beim Durchsuchen von Translation Memories werden in memoQ nur exakte Translation-Memory-Treffer verwendet. Es wird nicht versucht, in den Translation Memories annähernd gleiche Treffer (Fuzzy-Treffer) für die Fragmente zu finden. In memoQ wird beim Durchsuchen von Termdatenbanken die Präfix-Übereinstimmung nicht verwendet.
Beim Zusammensetzen einer Übersetzung aus Fragmenten wird immer das gesamte Ausgangssegment abgedeckt. Bei der Suche nach Fragmenten wird immer Wort für Wort vorgegangen. Wenn ein Wort nicht durch einen Fragmenttreffer abgedeckt ist – d. h. in memoQ musste ein Wort übersprungen und die Suche ab dem nächsten fortgesetzt werden –, wird die Lücke ausgefüllt, indem das Wort in der Ausgangssprache eingefügt wird. Siehe das Beispiel oben: Im Vorschlag ist noch englischer Text vorhanden. Dies liegt daran, dass keine TM- oder TD-Einträge gefunden wurden, die diese Wörter abdecken.
Im Allgemeinen werden durch Fragmenteinfügungen Benennungen aus dem Ausgangstext ersetzt. Wenn jedoch zwei oder mehr Termdatenbank-Treffer für ein und dieselbe ausgangssprachliche Benennung vorliegen, muss ein Treffer ausgewählt werden. Aus diesem Grund wird den Termdatenbank-Treffern ein Trefferwert zugewiesen und der Treffer mit dem höchsten Wert wird übernommen.
Natürlich ist der längere Treffer immer stärker, aber wenn die zwei oder mehr Treffer gleich lang sind, müssen sie genauer analysiert werden.
Zum einen können Sie Prioritäten für Termdatenbanken festlegen: Wenn eine Benennung aus einer wichtigeren Termdatenbank zurückgegeben wird, hat sie Vorrang.
Zum anderen muss dennoch eine Entscheidung getroffen werden, wenn alle Benennungen aus ein und derselben Termdatenbank stammen.
Dieser Vorgang kann verwendet werden, wenn die Priorisierung aktiviert ist. Sie können die Priorisierung aktivieren, indem Sie das Dialogfeld Trefferlisten-Filtereinstellungen öffnen und das Kontrollkästchen Termdatenbank-Treffer primär nach Rang und Meta-Daten ordnen aktivieren.
Dann wird überprüft, wie viel ein Termdatenbank-Treffer mit dem Projekt gemeinsam hat. Wenn ein Termdatenbank-Treffer zwei Angaben aufweist, die zum Projekt passen, und ein anderer Treffer drei passende Angaben aufweist, hat der Treffer mit drei Angaben Vorrang.
Wenn beide Termdatenbank-Treffer gleich viele Angaben aufweisen, die zum Projekt passen, wird überprüft, wie wichtig diese Angaben sind. Für die Wichtigkeit gilt folgende Reihenfolge (angefangen bei den wichtigsten bis hin zu den am wenigsten wichtigen Angaben):
- Projektname
- Kundenname
- Fachgebiet
- Domäne
Beispiel: Wenn für einen Termdatenbank-Treffer das Feld für den Kundennamen passt und für einen anderen das Fachgebiet identisch ist, hat der erste Treffer Vorrang, weil der Kundenname wichtiger als das Fachgebiet ist.
Wenn eine Benennung im Text gefunden wird, wird sie in der Vorschlagsliste angezeigt. Im Beispiel unten kommen jedoch sowohl ein Translation-Memory-Treffer als auch ein Termdatenbank-Treffer aus den Ressourcen (d. h. dem Translation Memory und der Termdatenbank) und werden von memoQ kombiniert:
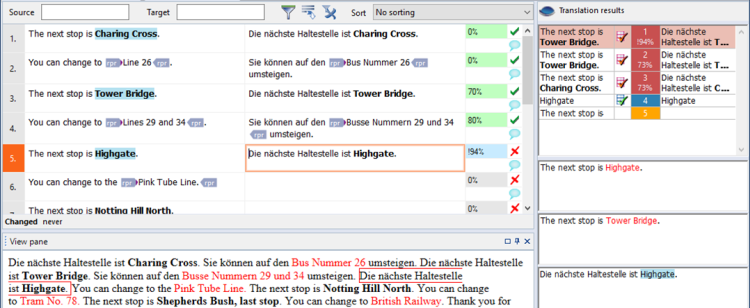
Beachten Sie, dass memoQ eine perfekte Übersetzung eingefügt hat. Wie kann das sein, wenn der Treffer aus dem Translation Memory doch "The next stop is Tower Bridge" lautete?
Der Unterschied zwischen dem Ausgangstext und dem Treffer aus dem Translation Memory war der Name der Station: "Highgate" im Ausgangstext und "Tower Bridge" in der Übersetzung. Beide Namen befanden sich aber auch in der Termdatenbank. memoQ fand die Übersetzung von "Tower Bridge" in der gespeicherten Übersetzung und da die Übersetzung von "Highgate" bereits bekannt war, konnte der alte Name problemlos durch den neuen ersetzt werden.
In diesem Fall sprechen wir davon, dass memoQ die Übersetzung korrigiert. memoQ weist der korrigierten Übersetzung auch einen höheren Wert zu, kennzeichnet sie jedoch mit einem Ausrufezeichen (! – siehe das blaue Statusfeld neben dem Segment).
Zum Aktivieren dieser Funktion öffnen Sie das Fenster Optionen. Wählen Sie Verschiedenes aus. Klicken Sie auf die Registerkarte Lookup-Ergebnisse. Aktivieren Sie das Kontrollkästchen Fuzzy-TM-Treffer korrigieren.
Weitere Informationen: siehe "Hilfe" zum Fenster Optionen.
memoQ zeigt einen korrigierten Treffer mit einem Ausrufezeichen vor der Trefferquote an: !93%. Im unteren Teil des Bereichs Ergebnisse werden zwei Trefferquoten angezeigt: 73%->93%. Das bedeutet, dass der Treffer ursprünglich einen Wert von 73 % hatte, der von memoQ aber auf 93 % verbessert wurde.
Zudem wird die Formatierung des Ausgangssegments verwendet. Wenn Ihre Benennung fett formatiert ist, wird die zielsprachliche Benennung ebenfalls mit Fettformatierung eingefügt.
Beispiel 1:
Englischer Ausgangstext: Chocolate was the best-selling commodity in the last summer.
Ressourcen:
Der obige Satz wurde in Ihrem TM mit der entsprechenden deutschen Übersetzung gespeichert: Schokolade war die meistverkaufte Ware im letzten Sommer.
Ihre Termdatenbank enthält diese Benennung: ice cream = Eiscreme.
Jetzt erhalten Sie einen Ausgangstext, der diesen englischen Satz enthält:
Ice cream was the best-selling commodity in the last summer.
Deutscher Zieltext: Eiscreme war die meistverkaufte Ware im letzten Sommer.
Beispiel 2:
Englischer Ausgangstext: Chocolate was the best-selling commodity in the last hot summer.
Ressourcen:
Der obige Satz wurde in Ihrem TM mit der entsprechenden deutschen Übersetzung gespeichert: Schokolade war die meistverkaufte Ware im letzten heißen Sommer.
Ihre Termdatenbank enthält diese Benennungen: ice cream = Eiscreme und cold = kalten.
Jetzt erhalten Sie einen Ausgangstext, der diesen englischen Satz enthält:
Ice cream was the best-selling commodity in the last cold summer.
Deutscher Zieltext: Eiscreme war die meistverkaufte Ware im letzten kalten Sommer.
memoQ sucht nach allen Unterschieden in Fuzzy-Treffern. Theoretisch können also alle korrigiert werden. In der Praxis werden jedoch immer 1 oder 2 Unterschiede korrigiert. Dies geschieht, weil MatchPatch hohe Trefferraten benötigt und wenige Treffer in den Referenzmaterialien gut genug sind. Auch die Korrektur mit maschineller Übersetzung hat einige Einschränkungen:
- memoQ sucht Phrasen in nur einem MT-Dienst, und das nur einmal, und nimmt nur die erste vorgeschlagene Übersetzung. Wenn sich diese Übersetzung vom Fuzzy-Treffer im Translation Memory unterscheidet, kann memoQ diese Phrase nicht korrigieren.
- memoQ sucht keine Wörter mit 3 oder weniger Buchstaben.
In Abhängigkeit von Ihrer Zielsprache müssen Sie jedoch trotzdem noch die Endung oder Wortform anpassen. In der Tabelle werden korrigierte Treffer im Unterschied zu "normalen" vorübersetzten Segmenten hellblau hervorgehoben.
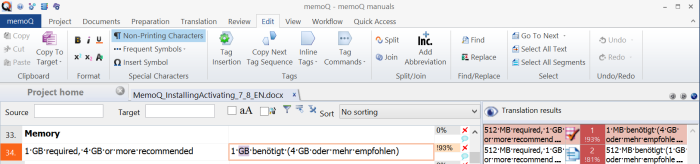
Keine Korrektur bei der Vorübersetzung: Während der Vorübersetzung werden keine Treffer in memoQ korrigiert.
Keine Korrektur von Zahlen oder Tags: Dies ist die Aufgabe des Translation Memory. MatchPatch funktioniert nur mit Unterschieden im Text.
Korrigierte Treffer erhalten einen Abzug: Auch wenn ein korrigierter Treffer perfekt (genau) ist, weist memoQ einen Abzug zu. Die Trefferquote eines korrigierten Fuzzy-Treffers ist nie höher als 94 %.
Wenn Sie Zugriff auf einen maschinellen Übersetzungsdienst haben, können Sie damit auch Fuzzy-Treffer aus den TMs korrigieren.
- Öffnen Sie das Fenster Einstellungen für maschinelle Übersetzung bearbeiten.
- Klicken Sie bei Bedarf in der Liste auf die Zeile des MT-Dienstes und konfigurieren Sie das Plugin.
- Wählen Sie auf der Registerkarte Einstellungen in der Dropdown-ListeMatchPatch einen Dienst aus.
- Klicken Sie auf OK.
Wenn ein Fuzzy-Treffer von MatchPatch nicht mithilfe der Ergebnisse aus Termdatenbanken oder TMs korrigiert werden kann, wird der ausgewählte MT-Dienst für die Korrektur verwendet.