Translation memory properties
In the Translation memory properties window, you can change the name and the descriptive details of the translation memory, make it read-only, save document names in new entries (or stop saving them). You can also check the number of entries or the path where the files of the translation memory are. In addition, you can add, remove, or change custom fields.
You cannot change here the languages of the translation memory or how it stores context.
How to get here
-
In Project home, choose Translation memories

OR
From an online project: As a project manager, you can open an online project for management. In the memoQ online project window, choose Translation memories
.OR
Open the Resource console
 , and choose Translation memories
, and choose Translation memories  .
. -
Right-click the name of the translation memory you need to change. From the menu, choose Properties.
-
The Translation memory properties window opens.
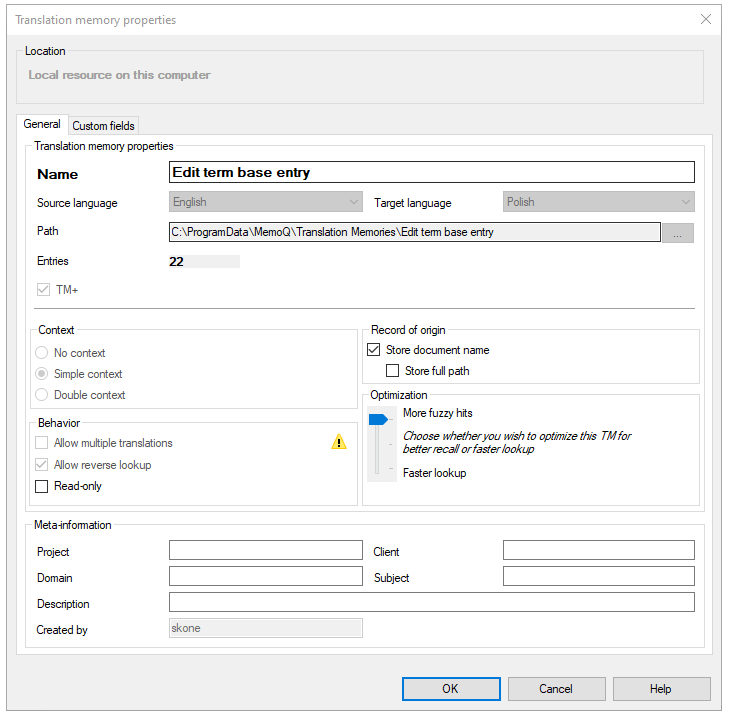
If you open the Translation memory properties window from the translation memory editor, it is read-only and cannot change the values.
What can you do?
-
Check the languages in the Source language and the Target language boxes.
-
Check the folder of the translation memory in the Path box.
To open the folder in Windows: Select the contents of the Path box, and copy it to the clipboard by pressing Ctrl+C. Press the Windows key, and paste the path by pressing Ctrl+V. Press Enter. The folder opens in a Windows folder window.
-
Check the number of entries in the translation memory in the Entries box.
To see if a new translation memory is a TM+: Under Translation memory properties, look at the TM+ checkbox.
In a TM+, you can either:
-
Store Context - The translation memory will give you a context match if both the segment and its context are the same in the translation memory. To return context matches, a translation memory needs to store the context.
OR
-
Allow multiple translations - This option is not recommended, unless you are importing a translation memory from a different translation tool, and there are several translations in the file you import. When two translations are different, in most cases, the context is also different. If you use context in a translation memory, there is no use for multiple translations.
You cannot change how the translation memory handles context, but you can learn about the setup.
The translation memory will give you a context match if both the segment and its context are the same in the translation memory. To return context matches, a translation memory needs to store the context.
For example, if you need to reconstruct the translation of a document from a translation memory, you need the context matches. They are also useful if you need to update the translation for a new version of the source document, and there is little difference between the two versions.
memoQ has two types of context match:
Simple-context match: 101% match rate
- Text flow context - when the source document contains running text the context is the previous and the next segment.
- ID-based context - when the source document is a table or a structured document where each entry has, or can have, an identifier. In this case, the context is the identifier, and memoQ returns a context match if both the segment and the identifier are the same in the translation memory.
Double-context match: 102% match rate
-
Double context is possible in documents that have running text and identifiers at the same time. In this case, memoQ can check both in the translation memory.
To learn more about match rates: Read topic about match rates from translation memories and LiveDocs corpora.
Translation memory with no context:
You can also create a translation memory that does not store any context. This is not recommended unless you plan to use the translation memory for reference only and to import translation memory files from a different translation tool. If a translation memory does not store any context, do not make it the working or the master translation memory in a project. When you confirm segments, memoQ will always try to save the context. If you confirm segments into a no-context translation memory, you will lose data.
You cannot change this setting after the translation memory was created.
Do not use multiple translations: memoQ can store several translations for the same source-language segment. This option is not recommended, unless you are importing a translation memory from a different translation tool, and there are several translations in the file you import. When two translations are different, in most cases, the context is also different. If you use context in a translation memory, there is no use for multiple translations. Make sure that the Allow multiple translations checkbox is cleared.
When you confirm a segment in the translation editor, memoQ will save the name of the document together with the segment and its translation. This may be interesting when you are reviewing translations - or you need to decide how much to trust the translation.
If you do not want the document names in the translation memory: Clear the Store document name checkbox.
You can turn it back on: To do that, open the Properties window for the translation memory.
To protect the translation memory against accidental changes: Select the Read-only checkbox. memoQ won't let anyone make changes to it - until you clear the Read-only checkbox in the Properties window for the translation memory.
Do this on the Custom fields tab.
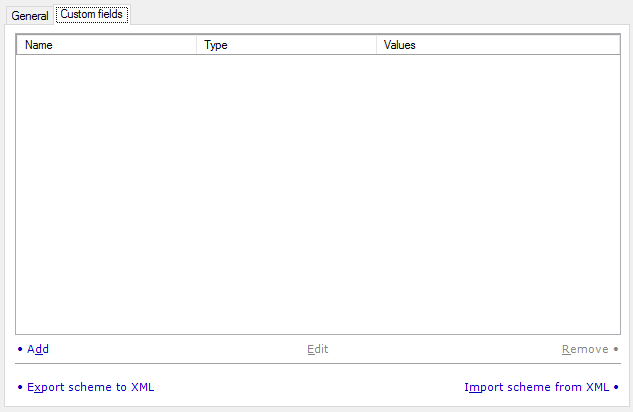
You can add custom fields to the new translation memory. Each translation unit can have metadata in the regular fields (that exist in every translation memory) and the custom fields (that you add here). Every translation memory can have different custom fields.
Maximum 20 custom fields: A translation memory cannot contain more than 20 custom fields.
This list will already contain some custom fields if:
- custom fields are already defined in the Default TM scheme tab of the Miscellaneous category of the Options window, or
- you got here by cloning a translation memory (in the Resource console or the Translation memories pane of Project home) that has custom fields.
The following options are available:
- Add: Click this link to add a new custom field to the default TM scheme. The Custom field properties window opens. Specify the name and the type of the new custom field. If you choose Picklist (single) or Picklist (multiple) as the type, you need to list the possible values for the field.
- Edit: Click this link to change the type of the selected custom field. The Custom field properties window opens. You cannot change the name: the Name box will be grayed out. You can change the type of the field. If you choose Picklist (single) or Picklist (multiple) as the type, you need to list the possible values for the field.
- Remove: Click this link to remove the selected custom field from the list. This only works before you click the OK button.
- Export scheme to XML: Click this link to export the list of custom fields in an XML file that can be used when creating new translation memories, both on this computer and on other computers running memoQ.
- Import scheme from XML: Click this link to populate the list of custom fields that were saved to an XML file earlier from another copy of memoQ.
Cannot change or remove custom fields after the TM is saved: When you click OK, memoQ saves the custom fields into the translation memory. After that, you can only change picklist values. To remove a custom field after saving: Make sure that no translation unit is using that field. Export the translation memory into a TMX file. Create a new translation memory. Import the TMX file into the new TM - the unwanted custom field will not be there.
When you finish
To save changes to the translation memory: Click OK.
To return to the Resource Console or to Project home without saving changes: Click Cancel.